tags : Containers , Linux
Intro
- A namespace(NS) “wraps” some global resource to provide isolation of that resource.
- At any time, a system can have multiple instances of NS
- Processes can belong to namespace instances
- A process cannot be part of multiple NS of same type instances at the same time. Eg. P1 cannot belong to UTSNS1 and UTSNS2
- A process can be part of multiple different NS type instances at the same time. Eg. P1 can belong to UTSNS1, IPCNS2, TIMENS1, CGROUPNS22
- Processes inside a NS are unaware of what’s happening in other NS in the system
- Each non user NS is owned by some user NS instance.
Usage
- It is possible to use individual NS on their own
- But often, NS depend on each other so you might end up using multiple NS. Eg. PID, IPC or cgroups NS need mount NS.
Privilege and Permission for creating NS
- No privilege needed for
UserNS - For all other NS, you need:
CAP_SYS_ADMINcapability
Related System calls
fork(): The new process created resides in the same NS.clone(): Create new (child) process in new NS(s)unshare(): Create new NS(s) and move caller(process/thread) into it/them. (i.e disassociate itself)setns(): Move calling process/thread into another (existing) NS.- There are analogous commands such as
unshareandnsenter
APIs and other interfaces
- Each process has symlinks in
/proc/PID/ns/<ns_type>/ - Namespaces are implemented by a filesystem internal to the kernel. This symlink points to the
inodenumber specific to theNS. - This
inodenumber is unique for aNSinstance lsns -Tcommand
Types (8)
Mount CLONE_NEWNS (2002)
- All it does is provide a set of mount points
- There can be many NS that mount the same FS
- Two different mount NS happen to mount the same FS, changes in one will be reflected in another.
- FS is not being isolated
CLONE_NEWNSinstead ofCLONE_NEWMNTbecause back in the day when it was being implemented nobody thought there will be other namespace types- Isolation of
set of mountpointsas seen by processes. Processes in different Mount NS(s) see different filesystem trees mountandumounthad to be refactored to only affect processes in same mount NS.
UTS CLONE_NEWUTS (2006)
- Hostname and NIS domain name
- See manpage
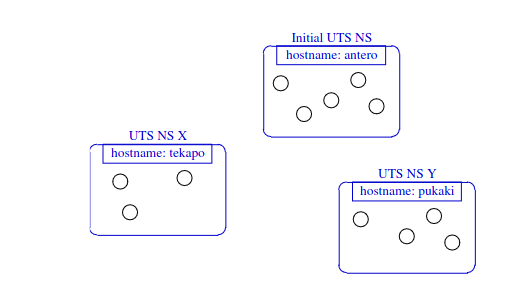 In the picture, changes to
In the picture, changes to hostname in UTS NS X won’t be visible to other UTS NS (es)
IPC CLONE_NEWIPC (2006)
- System V IPC (Message queues, semaphore, and shared memory)
- POSIX message queues
- Process in IPC NS instance share set of IPC objects. Can’t see objects in other IPC NS.
PID CLONE_NEWPID (2008)
- Isolate Process ID number space. i.e Processes in different NS can have same PID
- Max nesting depth: 32
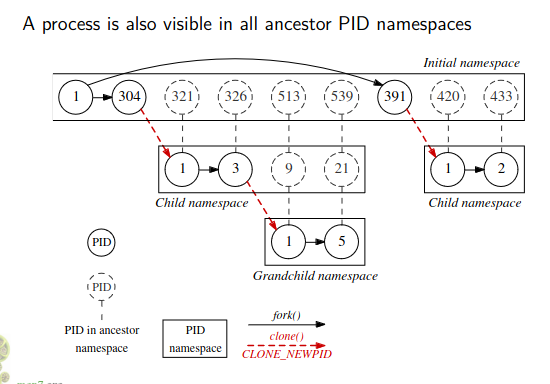 Picture clearly shows that PIDs just don’t get created inside the container, it’ll have ancestors back to the initial namespace. But the parent will not be visiable from the child process using things like
Picture clearly shows that PIDs just don’t get created inside the container, it’ll have ancestors back to the initial namespace. But the parent will not be visiable from the child process using things like getppid()
htop on host shows container processes (PID namespace)?
from the manpage
A process is visible to other processes in its PID namespace, and to the processes in each direct ancestor PID namespace going back to the root PID namespace. In this context, “visible” means that one process can be the target of operations by another process using system calls that specify a process ID. Conversely, the processes in a child PID namespace can’t see processes in the parent and further removed ancestor namespaces.
- This is expected, you can hide them with Shift+O if you want
- virtual machine - Docker Processes Shown on Host Process List - Stack Overflow
- But usually containers will run in their own pid namespace will not have visibility into the host. We can run it in host namespace by passing flags then it’ll also see host processes inside the container etc.
Network CLONE_NEWNET (2009)
- Useful for providing containers with their own virtual network and network device (
veth) - Useful when you want to place a process in a NS with no network device
- Isolates whole bunch of network resources like
- IP addresses
- IP routing tables
/proc/net,/sys/class/net- netfilter FW rules
socket port no space- unix domain sockets
- More info
User CLONE_NEWUSER (2013)
One of the most complex NS implementations. User NS are hierarchical like PID NS
- Relationship w Parent user NS determine capabilities
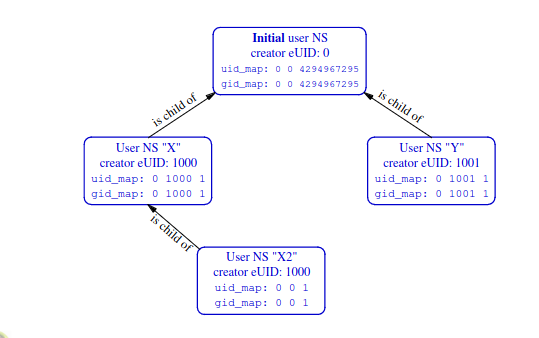
- When a new user NS is created, first process inside NS has all capabilities
- Each non user NS is owned by some user NS instance.🌟
- When creating new non user NS, kernel marks non user NS as owned by user NS of the process creating the new non user NS
- Process operating on non user NS resources; Permission check done to the process’s caps in user NS that owns the non user NS
What are uid_map and gid_map
- There are rules about what values can be written to the
uid_mapandgid_mapfiles. To guide what they permit there are standard/etc/subuidand/etc/subgidfiles(which define which ranges of (outer namespace) UIDs and GIDs) - This is one of the first steps to do when creating a user NS.
- One could use
newuidmapto set these. - Done by writing to
/proc/PID/uid_mapand/proc/PID/gid_map
id-inside-ns id-outside-ns length
id-inside-ns + length = range of ids inside ns to be mapped
id-outside-ns = start of corresponding mapped range outside nsExamples:
0 1000 1 # root mapping
# 1 User : 0(ns) = 1000(outer)
0 1000 10
# 10 User : 0(ns) = 1000(outer), 1(ns) = 1001(outer),...9(ns) = 1009(outer)What is eUID?
When running on set-uid.
eUID: Effective UID is the user you changed toUID: The original user.
What happens when unshare -Ur -u <prog>?
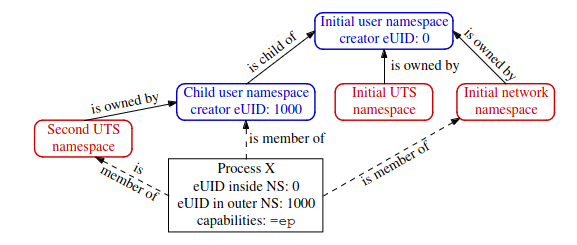
=ep : All sets of capabilities
In this case,
Xis part of newUTSandUserNSXis part of old/initialIPC,Network,Time,cgroups, etc.- With the capabilities(
=ep)XhasX’s capabilities will only work in the NS(s) owned by the new user NS.Xis a member of the new user NS.- If
Xtries to changehostname, it’ll be able to. (CAP_SYS_ADMIN) - If
Xtries to bind a reserved socket port, it’ll not be able to. (CAP_NET_BIND_SERVICE)
- See
ioctl_ns
Cgroup CLONE_NEWCGROUP (2016)
- The cgroup ns only provides an isolated view of the cgroup tree to the isolated process so that any system level info is not leaked to it.
- All the actual grouping and resource management stuff done by core and controllers of cgroups
Time CLONE_NEWTIME (2020)
Boot and monotonic clocks