tags : Linux, Systems, Filesystems, Storage
Thanks to Alex for his amazing blogposts explaining these concepts!
- Userland Disk I/O 🌟 - IO devices and latency — PlanetScale
FAQ
What is I/O really?
I/O is the process of copying data between RAM memory and external devices such as a disk driver. If you want to copy one section of the driver to another section in the driver the data MUST go through RAM at some point. (from some reddit comment)
How does data from device get to memory for I/O?
DMA
- See DMA
via CPU
- Device Interrupt: The device notifies the CPU that it has data ready.
- Interrupt Handler: The CPU executes a routine to manage the data transfer.
- Polling/Programmed I/O: The CPU interacts with the device to initiate the transfer.
- Data Transfer: The CPU reads the data from the device and stores it temporarily.
- Copying to Memory: The CPU transfers the data from its registers to the memory.
- Completion and Resume: Additional operations are performed, and the CPU resumes its interrupted task.
Is Page Cache inevitable?
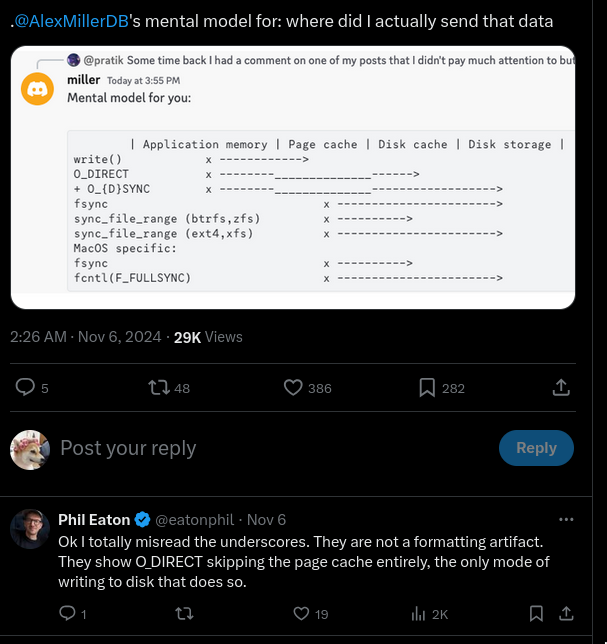
- Yes. Both memory mapped I/O and standard I/O internally access files
on diskthroughpage cache. We can use theO_DIRECTto skip the page cache. - If you’re doing any I/O things will go via RAM, and when it does so it’ll be using page cache.
Is Page cache involved when doing DMA?
- Yes
- Linux does not allow memory-to-memory DMA. It only does
- DMA_BIDIRECTIONAL, DMA_TO_DEVICE, DMA_FROM_DEVICE, DMA_NONE
- See Dynamic DMA mapping Guide — The Linux Kernel documentation
Raw IO/Unbuffered IO/Direct IO/Low level IO
- These are low level unbuffered operations that usually deal with File Descriptors.
- The name can be confusing, what unbuffered means is
- No application level buffering happens(eg. Standard IO)
- You still have to provide the destination buffer and length
- i.e. where you would like the function to store the read data for you to use in your own program.
- Example for
read()read()being unbuffered means if you ask for1 byteyou get1 byteread from disk- your next call to
read()triggers another disk read. - Under the hood it is anyway using the page cache, but just no userspace buffering. (See Virtual Memory)
When to use what?
Some internet comments.
- Direct IO with read and write is a good idea if you know exactly what size data you are going to read and that size is large enough for extra buffering not to make much of a difference (or you implement your own buffering).
- Picking between fread and read is somewhat of a premature optimization I think: even if you think read is unbuffered, it’s likely the file is being buffered (again) at the OS level, and probably cached in the hard drive controller too, and in any significant case (big file) your bottleneck is I/O anyway so the price of an extra memcpy is negligible… but now you have to manage your own buffer instead to avoid accidentally causing syscalls.
- I suggest you stick with fread for “files”, read for network sockets and hardware interfaces (RS-232 registers, etc), and if you have a use case for random access in a large file then you will want to look into mmap memory-mapped i/o.
- If you are using the low-level (syscalls)
- open(2), write(2), read(2) etc.
- then use the low-level fsync(2).
Standard IO
- It’s basically syscalls combined with userland optimizations. (Eg.
fopen, fwrite, fread, fflush, fclose). - You generally don’t mix Raw IO stuff like
fsyncwith Standard IO stuff likefflush. But you probably can? - It also involves copying your data from the page cache to the userland buffer cache. So essentially there is 2 cost:
syscallsandcopyingof data.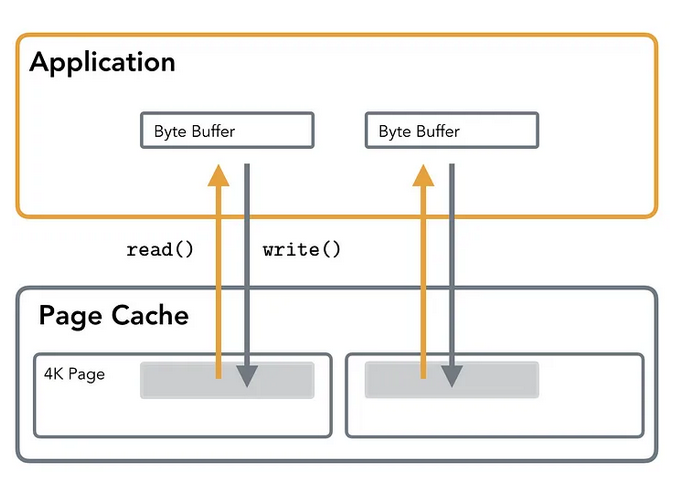
Userspace buffering
- See
man setbuf - This is not the kernel buffer (
page cache) (See Virtual Memory)
Unbuffered
- Information appears on the destination file or terminal as soon as written
stderris usually unbuffered
Block buffered 🌟
- Many characters are saved up and written as a block
- Usually files are block buffered
- If you call
fread()and ask for1 bytethen the stdlib might actually read32k, give you1 byte - Next time you call
fread()the bytes come from the buffer and not the disk. fflush(3)may be used to force the block out early. (fflushflushes the userspace buffer)
- If you call
Line buffered
- Characters are saved up until a newline is output or input is read from any stream attached to a terminal device (typically stdin).
stdoutis usually line buffered
How disk read happens
- CPU initiates disk read
- Sends (
logical block no,memory address,command) - Through
bus interface->I/O bridge->I/O bus->disk controller
- Sends (
Disk controller- Executes the command
- Uses
DMAto send that data over to memory. - Sends an Interrupts informing transfer done
- Virtual Memory
- Now that stuff is in memory
- Kernel will try to caches FS
blocksin memory into the Page cache. - VM works with
Pages, which is usually 4096, similar to the size of FSblockin my case, but it does not have to be like that.
Blocks v/s Sectors
Virtual Memory
pages<=> Filesystemblocks<=> Block Devicesectors
Filesystem
Blockis an abstraction of Filesystems (See Storage layers)- All FS operations can be accessed only in multiple of
Blocks. tune2fswill give youBlock sizefor your FS. (Usually4096)
Block Device
- Block device provides unbuffered access to hardware. Linux uses block device to access disk devices such as SSDs and HDDs
- Smallest addressable unit on a block device is a
sector. It is not possible to transfer less than onesectorworth of data. fdisk -lwill give you thesector sizeof your block device. (Usually512)
Under the hood syscalls
- open, write, read, fsync, sync, close
Read
- Page Cache is addressed first.
- If the data is absent, the Page Fault is triggered and contents are paged in.
- Non-sequential access requires another system call
lseek. - If a
pagegets dirty,read()will read from the Page Cache instead of reading from (now outdated) disk.
Write
- Buffer(userland) contents are first written to Page Cache.
- Data does not reach the disk right away.
- Actual hardware write is done when kernel writebacks the
dirty page. - You can also use
fsync - The
writebackofdirty pagefrom Page Cache to disk can be configured via thresholds and ratios.
Memory mapped IO
- open, mmap, msync, munmap
- See mmap, can tell it to use Copy on Write semantics
- A memory region in “process address space” is mapped directly to “page cache”. No additional userspace buffer cache involved.
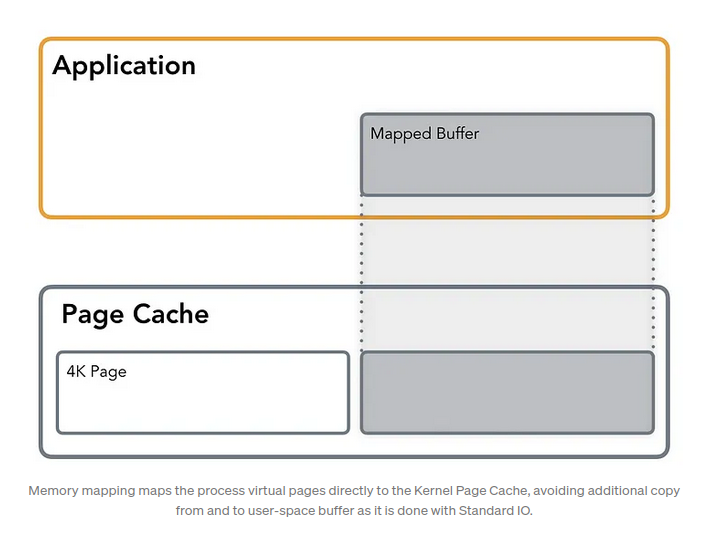
- Any dirty page handling is now done by the OS
How the mapping happens
- File is memory mapped
- Space for the memory mapping is reserved, but not allocated
- Attempts to access file region, if first read/write, page fault
- Allocation happens
- One can also pre-fault using
MAP_POPULATE
Improving memory mapped IO
- There’s no single way, but using Advice syscalls can help.
Async IO (AIO)
Interface allows initiating multiple IO operations & register callbacks
Pitfalls
glibchas no interface. There’slibiobut people say it sucks.- Usually you don’t want to be writing code with direct calls to
epoll/poll/select/kqueueetc. Because not good for portability. - It is something of a black art, and has many pitfalls.
- There are userland libraries such as libenev, libuv(used in node.js) etc. which use their own logic to do async io.
io_uring
See io_uring
Vectored IO (Scatter/Gather)
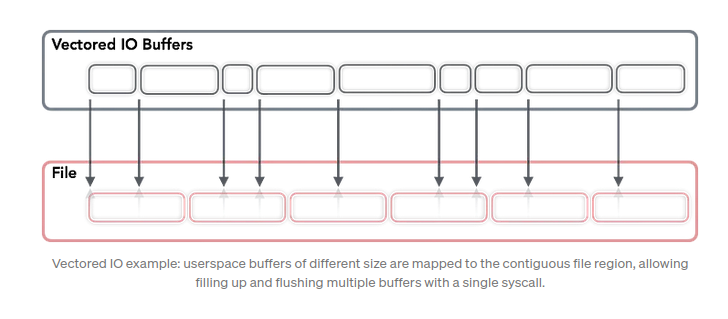 Operates on a vector of buffers and allows reading and writing data to/from disk using multiple buffers per system call.
Operates on a vector of buffers and allows reading and writing data to/from disk using multiple buffers per system call.
- Allows for
- Reading smaller chunks
- Reducing the amount of system calls
- Uses
- Analytics workloads and/or columnar databases(data stored contiguously)
- Processing can be done in parallel in sparse blocks
- Eg. Apache Arrow
Non Blocking IO
- Take away: Non-Blocking IO does not work for regular files.
IO Schedulers
Typical SSD throughput is greater than 10_000 IOPS, while a typical HDD can handle only about 200 IOPS. There is a queue of requests that have to wait for access to the storage. This is where IO schedulers come in.
- Arch wiki has great summary on the algorithms
Legacy
- Elevator : Order by logical address, not optimal for sequential access
- Anticipatory : Tries to improve Elevator by waiting for other seq requests
- Deadline : Came in to prevent starvation. Bad for overall throughput.
- Completely fair queueing (
cfq): Allocates timeslice and queue size by process. cgroups is supported, Good for cloud hosting etc.
Newer
- Budget Fair Queueing (
bfq): Improves oncfq. Has high per operation overhead, so using this on a slow CPU, can slow down the whole thing. Focus on lowest latency rather than highest throughput. - mq-deadline: Adaptation of the deadline scheduler to multi-threading. Good for non-rotating media.
- Kyber : New kid in the block. Token based.
Other notes
Sparse File
Sparse files are files stored in a file system where consecutive data blocks consisting of all zero-bytes (null-bytes) are compressed to nothing.
- Use: Bittorrent, VM images etc.
- What are sparse files and how to tell if a file is stored sparsely | Ctrl blog (Best explanation)
- Sparse file - Wikipedia
- linux - How to view contents of a sparse file? - Unix & Linux Stack Exchange
- filesystems - What are functions to manipulate sparse files under Linux? - Unix & Linux Stack Exchange
- filesystems - How transparent are sparse files for applications? - Unix & Linux Stack Exchange
- filesystems - What is a sparse file and why do we need it? - Stack Overflow
Reading large files
Resources
- Zig’s I/O and Concurrency Story - King Protty - Software You Can Love 2022 - YouTube
- Learn about different I/O Access Methods and what we chose for ScyllaDB 🌟
- Rubber Ducking: The Various Kinds of IO - Blocking, Non-blocking, Multiplexed…
- The Secret Life of fsync
- Investigating Linux Phantom Disk Reads | QuestDB
- Is sequential IO dead in the era of the NVMe drive? | Lobsters
- Modern storage is plenty fast. It is the APIs that are bad.
- 50 years in filesystems: 1974 | Die wunderbare Welt von Isotopp
- Livestream - P&S Modern SSDs (Spring 2023) - YouTube
- Eat My Data: How Everybody gets File IO Wrong - YouTube
- Database Architects: What Every Programmer Should Know About SSDs
- How does Linux really handle writes?
- Coding for SSDs – Part 1: Introduction and Table of Contents | Code Capsule