tags : OCI Ecosystem, Linux
Basics
There is no such thing as a container, but only as much as containing is a thing you do.
Linux containers
Modern containers are a mix of cgroups, namespaces, pivot_root (like chroot but more appropriate for containers), and seccomp. But this is just one possible implementation. There are also, certainly, other ways of implementing containers.
- Docker : Docker is a reference implementation for the concept of containers. It provided a simple, practical way to bundle applications and their dependencies in a relatively standardized way. Docker’s main innovation was the layering system
- LXC & LXD
- Other linux container solutions: Some implementations (e.g. firecracker-containerd) also use SELinux and CPU virtualization support.
Containers without namespaces
- One could ship application components as containers, but have them run as VMs, eg. firecracker-containerd
- Dockers for Windows and Macs do not even use “cgroups” and “namespaces” because these technologies are not available on these stacks, it resorts to plain old VMs.
Comparison w Solaris Zones and BSD Jails
- Ramblings from Jessie
- Solaris Zones, BSD Jails are first class concepts.
- Containers on the other hand are not real things.
- “Containers are less isolated than Jails/Zones but allow for a flexibility and control that is not possible with Jails, Zones, or VMs. And THAT IS A FEATURE.”
- Containers are not sandboxing but we can attempt to sandbox it and good attempts have been made. One example is gvisor
Images
What is it?
- a
.tar - We basically bundle the application together w deps and just enough of a Linux root filesystem to run it.
- Usually updated in version compared to updated in place
Implementations
- Using Dockerfile
- Using nix dockerTools (NixOS)
TODO Concept of user during image creation
Use of USER
- It’s reasonable to build the application as root and switch only to a non-root
USERat the very end of the Dockerfile usingUSER.- Later at runtime,
USERcan always be overridden by the--usercli flag.
- Later at runtime,
- docker - Install all packages in root and switch to a non-root user or use `gosu` or `sudo` directly in a dockerfile? - Stack Overflow
- While you can just make up UIDs when passing
--user, usually you’d want that user to be actually present inside the container- In those case you’d use
useradd/groupapplike normal linux installation - the process is split into two operations, even with the standard Docker tools, i.e.
- first you create the new user so that you can configure the files to be owned by it (
useraddphase) - and then you have to configure the containers produced by this image to be run as that particular user by default. (
USER/gosuetc.) - You can do it in multi-staged builds (even with nix dockerTools but I don’t see it as strictly necessary)
- first you create the new user so that you can configure the files to be owned by it (
- In those case you’d use
Use of gosu
gosu is only for de-elevating from root to a normal user. It is normally used as the last step of an entrypoint script to run the actual service as a non-root user (ie exec gosu nobody:nobody redis-server). This is useful when you need to do a few setup steps that require root (like chown a volume directory) and yet not have the service running as root. If you do not need any root access before the service starts, then USER nobody:nobody in the Dockerfile (or —user nobody:nobody on docker run) will accomplish the same thing (gosu uses the same function from runc that docker uses).
- Gosu and user ? · Issue #55 · tianon/gosu · GitHub
- dockerfile - Docker using gosu vs USER - Stack Overflow
- gosu and rootless: https://github.com/containers/podman/issues/6816
- My heuristic: reachout for
gosuonly if you need to do priviledged operations in the entrypoint file, otherwise just useUSER
Filesystem and storage
Overlayfs
- Containers usually don’t have a persistent root filesystem
- overlayfs is used to create a temporary layer on top of the container image.
- This is thrown away when the container is stopped.
Block devices
- Docker and containerd use overlay filesystems instead of loopback devices.
- CSI might mount it as loopback
Mounts
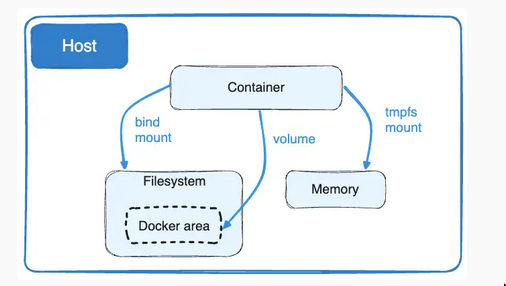
See Mounting related stuff for OS mounts instead of container mounts
| Host volume/Bind mount | Named volume | |
|---|---|---|
| Permission issues | We need to manually manage it | Usually no permission issue |
| Overwrite | Will overwite when mounted | Will merge files when mounted |
| Management | Managed outside of docker/podman | Managed by docker/podman |
| Remote storage | Not possible | Possible via drivers(local and image) |
| SELinux | - | I am not using it but people do it |
Host volumes / bind mounts
- persistent data outside of the container image is grafted on to the container’s filesystem via a bind mount to another location on the host.
- We need to make sure UID/GID inside the container match what’s there in the directory/file we’re bind mounting etc.
Named volumes
- When you create a volume, it’s stored within a directory on the Docker host.
- When you mount the volume into a container, this directory is what’s mounted into the container.
- This is similar to the way that bind mounts work
- Except that volumes are managed by Docker and are isolated from the core functionality of the host machine.
- Can be assigned a “driver”, either
localorimagelocalcan further be configured in ways to use normal Operating Systems Mounting related stuff! So in a way we can do bind mounts too withname:local volumebut idk why you’d want to do that. (using--optoption to passmountoptions etc.)
Other volumes
- Host volumes(bind mounts) and Names volumes(managed by docker) are ideas around Docker and Podman.
- If you’re using some Orchestrator, things might be totally different in terms of how volumes are handled.
- For eg. Nomad automatically bind mounts its “task directories” into the container while you can configure “nomad volumes” to the container. You could also do podman/docker volume etc. These become specific to the orchestrator at that point.
Container Security (containers using linux namespaces)
Privileged and Unprivileged & Rootless
on use of the phrase “privileged containers”
I am not against use of this term but for clarity, I like to think it like this:
- There’s no
privilegedornon/un-privilegedcontainers. But only containers made to run in aprivileged/non-privilegedmanner by combination of various things that can be applied to a running container and it’s a spectrum. - Following are some of those things which determine if a “running” container is actually privileged.
- user namespaces: Whether user namespaces(uid/gid) is even involved. This can be per container or across containers etc (see userns) or none.
rootless/rootfull: This is just usinguser namespacein an opinionated way with regards to therootuser and few other runtime specific things.- Linux Capabilities: Even if you run the container in rootfull mode(eg. no uid mapping whatsoever), if you get use capabilities
rootinside the container would not have as much power as it would normally have, however it’d still be able to edit any files etc. which is still concerning. --userflag : Is “specific to the main command” being run, defaults toroot, can be overridden by usingUSERin theContainerfileor by passing this option during run. This is useful both inrootfullandrootlessmodes.--priviligedflag: What this flag does depends on the container engine you’re using. But affects the execution of the container as a whole. See this for more info.
At any given setup multiple of these(or more) things will be at play and will actually determine whether if things are actually “privileged”.
The --user vs rootless mode
- “Rootless mode” is handled differently by Docker and Podman (better to assume that the ideas don’t transfer directly)
- The podman docs give a good description: podman-run — Podman documentation
- First of all, for you to specify
--userthe uid to be specified must exist inside the container. You’d using something likeuseraddfor that during image creation. - This sets the UID to be used
ONLY FOR THE COMMAND following that executionand overridesUSERset during image creation. - When you use
rootfullcontainer, eg. default Docker, you can pass in the--userflag, this will run the main command as that user but then you can exec into the container and then run command asrootinside the container which is alsorootoutside the container. When running inrootlessmode, this is not the case, in the exec case, you’ll be un-previledged user outside the container even if you’re root inside. - So since
--useroverrides the user, and rootless more re-maps the uid, do we need--userin rootless mode? Yes.- See Should you use the —user flag in rootless containers? | Enable Sysadmin
- Summary:
rootinside the container maps to a validuidin the host, but otheruidother thanrootmap to fake uids which have less capabilities. (See linked post). So using--user+rootlessis safer.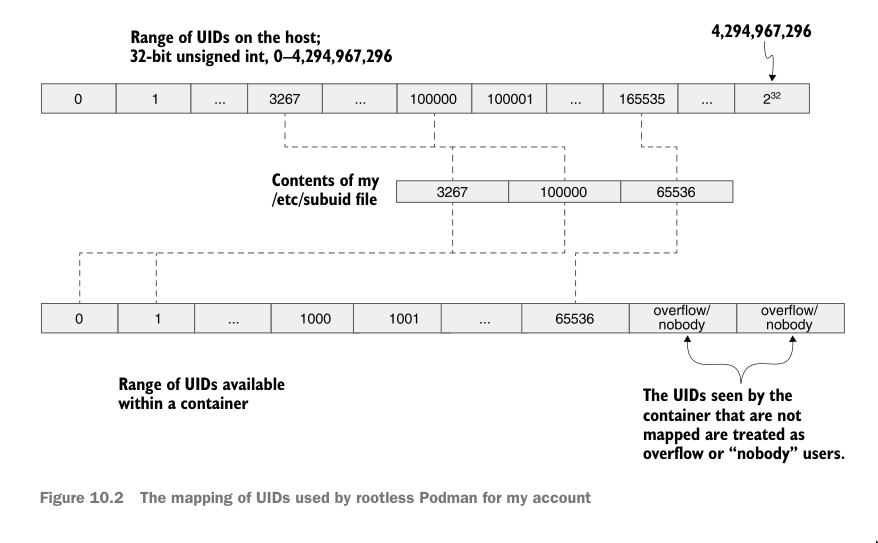
Linux Capabilities in rootless vs rootful
- Capabilities are per process things but they can be under a “user namespace”,
- When you’re using rootfull, capabilities go as
root(root in container and host are the same) - When using rootless, even you give the capabilities you’re giving that inside the usernamespace
Different meanings of Privileged and Unprivileged & Rootless
Unprivileged containers != Rootless containers
If containers are running as non-root users, when the runtime is still running as root, we don’t call them Rootless Containers.
| Context | Idea | Description | Consequences |
|---|---|---|---|
| Linux | root user | User with UID of 0 | Tools such as htop will automatically label user as root if sees the uid of 0 |
non-root user | User with UID other than 0 | ||
| Docker daemon | Rootfull | Daemon running as root | |
| Rootless | Daemon running as non-privileged user | ||
| Privileged | N/A | ||
| Unprivileged | N/A | ||
| Docker container (at runtime) | Rootfull | root in container is root in host | Get fired as an SRE |
| Rootless | root in the container is the non-root user on behalf of which the docker daemon was run | Mounted files in the container will be owned by root which in the host are owned by non-root user | |
| linux user namespaces come into play | |||
In the mounted path, other files not owned by “the” non-root user will show up as nobody:nobody in the container | |||
Other users inside the container will have a shifted user id and group id. | |||
| Privileged/Unprivileged | Depends on various things | ||
| Podman container (at runtime) | Rootfull | run the initial process as the root of the user namespace they are launched in. (uns is host) | |
| Rootless | run the initial process as the root of the user namespace they are launched in. (uns is mapped) | ||
| Privileged/Unprivileged | Depends on various things |
-
Rootless in Docker and Podman
- User namespace
- You can run rootfull in podman by using
sudo - Docker by default does NOT create
user namespace(uns, i.elsnswill not list any) it does create other namespaces ofc, but Podman being run as rootless by default will.
- You can run rootfull in podman by using
- Network namespace
-
See Docker for docker networking, which uses bridge
-
Podman uses
slirp4netnsto provide ip addressThere’s no shared network for rootless containers. Each one is plumbed into a tap interface which is then networked out to the host by slirp4netns. So if you start two containers in rootless mode, by default, they can’t talk directly to each other without exposing ports on the host. All your containers get the same IP address. On the installation I’m using they all get 10.0.2.100
By comparison, if you run containers rootfully, the networking looks much more similar to the default Docker configuration. Containers will get an individual IP address, and will be able to communicate with other containers on the bridge network that they’ve been connected to.
-
MacVlan: Rootfull podman containers to do something similar, but with DHCP support. See More Podman - Rootfull containers, Networking and processes for more info.
-
- User namespace
-
Rootless mode in Nomad
- Rootless Nomad · Issue #13669 · hashicorp/nomad · GitHub (Not fully supported yet, can use Podman as the task driver which can help)
UID/GID and SUID/SGID
subuid and subgid subordinate(uids/gids)
Different from setuid and setgid bits
/etc/subuidand/etc/subgidlet you assign extra user ids and group ids to a particular user. Thesubuidfile contains a list of users and the user ids that the user is allowed to impersonate.- Any resource owned by user(inside the container) which is not mapped(outside container) will get id
-1(nobody) - Range of ids you assign are no longer available to be assigned to other users (both primary and via
subuid) userto which they are assigned now ‘owns’ these ids.
- Any resource owned by user(inside the container) which is not mapped(outside container) will get id
- Configured via the
subidfield in/etc/nsswitch.conf(nsswitch) file. (Has default set tofiles) - See shadow-utils
- There’s also a limit to how many entries you can make in /etc/subuid files etc
-
Manual configuration
$ cat /etc/subuid #<user>:base_id:total_nos_of_ids_allowed user1:100000:65536 $ cat /etc/subgid user1:100000:65536
-
Using
usemodusermod --add-subuids 1000000-1000999999 root usermod --add-sugids 1000000-1000999999 pappu usermod --add-subuids 1000000-1000999999 --add-sugids 1000000-1000999999 xyzuser
-
What about
uid_mapandgid_map?These are specific to user NS. The
newuidmaptool can help.newuidmapsets/proc/[pid]/uid_mapbased on its command line arguments and the uids allowed.
Example usecase
Take an example usecase: “container” needs to run as
root!
In this case, we can re-map this user(root inside container) to a less-privileged user on the Docker host.
- use
usermodto “allocate” a range of suid to auser(on host). These uid(s) in the range are all fake! - Any
uidfrom the range can be used to “impersonate” theuser(host)inside anotheruser(inside the container)- i.e If in any case someone breaks out of the container, the
uidthey’ll have is the “fake” id, which has no privileges on the host system at all.
- i.e If in any case someone breaks out of the container, the
- After this you somehow map this to the
user namespace(see Linux Namespaces)- In raw linux, you’d use something like
newidmapto mapuid_mapandgid_map - In Docker, you’d use the
userns-remapconfig option(daemon.json)- You’d do something like
{"userns-remap": "testuser"}wheretestuseris the one you ranusermodfor. If you keep the value asdefault, docker would try to create a userdockremapfor you. (I dont like that autocreate idea honestly) - After that, container runtime should automatically pick the “fake uid”.
- See Isolate containers with a user namespace | Docker Docs for more info
- You’d do something like
- In raw linux, you’d use something like
- THIS
user-nsIS NOT PER CONTAINER!- Per container
user namespaceis not properly supported yet - Support for user namespaces in Nomad · Issue #23918 · hashicorp/nomad · GitHub
- Docker user namespacing map user in container to specific user in host · Issue #27548 · moby/moby · GitHub
- Podman does support: see https://docs.podman.io/en/v4.4/markdown/options/userns.container.html
- Understanding rootless Podman’s user namespace modes | Enable Sysadmin
- There’s also
--subuidname
- Per container
Creating “unprivileged” containers
Unprivileged created by:
- Taking a set of normal UIDs and GIDs from the host
- Usually at least
65536of each (to be POSIX compliant) - Then mapping those into the container
- Implementations mostly expect
/etc/subuidto contain at least65536 subuids. - This allows LXC & LXD to do the “shift” in containers because it has a reserved pool of UIDs and GIDs.
bind mounts and UID
bind mounts(also called host volume in contrast to named volume) don’t play well with user namespace mapping etc.- Mounts are a very separate topic, podman even uses SELinux for filesystem namespacing etc.
- But since bind mounts use host filesystem directly, it’s likely that there will be permission issues which will need to be handled individually
- I like to avoid bind mounts whenever possible
- See https://github.com/paperless-ngx/paperless-ngx/issues/4242
Resources
- https://github.com/saschagrunert/demystifying-containers#part-iv-container-security
- https://www.schutzwerk.com/blog/linux-container-namespaces04-user/
- https://news.ycombinator.com/item?id=38714607
- https://infosecadalid.com/2021/08/30/containers-rootful-rootless-privileged-and-super-privileged/
Container networking
Overview
- Also see Docker networking
- net ns can be connected using a Linux Virtual Ethernet Device or
veth pair - From a network architecture point of view, all containers on a given Docker host are sitting on bridge interfaces.
- Different container managers(docker, podman, lxd etc) provide a number of ways networking can be done with containers.
- An interesting one is the
bridged networkingapproach, which essentially boils down to3 things.- Creating
vethpair fromhosttonet namespace-X. Every new container will add newvethinterface and remove it once container is stopped. Eg.lxc info <instance_name>will show thevethcreated for theinstance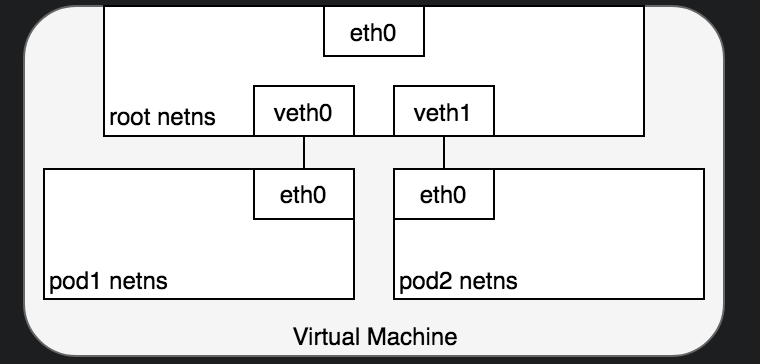
- Adding a
bridgefor thevethpair to talk through. When you installdocker, it automatically creates adocker0bridge created for containers to communicate.bridgeis a L2 device, uses ARP.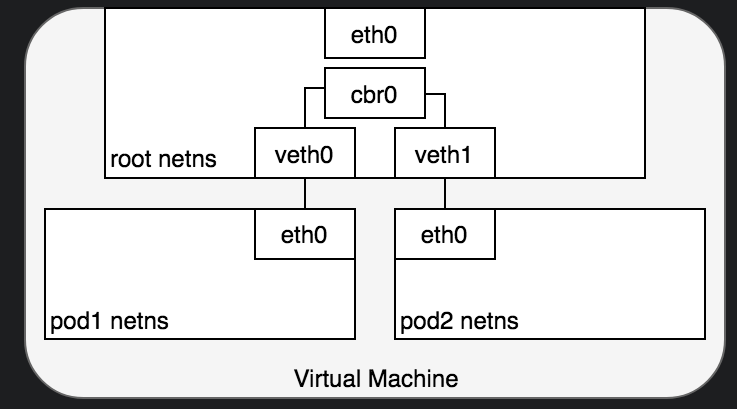
- Adding iptables rules to access outside network
- Creating
- See Introduction to Linux interfaces for virtual networking and Deep Dive into Linux Networking and Docker - Bridge, vETH and IPTables
- Also see 8.2.5 About Veth and Macvlan
TODO How do things happen with the network namespace
- https://www.reddit.com/r/podman/comments/14uxhrx/which_alternative_for_slirp4netns_in_rootless/
- https://github.com/eriksjolund/podman-networking-docs
- https://github.com/containers/podman/discussions/21451
- unprivileged users cannot create networking interfaces on the host.
- The default networking mode for rootful containers on the other side is netavark, which allows a container to have a routable IP address.
- https://github.com/containers/podman/blob/main/docs/tutorials/basic_networking.md
TODO Containers in Practice
TODO Golang Questions
- What user to use gid etc.
- Which image to use, why not alpine
- I recomend agains alpine images. They use muslc, that can be a real troublemaker at times. If you don’t need any tooling, then distroless image is great. Otherwise debian-slim ticks everything for me.
- You can also use SCRATCH but be aware of things like outgoing HTTPS requests, where you need a local CA certificate list for validating certificates.
- We can also do COPY —from=build etc/ssl/certs/ca-certificates.crt /etc/ssl/certs
- Distroless
- a base image with just ca-certificates, a passwd entry and tzdata, which are a few dependencies the Go runtime might look for at runtime.
- So it’s pretty nice, rather than using SCRATCH
- Q: Why not OS base image in golang applications? what about cgo.
- Which image tool to use, docker or something else?
- so if you are using containerization in development and not building inside the container, you are missing out on one of the major advantages of the paradigm.
- So we should be building inside the container?
- https://docs.docker.com/build/building/multi-stage/
- Building a docker image for a Go programm : golang
- Usually people use multi-stage builds. Use the golang image to build the binary, then copy that binary to the more minimal alpine image.