tags : Web Development, Multipart Upload
Meta
Connection vs Request
Connections
- client and server introduce themselves
- HTTP1.1 and HTTP/2 uses TCP while HTTP/3 uses QUIC which is based on UDP.
Requests
- client ask something from server
- To make a HTTP1.1 or HTTP2 request you need to have an active connection w the server.
- Eg. An endpoint accepts 5 connections and 10 requests from given IP address.
Browsers
- Browsers usually limit 6 connections per origin(scheme, host, and port). Be it HTTP1.1 or HTTP2.
1.1,2,3 What?
HTTP’s “core” semantics don’t change between protocol versions. i.e most of the time methods and status codes, header fields mean the same thing no matter what version of the protocol you use(HTTP/1.1, HTTP/2, HTTP/3)
HTTP/1.1
- Written in 1997
- RFC revised in 2013
- RFC again revised in 2022
- HTTP/1.1 suffers from Head of line(HOL) blocking. Each browser/client has a limited number of connections to a server and doing a new request over one of those connections has to wait for the ones to complete before it can fire it off.
- w HTTP1.1, browser can make
1 request/connectionbut in-reality, they make multiple connections in parallel to the server. i.e(new(r)/new(c)) x N - Because of limited requests servers used to concat assets and do things like css sprites to reduce number of requests. But we don’t have this issue w HTTP2 because no. of request is not a problem for HTTP2.
- HTTP1.1 can still send multiple request in a connection using pipelining but that’s not widely supported and has other problems.
- Pipelining means sending further requests without waiting for responses.
HTTP/2
- Prior to HTTP/2, WG attempted HTTP_NG
- Introduced in 2015 and then RFC revised in 2022.
- HTTP2 does the same thing as HTTP3/QUIC but on top of
TCP - It introduced primarily 2 things, multplexing and server push thing. server push thing made john wick his enemy.
Multiplexing
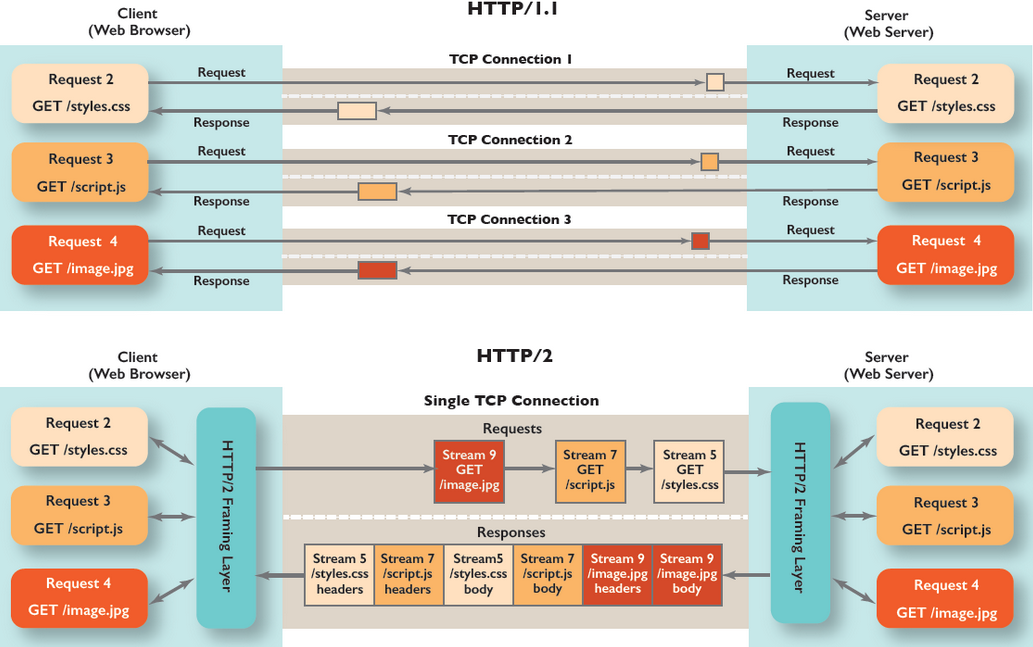
- HTTP2 adds multiplexing where we can make multiple
requestperconnection. So no need to make multiple connections. - With this we do not delay sending of requests, no waiting for a free connection. All these requests make their way through the Internet to the server in (almost) parallel. The server responds to each one, and then they start to make their way back.
-
Dealing w HOL
- Web server can respond to them in any order it feels like and send back files in different order, or even break each file requested into pieces and intermingle the files together.
- This has the secondary benefit of one heavy request not blocking all the other subsequent requests i.e HOL.
- It addresses HOL by TCP multiplexing, but still have an underlying issue at
TCPlevel. Because TCP is reliable delivery protocol, Loss of a single packet in a flow can block access to those after it. This happens often and seamlessly but HTTP3 makes this better w QUIC. - Because of this, HTTP2’s stream multiplexing works really well on good connections but terribly on bad.
- 2021: QUICv1 was released to replace
TCP. (QUIC uses UDP)
Ordering and Prioritization
- HTTP2 allows request prioritization for the client (browser)
- But it is up to the server to decide what to do based on the request.
- The server is free to not respect the prioritization request and process data at its own will.
Server Push GW
- Added Server Push: Servers can send
req/res pairto clients in advance to make things faster - Issue: Server predicting what the client needs is hard. Network conditions, client can have cache, over-pushing, conflict with real request for the same degrading performance
- Chrome ended up removing
server pushin 2022. Community says it’s only suitable for certain usecases. Has Early Hints as an alternative. - HTTP/2 Push is dead | HTTP/2 upload speed | Why HTTP/2 is slower than HTTPS?
HTTP/3
- HTTP/3 is
HTTP/2-Over-QUICby design (Analogy) - HTTP/3 is the version of HTTP that uses
QUICand does not suffer from HOLB. - Advantage of HTTP3 is that you only need to block the affected streams while retransmitting unlike HTTP2 where you need to block all streams.
- Requires CA based TLS to set up a connection.
More on QUIC for HTTP3
- Idea of using UDP for QUIC is that, TCP’s handshakes and acknowledges are redundant when you have it all anyway on L7, so they choose a simpler UDP as transport and re-implement handshakes and acknowledges in their applied protocols.
- QUIC is over UDP for backwards compatibility, it was going to be its own protocol
Headers
- Case does not matter
Structured Header Fields
- HTTP defines header values as a “sequence of octets” (i.e. bytes) with few constraints.
- Should be ASCII
- Should be defined in ABNF (Multiple fields with the same name can be combined on the same line if you separate their values with commas)
- Structured header fields offer a better way. See Improving HTTP with structured header fields | Fastly
Security Headers
If your webserver does not allow you to set these headers, you can also use intermediaries such as cloudflare to help you add these. Also see Everything you need to know about HTTP security headers
Content-Security-Policy- See CSP for details
Strict-Transport-Security(HSTS, See TLS)Public-Key-Pins(HPKP)- This is deprecated now in favor of things like Certificate Transparency(CT)
- Tries to solve for the case when two CA, issue certificate for the same domain, and could lead to MITM. who to trust?
X-Frame-Options- Can have values
DENY,SAMEORIGINandALLOW-FROM <website_link> - See Same Origin Policy (SOP) and iframe
- Can have values
X-Content-Type-Options-
This solves
MIME sniffing,MIME sniffingis a browser feature! -
Using
nosniffdisables browsers from trying to guess the content type of a document if for whatever reason it wasn’t specified. -
So good practice to explicitly provide
Content-Typeheader -
Attack example from chatgpt
Let’s say you have a web page that allows users to upload images. However, an attacker might try to upload an image that is not actually an image file but instead a JavaScript file, pretending to be an image. Without the X-Content-Type-Options nosniff header, some browsers might try to interpret the file as a script and execute it, leading to a potential cross-site scripting (XSS) attack.
-
Referrer-Policy- Referrer policy defines the data that can be included in the
Refererheader. (Yes,Refereris a mis-spelling) Refereris arequestspecific header and is sent by the browserReferrer-Policyis aresponseheader and is sent by the webserver- Browsers will look at the
Referrer-Policyand then decide what to send in theRefererheader. - Instead of specifying
Referrer-Policyas part of the HTTP response, it can also be part of HTMLno-referrerfor meta tagsnoreferrerfor other tags
- Referrer policy defines the data that can be included in the
Other interesting headers
Content-Disposition- See Content-Disposition - HTTP | MDN
- This controls whether the file is downloaded or shown inline in the browser
- This alternately can also be set in the
<a>tag in HTML
Range
- Eg. Someone built a sqlite VFS based on HTTP Range requests
- Not compatible with HTTP Compression
Features
Compression
Caching
See Caching Tutorial for Web Authors and Webmasters
Types
- Browser/Private: The cache in your browser
- Proxy: The cache your ISP uses
- Gateway: CDNs/ Reverse Proxies
State of representations(objects subject to cache)
The idea of freshness and validity are related, both are important for caching, if mechanism for validity is absent, there will be no caching!
-
Fresh
- can send to client w/o checking w
origin exp_time/agewithin fresh period- recently added to cache even if modified time was long ago
- Good cache systems will re-fetch data from origin when things change from
freshtostale, eg.exp_timepassed and no user intervention. - Based on certain headers, a cache may always
verifywith withoriginregardless of other indicators offreshness. (Useful to assure that authentication is respected etc.)
- can send to client w/o checking w
-
Stale
Stale (cache needs to ask
originto validate it)- A cache will serve stale data if not able to verify with origin
- If stale data is validated by origin it’ll be again considered fresh, else new actual fresh data will be put into the cache
-
Un-cachable
- If no
validatorexists. (Eg.ETag/Last-Modified)
- If no
Freshness related Headers
| Value | Freshness | Validity | Priority | |
|---|---|---|---|---|
Cache-Control | Multiple pre-defined values | X | X | 0 (most) |
Expires | Date(GMT) | X | 1 |
Expires- How long the associated representation is fresh for
- Clocks on the Web server and the cache must be synchronised for expected results
- We must not forget to update the value of
Expireson the origin before it passes, otherwise request will be stale and will keep hitting origin forever. - Caching static stuff, automatic periodic update of cache (also applies to
max-agein cache-control headers) - Can’t be circumvented; unless the cache runs out of room, the cached copy will be used until then! (only way out will be to purge cache somehow or change url)
Cache-Control- Improves on
Expiresto give more control (Esp.max-age) - Has multiple options that affect both
freshnessand whenvaliditychecks with origin are done. (Eg.no-cache+publicis good for authenticated requests) no-cachemeans it’ll verify on every req. i.e we still get cached data but it’s ensured that it’s fresh.no-storeis absolutely skip the cache for everything.must-revalidateis like a flag for maintainstrict freshness!- Options

- Improves on
Validation related Headers
| Value | Priority | |
|---|---|---|
Etag | 0 | |
Last-Modified | DateTime(GMT) | 1 |
Last-Modified- Eg.
curl -I --header 'If-Modified-Since: Tue, 11 Dec 2023 10:10:24 GMT' http://poop.com/faq/ - Cache system can use a If-Modified-Since to query for validation.
200if new data,304if no change in data, i.e data in cache is still fresh. - If-Unmodified-Since also works but its semantics and usage is somewhat different and works with
POST- Helps solve the “Lost Update Problem” where the last write may overwrite a previous write to a resource. (This is like poor man’s crdt ?)
- Useful with
Rangerequests, i.e to ensure we’re fetching chunks from the same document.
- Eg.
E-tag- Generated by the server and changed every time the representation does.
- Cache system can use a If-None-Match to query for validation.
200if new data,304if no change in data, i.e data in cache is still fresh. E-tagis weak comparison, i.e the actual content may have changed but if we don’t update the etag properly, it’ll still seem fresh from cache’s side.- Can be
e-tagoretagin the header - More resources
Content negotiation
Content Length
HTTP Streaming
See Multipart Upload and HTTP Streaming
HTTP Live Streaming
HTTP Range requests
- “been exploring serving large SQLite databases in chunks and querying them with http range requests to prevent downloading the entire database. It’s pretty awesome!” (See sqlite)
- Alternative which is not as good: Transfer-Encoding - HTTP | MDN
HTTP Synchronization (WIP)
Timeouts
Idle Timeout
- This comes into play when you have a network appliance such as a Load Balancer in between your client and server Eg.
client <> LB <> Backend/server - Example scenario
- Client sent a request to server and is waiting for a server response.
- But this request goes though the LB first
- LB has set a idle timeout of
300s 300spasses by, LB times out the connection. Closes the connection.- At this point, neither client nor server is aware that this happened
- At this point the server is still processing the request, client is still waiting
- Server finishes processing data after
300s- Now server tries to transmit the response back to the client
- Server receives an RST packet(unexpected TCP packet arrives at a host) from the LB, notifying that the connection is closed.
- The server just wasted resources
- Client is still waiting
- It’ll keep on waiting until some client side code timesout
Relationship of Idle timeout and HTTP Keepalive
- Idle timeout is important to make sure that stale connections are destroyed in a timely manner.
- But sometimes we want to wait for certain server responses longer than the
idle timeoutin the LB- Eg. If a request actually takes
>300s. - In those cases we can use
keep-aliveandkeep-alive-timeouts
- Eg. If a request actually takes
-
HTTP Keep-Alive
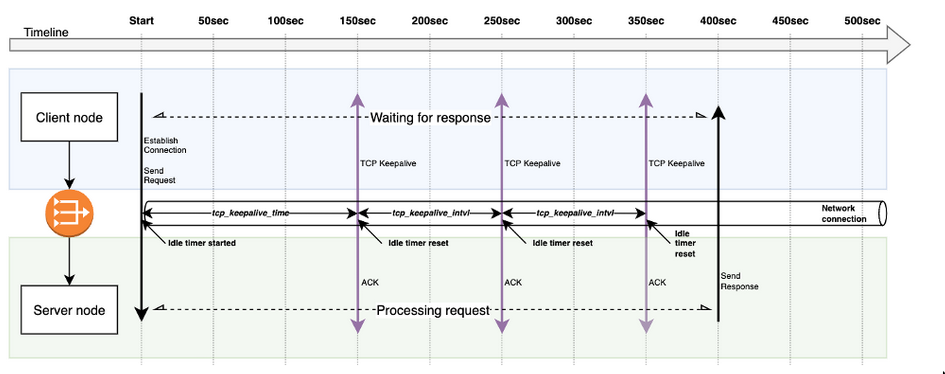
How it works
- Keepalive probe is sent with no payload Length 0 (Len=0) and a Sequence number (Seq No)
- The Seq No. is expected Seq.No subtracted by 1
(SEG.SEQ = SND.NXT-1) - The remote node simply ACK the packet, since the segment was mimicking a retransmission of another previously acknowledged segment.
- This ultimately results in the connection not being
idleand theidle timeoutin the LB does not occur. i.e it triggers aidle conn. timer resetfor the LB.
- HTTP Keepalive prevents connection from being closed due to idle timeout.
- i.e keepalive signal can be used to indicate the infrastructure that the connection should be preserved.
- This is also sometimes called
persistent connection(Connection: keep-alive). This is default in HTTP1.1, so you don’t really need to specify this. - HTTP Keep Alive allows
pipelining, but keep-alive and pipeline are two different things. Like mentioned before pipelining is not widely supported.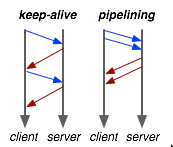
- HTTP/2 doesn’t need this because it by design uses something that improves on this.
- It allows us to use the same TCP
connectionfor multiple HTTPrequests. i.e(new(r)/same(c)) x N - As requests are joined by concat, we need to know where request starts and ends.
- Header section is always terminated by \r\n\r\n
- Specify
Content-Lengthheader - OR Specify
Content-Encoding: chunked, when streaming and length is not known.
- Example from jamesfisher’s blog
cat <(printf "GET /status/200 HTTP/1.1\r\nHost: httpbin.org\r\nConnection: keep-alive\r\n\r\n") \ <(printf "GET /status/200 HTTP/1.1\r\nHost: httpbin.org\r\nConnection: close\r\n\r\n") \ | nc httpbin.org 80
Best practices for Idle Timeout(LB&Application) & Keep Alive
- See Reverse Proxy, HTTP Keep-Alive Timeout, and sporadic HTTP 502s
Upstream (application) idle conn timeout > Downstream (lb/proxy) idle conn timeout- If we don’t do this,
upstream/applicationcan close the connection before the downstream/b considers the connection idle.- The LB will then try to re-use the connection and instead of
ACKit’ll getFIN/RSTfrom the upstream. - i.e In upstream(app server) timeout, LB will get a
FIN/RSTfrom the upstream.
- The LB will then try to re-use the connection and instead of
- In these cases LB will respond with
5XXto the client. Then it seems like the issue was in LB but the issue was in the upstream closing the connection while LB still thinks its valid.
- If we don’t do this,
- Use keep-alive between
client<>lband prefer not to have it betweenlb<>upstream- See nginx - Do HTTP reverse proxies typically enable HTTP Keep-Alive on the client side of the proxied connection and not on the server side? - Server Fault
- But proxies often keep the upstream connections alive too. This is a so-called connection pool pattern when just a few connections are heavily reused to handle numerous requests.
- See nginx - Do HTTP reverse proxies typically enable HTTP Keep-Alive on the client side of the proxied connection and not on the server side? - Server Fault
- See if SSE / WebSockets / HTTP/2 are better alternatives to keepalive
HTTP Keep alive vs TCP Keep alive
These two ofc can and are being used together, but they’re different things.
| TCP Keepalive | HTTP Keepalive | |
|---|---|---|
| Layer | L4 | L7 |
| Setting | OS level | HTTP headers |
| Use | Connection health, if conn. is alive, dead peers, keep the conn. open | Connection reuse, send multiple request/response pairs over the same TCP connection. |
Going Deeper
Making a raw request
# netcat usage to make a HTTP/1.1 req
$ printf 'HEAD / HTTP/1.1\r\nHost: neverssl.com\r\nConnection: close\r\n\r\n' | nc neverssl.com 80
# NOTE: \r\n is known as CRLF(Carriage Return + Line Feed)Host field
TODO: IDK what is the type of Host, what it is actually, i understadn what it does tho.
Host: neverssl.com- With this, we can now host different websites at the same IP address
- But not all servers check it! So you can set
Hostand whether it gets used or not totally depends on the server.
TODO: How is this different from SNI?
Resources
RFC
- The HTTP core RFCs
- Semantics: https://www.rfc-editor.org/rfc/rfc9110
- Caching: https://www.rfc-editor.org/rfc/rfc9111
- HTTP/1.1: https://www.rfc-editor.org/rfc/rfc9112
- HTTP/2: https://www.rfc-editor.org/rfc/rfc9113
- HTTP/3: https://www.rfc-editor.org/rfc/rfc9114 (QUIC: https://www.rfc-editor.org/rfc/rfc9000)
QUIC
- RPC vs TCP (Redux) - by Larry Peterson - Systems Approach
- It’s TCP vs. RPC All Over Again - by Larry Peterson
- QUIC Is Not a TCP Replacement - by Bruce Davie
- Chris’s Wiki blog/web/AvoidingHTTP3ForNow
WG
- Source of truth: https://httpwg.org/specs/
- QUIC WG: https://quicwg.org/
Other
- HTTP Field Name registry: https://www.iana.org/assignments/http-fields/
- Caching tests: https://cache-tests.fyi/
Keep hearing these terms, dn what
- Header and trailer fields
Compression
Future areas of focus
These are areas where the WG is more active of recent
Privacy
- MASQUE enabled UDP tunnels. This enhances HTTP.
- MASQUE along with IP Tunneling can possibly have us MASQUE VPN. Also check OHTTP
Security
- Replaces
digestheader https://httpwg.org/http-extensions/draft-ietf-httpbis-digest-headers.html - Formalizes Message signatatures: https://httpwg.org/http-extensions/draft-ietf-httpbis-message-signatures.html
- Cookie spec revised: https://httpwg.org/http-extensions/draft-ietf-httpbis-rfc6265bis.html
Others ideas being explored
- HTTP over Websockets and Web Transport
- QUERY (GET w body)
- Resumable Uploads