tags : Linux, Systems, Distributed Filesystems
Filesystems Primer
What they do
- Mapping
- They provide a
filename-to-anything mapping. Anything can be your HDD, some git repository(gitfs) or some computer connected through ssh etc(sshfs). - What filesystems essentially do is that they
map a filenameyou see to theactual position where the data is saved.
- They provide a
- Structure and Organization
- FS give meaning to the data on a particular storage medium.
- Determining the structure how the data is really saved
- It tells what structure it wants the data to be written to the actual hardware driver(sata driver in most PCs nowadays).
- Eg. one FS for example could say it writes files at the next empty space it can find (eg. ntfs)
- Eg. another FS writes files in the middle of an empty block (eg. ext4)
- Metadata
- Metadata is saved alongside with the filedata. (Creation date, permissions etc.)
What they don’t do
- They don’t write directly to a physical disk.
Series of events
This is extremely simplified version. Lots of details missing. Eg. when accessing metadata we already need to be communicating with the hardware driver.
- Program uses the system call
opento open a file and gives it a path and filename (eg."/home/geekodour/readme.txt) - Kernel uses
/home/geekodourto determine what filesystem and hardware device is needed.- Each directory in a linux filesystem could be mounted to a different filesystem (and/or on a different hardware device)
- With the path the kernel can say what filesystem is needed in this case.
- Kernel tells the filesystem driver (
kernel moduleor Fuse , doesn’t matter) that this file is requested - Filesystem driver gathers all the data needed to access the real data on the harddisk from the filename
- Also checks if access is even possible (Eg. if the metadata of this file allow the user to even read it)
- Gathered data is then handed to the
hardware driverresponsible for thedevicewhich then gets the real data that can be handed back to the application.
Types of FS
Why different FS?
Some fs are faster if you’re using small files, some are faster if you’re using large files. Different FS offer different capabilities such as Capacity(Volume Size, File Size, No. of files etc.), copy on write(CoW), Extended attributes, Compression, Encryption(Using LUKS, inbuilt etc)
Disk FS
extX family
- Most common native Linux filesystems in use. Supports all of linux permissions and features etc.
- Since it’s a journaling FS, if we throttle a low priority process on diskI/O, it’ll also impact the high priority process because, the flushing the low priority data to disk now becomes the bottleneck and must be performed before.
btrfsdoes not have this problem.
btrfs
See Copy on Write
- Newer Linux native FS, more advanced file system than
extX. Built by Oracle(IBM) as a rival tozfsfrom Sun. - Cool features: real-time, on the fly file compression, online resizing, subvolumes, snapshots, in-place conversion from ext3/4, autodefrag, in-built filesystem based encryption, kernel level RAID support, and others.
-
CoW based
- COW filesystem an improvement over the Journaling
- How does CoW works in long term usage. : btrfs
- Basically changes are not overwritten, but a newer version/generation is made by making a copy if written to. So if snapshot is taken we can go back to the previous version etc.
FAT(File Allocation Table)
- Basic file system with minimal features and relies on the operating system to manage most of it’s features and maintenance
- Compatible across devices and media and is supported by most consumer and professional devices and operating systems
- UEFI supports only FAT filesystem. Hence boot partitions are usually FAT. Esp
VFAT - 8-Bit FAT: It was introduced in 1977 for use in floppy disks and had a maximum volume size of 2.0 MB.
- FAT12: It was introduced in 1984 with MS-DOS 3.0 and supported a maximum volume size of 32 MB.
- FAT16: Introduced in 1987 with MS-DOS 3.3 and supported a maximum volume size of 2 GB. It is also used in early versions of Windows operating system.
- VFAT: Extension of the FAT16 file system and was introduced with Windows 95 with long file name support.
- FAT32
- Extension of FAT16 and VFAT
- It was introduced in 1996 with Windows 95 OSR2 and supported a maximum volume size of 2 TB.
- Needs to be defragmented on a regular basis, not recommended for drives with low write tolerance like SSD drives.
- exFAT
- It was introduced in 2006 to enhanced and optimized for flash storage, with most file and volume limits increased
- The Linux kernel introduced native exFAT support with the 5.4 release in November 2019
NTFS
- Windows native file system introduced in Windows NT in the 1990’s.
- Doesn’t support Linux file or directory permissions and ownership
- Usable as storage volumes that can be shared with other operating systems
- Not usable as a system or home storage system
Non disk FS/Pseudo Filesystems
This is different than pseudo devices(
/dev/null,/dev/zeroetc.) See Unix Files
- Run
findmnt - To exchange data between user space and kernel space the Linux kernel provides a couple of RAM based file systems.
- The interfaces is based on files.
procfs
- Originally designed to export all kind of process information eg. status, open fd(s).
- Since kernel 2.5/2.6 the kernel-interface was moved to
/sys, because/procgot cluttered with lots of non-process related information.
About
/proc/sys
/prochas a special directory:/proc/sys- Allows to configure a lot of parameters of the running system.
- Usually each file consists of a single value.
- All directories and files below
/proc/sysare not implemented with theprocfsinterface.- Instead they use a mechanism called sysctl. So when we are using
sysctlit is doing stuff with/proc/sys.- If a value is set by the
sysctlcommand it only persists as long as the kernel is running, gets lost as soon as the machine is rebooted.- In order to change the values permanently they have to be written to the file
/etc/sysctl.d/*.
sysfs
- Contains non-process info(such as device info etc.) that was previously in
/proc. /sysmirrors the internal kernel data structures in form of a fs- Used for viewing
kernel objectsfromuser-spacewhich are created and destroyed by the kernel. Parentsconfigfs, which is a kernel manager in the form of a fs. - More restrictive than
procfs
├─/sys
│ ├─/sys/firmware/efi/efivars
│ ├─/sys/kernel/security
│ ├─/sys/fs/cgroup
│ ├─/sys/fs/pstore
│ ├─/sys/fs/bpf
│ ├─/sys/kernel/debug
│ ├─/sys/kernel/tracing
│ ├─/sys/fs/fuse/connections
│ └─/sys/kernel/configCustom FS
- See Fuse
VFS
- To have multiple fs on the disk, but they appear to be one filesystem layer to the user.
- Build a separate abstract layer that calls the underlying concrete FS and exposes a common interface for the userspace. This means, all sys calls related to files are directed to the VFS.
- This also means that, To create a new fs you must supply all the methods that the VFS requires.
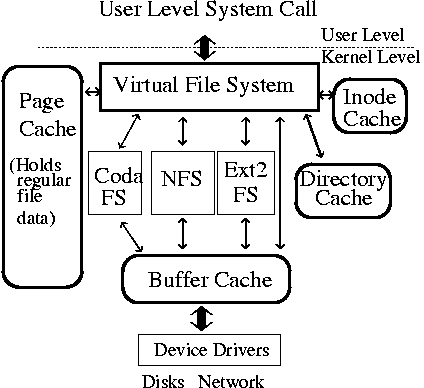
For eg. the read syscall is unaware of the underlying file system types(ext3/NFS). It is also unaware of the particular storage medium upon which the file system is mounted(ATAPI/SCSI (SAS) disk/SATA). It is also unware of the physical medium (ssd/hdd)
Container Filesystem
- see Containers
- There is a reference of
rootfswhen discussing containers, which is completely different from the rootfs that is related to the booting of an OS.
Mounting related stuff
Mounting
- Associating a file system to a storage device in Linux is a process called mounting.
- When we mount a
block deviceinto the file system, you tell the OS two things- Type of FS: This block device here contains a filesystem of type X, so please load the appropriate driver
- Mount point: I want the filesystem on this block device to be mapped to path Y.
/etc/fstabis a list of filesystems to be mounted at boot time./etc/mtabis a list of currently mounted filesystems. (symlinked to/proc/self/mounts)
Mounting Loop devices
loop devices are not loobpack devices, some ppl wrongly call loop devices loopback devices
- You can mount regular files as if they were block devices.
- A loop device is a pseudo translation device, it translates block file calls into normal filesystem calls to a specific file
Mounting and Permissions
- When mounting a disk, we use the
mountcommand.- Usually you can’t mount without being the root user because security concerns as you could replace a fs directory etc
- However, you could modify fstab to allow non-root users to mount it to certain locations. But this is again limiting.
- For all these, for normal usecases we have things like
udisk2,pmountetc which make mounting in the filesystem easier for non-root users.- udisk2 and pmount are alternatives
- File permissions on the mounted drive is filesystem specific!
- Eg. With NTFS you can use
gid/uidto specify which of them to mount these things with when using themountcommand - Eg. When using
ext4, file permissions are stored in the filesystem itself. So if you want to have the normal user have access to some directory, create and chown the directory to that user via the root user for the first time and going forward the non-root user would have access to it.
- Eg. With NTFS you can use
- Other links
- This is different with different filesystems
Binding
~/example_dir
λ tree
.
├── A
│ └── abc
├── B
│ └── xyz
└── C
~/example_dir
λ mount A C
mount: /home/geekodour/example_dir/C: /home/geekodour/example_dir/A is not a block device.
~/example_dir
λ mount --bind A C
~/example_dir
λ ls C
abc
~/example_dir
λ umount C- A bind mount instead takes an existing directory tree and replicates it under a different point.
- The directories and files in the bind mount are the same as the original.
- Any modification on one side is immediately reflected on the other side, since the two views show the same data.
Bind Mounts and Symbolic Links
- Bind mounts and symlinks both serve similar purposes: Making the same file (or directory) appear in more than one location.
- If a process follows a symbolic link, the file/directory it refers to will be resolved in the context of that process.
- This is not what we want if we want to access say
/devin a chrooted env. That’s where bind mount come into play.
Filesystem interface to files
inodes/vnodes
- FS(s) agree on a certain structure to return when it asks them about the file. It’s
inode/vnode(BSD systems). Not all FS implementinodes inodeis a data structure that describes(metadata) a filesystem object, it’s a description of a file on the filesystem.- Files which are not even on the disk can have
inodes. Eg./dev/nullhas aninodenumber.
- Files which are not even on the disk can have
inodesare stored on disk, contain the actual location(not the path!) of the file. Each FS has its own way to store it.- Size of the inode and the total no. of
inodesis usually set in creation time, so there’s a max limit of files that can be created in a FS. - FS such as ZFS, btrfs, etc omit a fixed-size inode table. FS such has NTFS don’t even use inodes.
inodesare stored per FS, thus are FS dependent. Means the sameinode nocan be found on multiple FS().
- Size of the inode and the total no. of
inodestructureinode number / i-number- file ownership
- access mode
- file type
datablocks- other metadata
- NO file name
- Not always the case: See
ext4 inline_data - There’s another structure that stores a table or index of
inodenumbers associated with thefile name. (Seedentry) - The file names can only be retrieved from that other index table that associate the names with the
inodenumber. - This
file nametable is usually stored in thedata sectionof thedirectory fileand is FS specific. See Storage layers - Files can have multiple names because multiple names can point to the same
inodenumber. (Hard links) - Filenames can be long, we want to keep the
inodestructure small - A file’s
inodenumber stays the same when moved to another directory on thesame device.
- Not always the case: See
- NO file data(no content stored in inode)
file desc
See File Descriptors