tags : Database
Basics
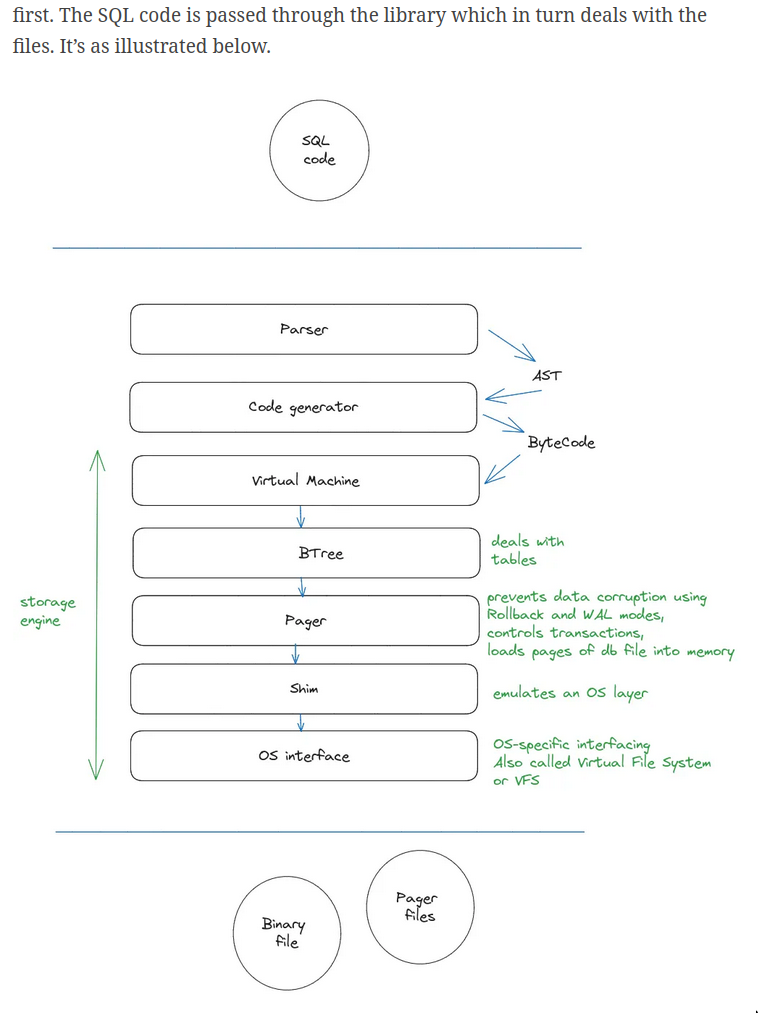
- SQLite is a relational database management system contained in a C library. It’s the standard bearer of the “single process application” architecture.
- sqlite currently is single-writer, multi-reader. There are ways to do multi-writer, see
cr-sqlite(Local First Software (LoFi))
Gotchas
AUTOINCREMENTINSERT, if aINTEGER PRIMARY KEYcolumn is not explicitly given a value, then it will be filled automatically with an unused integer, usually one more than the largest ids in use.- This is true regardless use of
AUTOINCREMENT
- This is true regardless use of
- In sqlite,
AUTOINCREMENTprevents the reuse of ids over the lifetime of the database
- Weak Types
- int column can take string
- It does not enforce data type constraints. Data of any type can (usually) be inserted into any column. You can put arbitrary length strings into integer columns, floating point numbers in boolean columns, or dates in character columns.
- But it does type affinity, if you try to insert a string which can be casted into an int, it’ll probaby try doing that
Internals
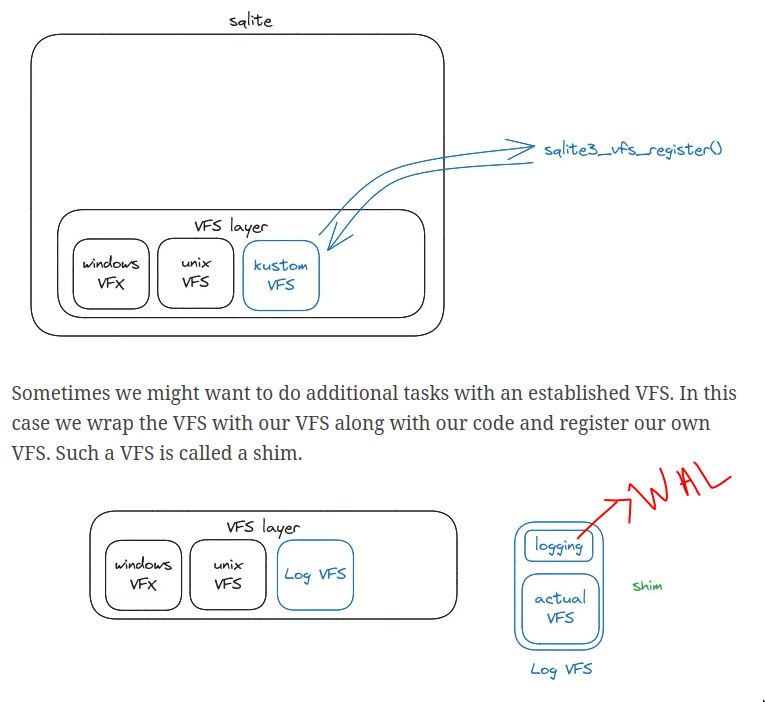
VFS
- SQLite has a VFS interface, which can be used to implement a file system on any system
WAL
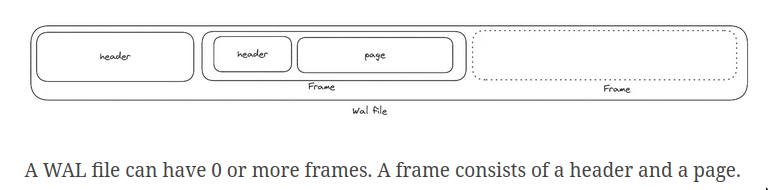
- ???
- checkpoint is an op which compacts WAL frames to drop ones that are out-of-date
- checkpoint operation is one where the contents of the WAL file is applied to the database.
- What happens
- In WAL mode, write operations append to a log file stored alongside SQLite’s main database file. Readers check both the WAL file and the main database to satisfy queries.
- SQLite automatically checkpoints pages from the WAL back to the main database.
- Purpose of WAL
- Durability (primary)
- Allow concurrent access (secondary)
- This is why you can implement WAL without shared memory
Page & Cache
- database file consists of one or more “pages”.
- The minimum size of an SQLite database is one page for each table and each index.
- See https://www.sqlite.org/pgszchng2016.html
- For any query, sqlite will do certain amount of page reads
- Page types
- Internal
- Leaf
- Overflow
Transactions
Settings/Configuration
Concurrency
| Type | ROLLBACK | WAL | WAL2(future) |
|---|---|---|---|
| multi-read | allowed | allowed | allowed |
| read-write | not allowed | allowed | allowed |
| multi-write | not allowed | not allowed | allowed |
- Each
connectioncan run onetransactionat a time - Multiple
connections= Multipletransactions= concurrency- May be allowed over multiple
sqlite pages/within samesqlite page
- May be allowed over multiple
WARNING: Some VFS (eg. OPFS sqlite vfs) don’t allow >1connection- In those cases, no concurrency, everything sequential
Suggested settings
- read-only: max open connection to some large no
- read-write: max 1 open connection
Consistency
Timeouts
- busy timeout to some large value, like 5000
- Any other transactions that attempt to write at the same time will fail with SQLITE_BUSY.
Transaction
- Use transactions for multi-query methods
- read/write pool should also use
BEGIN IMMEDITATEwhen starting transactions (_txlock=immediate), to avoid certain issues that can result in “database is locked” errors.
Replication
See Data Replication
litestream: Disaster recovery tool for SQLite. It runs as a background process and safely replicates changes incrementally to another file or S3.- It takes control of SQLite’s WAL-mode journaling by opening an indefinite read transaction that prevents automatic checkpoints that’s default for sqlite.
- It then captures WAL updates, replicate them, and trigger the checkpointing.
litefs: LiteFS sets up a FUSE mount so once you have that in place then you can create a database within that mount directory and it is automatically replicated.- It’s similar to litestream but as a fs but both cannot work together
cr-sqlite: cr-sqlite adds multi-master replication and partition tolerance to SQLite via crdt and/or causally ordered event logs. (Also see Local First Software (LoFi))- maxpert/marmot : Multi-writer distributed SQLite based on NATS (See Message Queue (MQ))
clouflare D1: offers d1 sqlite w replication- Distributed sqlite
mvsqlite- See Turning SQLite into a distributed database
- Tries to do concurrent writes also
- handles sharding and replication both
rsqlite- Provides fault tolerance and high-availability through replication
- Design doc: rqlite Design | rqlite
dsqlite
Using in applications
General use
- We need to worry about state when writing our applications cuz
- The primitives we have to express mutations
- Support for transactions against in-memory data structures
- Support for constraints on im-memory data
- This sort of can be sidestepped by using sqlite as our data store for application state
- SQLite is that it’s in-process so you avoid most per-query latency so you don’t have to worry as much about N+1 query performance issues.
Use on the web
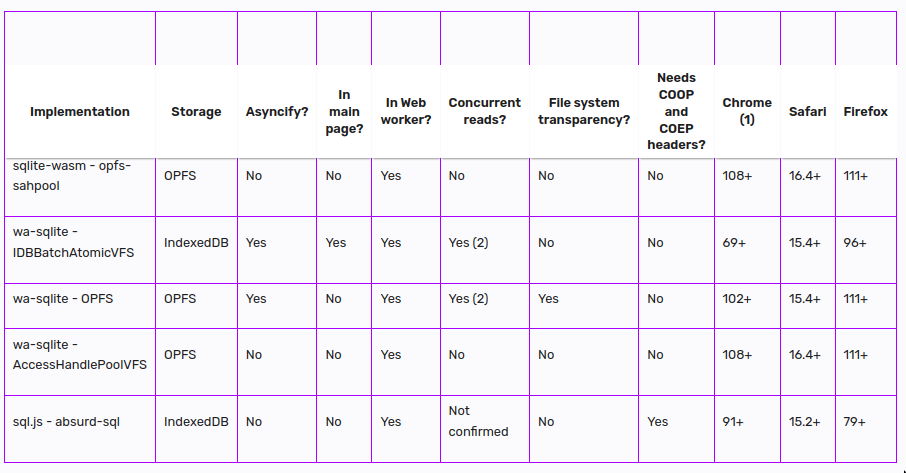
Technologies
SQL.js- came in 2014, initially to js, now to wasm
- only in-memory, no persistence
- https://github.com/sql-js/sql.js
wa-sqlite- came in 2021, to wasm
- persistence to indexDB but slow
- later adopted things from
absurd-sqlwhich made it faster.absurd-sqlis a backend forsql.jsabsurd-sqlwas inspired by phiresky’s github pages experiment
sqlite wasm build: official wasm version from sqlite folksWebSQL- built-in support in Chrome and older versions of Safari. It had too many limitations
- phasing out
Storage
- See Web Storage
-
OPFS
- Ideal for sqlite but currently API not super mature
- Concurrency
- Opening a file adds exclusive lock and no other read-write can happen in that connection.
- OPFS currently only allows one connection, so you can’t really use sqlite WAL when using OPFS. Because it’s just one connection, you can’t even have concurrent reads.
-
IndexDB
- Storing individual blocks of data as IndexedDB objects
- Concurrency
- Exclusive lock on an object store for any write. No concurrent r-w
- Can support concurrent reads
-
local/session Storage
Async
 SQlite uses synchronous calls but the Javascript Runtime and Browser are async (See Concurrency)
SQlite uses synchronous calls but the Javascript Runtime and Browser are async (See Concurrency)
Asyncify- Translates sync to async
- more build size, performance reduction, bugs in asyncify could lead to sqlite
SharedArrayBuffer + Atomics API- Separate Worker process for the file system operations
OPFS syncAccessHandle- synchronous read and write access to files.
- While operations on an open file are synchronous now, opening a file is still an asynchronous operation. Needs workaround for that.
On Github Pages
- phiresky built a readonly VFS on top of HTTP Range requests with
SQL.js - They set sqlite
page_sizeto1KiB - i.e each total response size(query result) is
270KiB- It’ll need to do
270requests - Unless you prefetch, which can be less then. Like
20requests will fetch270KiB - “I implemented a pre-fetching system that tries to detect access patterns through three separate virtual read heads and exponentially increases the request size for sequential reads.”
- It’ll need to do
On the edge
- Turso does this
- Turso is essentially a globally distributed single-write multi-read database. All writes must be made to a central primary instance and replicated to edge nodes. Before the replication completes, readers can see inconsistent results.
Extensions
run-time loadable extension
webassembly functions
- libSQL allows WebAssembly defined functions
- See WebAssembly functions for your SQLite-compatible database - Turso Blog
libSQL
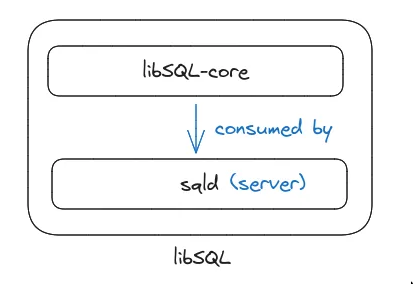
- fork of sqlite w extended capabilities
- It also implements the PostgreSQL wire protocol, so postgres tools can connect to it thinking it’s postgres, ofc not all commands will work
sqldcan be connected via http and WebSockets (Hrana). See this
Links
- See https://antonz.org/install-sqlite-extension/#install-go
- https://sqlpkg.org/
- https://github.com/nalgeon/sqlean
- SQLite FTS5 Extension
- https://antonz.org/sqlean-py/
- Making SQLite extensions pip install-able | Hacker News
- Cloud Backed SQLite | Hacker News
- Libgsqlite: A SQLite extension which loads a Google Sheet
- Things that surprised me while running SQLite in production | Hacker News
- SQLite-based databases on the Postgres protocol? Yes we can | Hacker News
Links and resources
- sqlite for electric car: I extensively used SQLite in a telemetry system
- Scaling SQLite to 4M QPS on a Single Server (EC2 vs Bare Metal) « Expensify Blog
- Why SQLite Uses Bytecode | Lobsters
- Modern SQLite: Generated columns | Lobsters
- Why does SQLite (in production) have such a bad rep? | Lobsters
- SQLite or PostgreSQL? It’s Complicated | Lobsters 🌟
- GitHub - QuadrupleA/sqlite-page-explorer: Visual tool to explore SQLite databases page-by-page, the way they’re stored on disk and the way SQLite sees them. 🌟
- https://lobste.rs/s/yapvon/what_do_about_sqlite_busy_errors_despite
- SQLite-on-the-server is misunderstood: Better at hyper-scale than micro-scale | Hacker News