tags : Distributed Systems, Database, Caches, Database Transactions, DB Data Modeling
FAQ
TODO Data Layers?
NOTE: This is just for my understanding
- Storage Layer: S3, Parquet, Other file types
- Transaction Layer: Open table formats, eg. Delta Lake
- Semantic Layer : Cube (This is new kid, an enhancement)
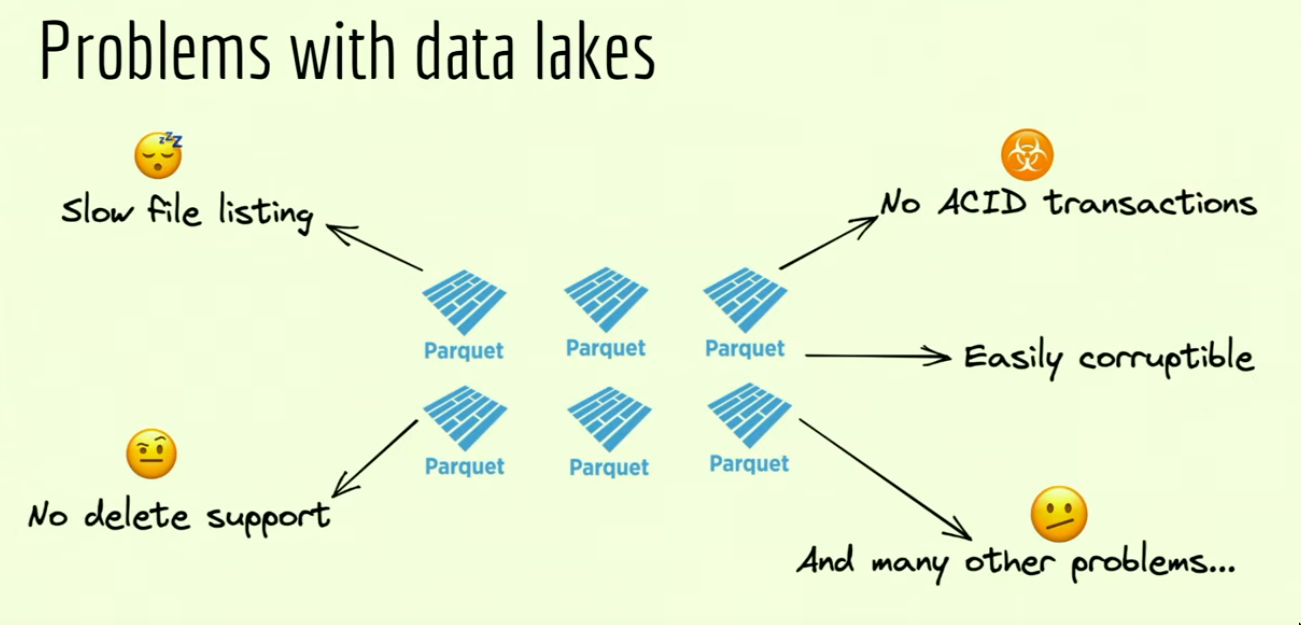
File listing problem in Data lakes
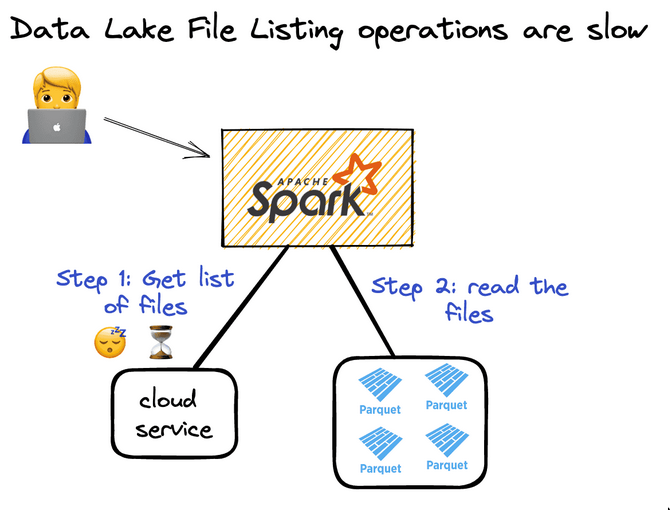
- When you want to read a Parquet lake, you must perform a file listing operation and then read all the data. You can’t read the data till you’ve listed all the files.
- With delta lake, because of the transaction log, we can avoid file listing and get the path directly.
Access patterns and Performance
File skipping
-
Column Pruning
- Unlike CSV, with parquet we can do column pruning.
-
Parquet row-group Filtering
- Parquet file is split by
row-groupby format. - Each
row-grouphas min/max statistics for each column. - We can filter by
row-groupfor somecolumnbefore we load the data, after which we apply our actual application filtering logic.
- Parquet file is split by
-
File filtering
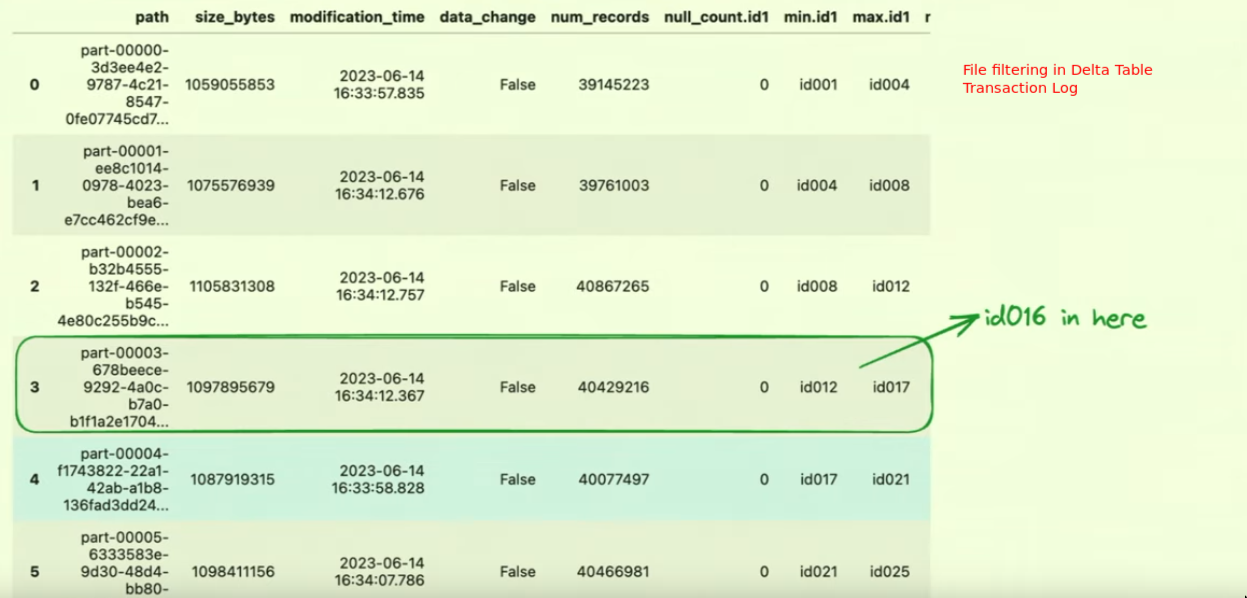
- Parquet doesn’t support file-level skipping
- This can be done with Delta Tables, we still add the
row-groupfilter but additionally do file based filtering. - Because of the transaction log, we get even better results than simple row-group filtering in plain parquet file with file level skipping.
-
Partition pruning/filtering
- This assumes you’ve partitioned your data correctly
- The more partitions you can “prune” or hone in on the less files and data must be scanned for matches.
-
Partial reading / Predicate pushdown
- See Optimizations - Polars
- You want to push down your filters and selections to the file reader.
- You can imagine that arrow is file reader in that situation and what you want is to give to that reader as much information what you need in order to skip loading into memory.
- This is possible because of the parquet file specific metadata representation which allows the reader to skip data.
- This is possible in object store using HTTP range requests, and the query engine being able to calculate offsets based on metadata etc.
Compaction and Defrag
- Compaction
- Will compact small files into bigger one. Will increment a version.
- See Small file compaction
- Defrag
z-ordering, will co-locate similar data in similar files.- Z-order clustering can only occur within a partition. Because of this, you cannot Z-order on fields used for partitioning.
- Z-order works for all fields, including high cardinality fields and fields that may grow infinitely (for example, timestamps or the customer ID in a transactions or orders table).
Partitioning
- Partitioning is the way to break big data up into chunks, logically and physically. Commonly things are partitioned over dates.
- Partitioning works well only for low or known cardinality fields (for example, date fields or physical locations) but not for fields with high cardinality such as timestamps. (See z-ordering)
- To check cardinality, you can try listing the number of distinct values per column.
-
When do we need Partitioning?
- Databricks: When data > 1TB, but depends on the data.
- Delta Lake: You can partition by a column if you expect data in that partition to be at least 1 GB.
-
Partitioning in Delta Lake v/s Hive Style Partitioning
- When to partition tables on Databricks | Databricks on AWS
- Apache Hive-style partitioning is not part of the Delta Lake protocol, and workloads should not rely on this partitioning strategy
What about Databricks?
- Databricks has some optimizations such as ingestion time clustering which won’t be there if you’re using open source version of delta lake. We can get creative and find ways to optimize this based on our data, maybe with partitions or by other needs, whatever necessary.
General recommendations
- Data processing engines don’t perform well when reading datasets with many small files. You typically want files that are between 64 MB and 1 GB. You don’t want tiny 1 KB files that require excessive I/O overhead.
What’s the evolution like?
Data cleaning tools
- This is a slight enhancement
- You can always do data cleaning using the standard library methods of the language you’re using. (Eg. using optional chaining / coalesing etc)
- But there are certain libraries/processes which can maybe make the data cleaning processes simpler/easier to write and maintain/extend etc.
- These tools can be especially useful when the response object is not guaranteed to be the exact same and you need some verification around that X,Y,Z field exists etc etc.
- In
R, you have tools such as: A Grammar of Data Manipulation • dplyr - In Javascript, you have tidyjs but it suffers issues, even loadsh can help a bit i guess but at that point just use optional chaining maybe
- Now for this I thought we can use effect/schema or zod for that matter and split it into 2 steps as mentioned here:
- The first model should capture the “raw” data more or less in the schema you expect from the API.
- The second model should then reflect your own desired data schema.
- This 2 step process helps debug the pipeline if ever needed. Applies to other validator in other languages like pydantic(python) aswell.
- Now for this I thought we can use effect/schema or zod for that matter and split it into 2 steps as mentioned here:
- But for this job, I’d personally prefer python+pydantic. Goes good together.
- Some resources
- Some other tools
- Another thing handle data cleaning at the application level if possible and not at the db level. You should always enforce proper constraints if its structured data but most of the data might be unstrutured and we might want to store it in JSONB columns etc.
Data pipeline
Point of data pipeline is to generate/maintain data assets (Tables/Files/ML models etc)
Data Warehouse and Data Lake
See Data systems built on Object Store
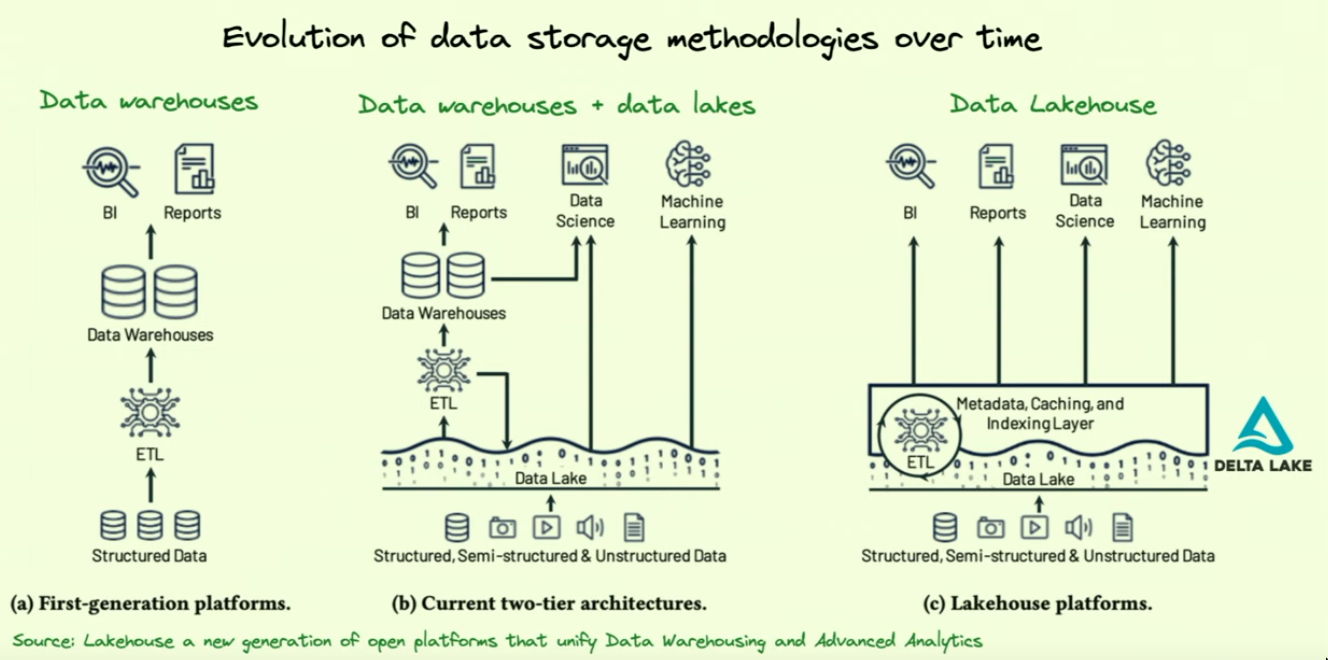
Data warehouse (Analytics, Structured Data)
- Exists because we have different sources
- OLTP source of truth database, but you also have SaaS products, events, logging exhaust, and honestly probably some other OLTP databases
- Warehouse provides value because it brings together data that otherwise could not be jointly queried.
- Traditionally used for analytical, but usecases for operational queries are also there
- Must take care of workload contention so what analytical workload on the warehouse doesn’t affect operational data which needs freshness.
- Must separate the storage from the compute to scale.
- Tools like DBT help interact with/build DW
Analytical
- Designed to grind through reams of historical data and efficiently produce periodic reports.
- Eg. snowflake, can be duckdb, can even be a bash script for that matter
Operational
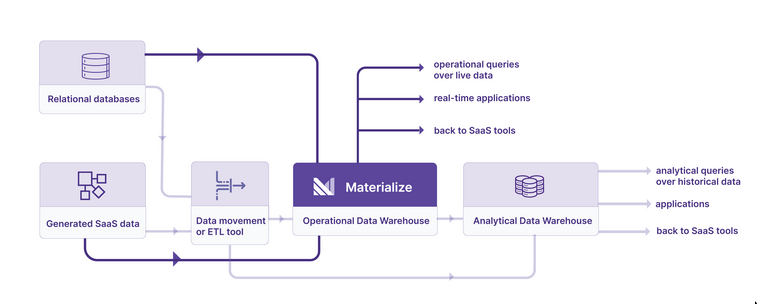
- Designed to ingested data continually and make it immediately available to query
- This is not a popular thing yet but Materialize is trying to do something around it. It uses some Streaming technology.
Data Lake (Storage, raw/unstructed/structured data)
- Throw data into files like json, csv, parquet into a storage system like s3
- This is also supposed to handle un-structured data like text, images, videos etc.
- Eg. Parquet data lake: likely has a partitioning strategy that has been optimized for your existing workloads and systems.
Data Lakehouse
- Combining
- Analytics strengths of the Data warehouse
- Scalability and inexpensive storage of the Data lake
- Data warehousing principles applied over data in a data lake.
- Open Table formats / Lakehouse storage systems
- Delta lake: Uses delta (open table formats), a parquet data lake can be converted into a delta lake. Additionally delta can store unstructured data as-well.
- Apache Hudi
- Iceberg
Integration Tools
- Zapier & N8N mostly focus on internal integrations.
- For example, connecting your own Hubspot account with your own Google sheets account.
- iPaaS : https://blog.n8n.io/ipaas-vendors/
- Nango & Merge focus on product integrations.
-
E.g. Connecting your customer’s HubSpot account to your own SaaS product.
-
https://www.nango.dev/blog/finding-the-best-unified-api, https://www.merge.dev/, https://unified.to/
-
The nango idea
When the unified data model covers the objects & data you need, it makes you faster.
But it also inherently limits the data you can access from the external APIs: A unified API only makes sense for the objects & data that are available in all, or most, of the APIs it abstracts. This subset can be surprisingly small (e.g. CRMs all have their different flavor and different data models).
If you need something other than what the unified model provides, you’ll essentially end up building the integration yourself again, working around the platform.
This can be problematic if your (future) customers want an integration that the unified API doesn’t support. It also doesn’t work well if your customers expect deep integrations with some key APIs: E.g., Workday is the #1 HRIS in Enterprise, Salesforce for CRM, Netsuite in accounting, etc. If 70% of your customers are on Salesforce(/Workday/HubSpot/Netsuite/etc.), you probably need an excellent Salesforce integration that covers Salesforce-specific features.
This is why we took a different approach with Nango:
Instead of pre-building entire integrations, we focused on building a great developer experience to build integrations.
We pre-build the infrastructure you need to work with the APIs: (O)Auth, retries, webhooks handling, data caching, de-duplication, etc. You get full control over the integration (business logic, data model) without learning the intricacies of each API.
-
Technologies
Apache Spark

- An alternative to MapReduce but better
Data formats
- Arrow and Parquet are used together to leverage their respective strengths: Arrow’s efficiency in in-memory processing and Parquet’s effectiveness in on-disk data storage and retrieval.
Parquet (on disk)
- Parquet was created to provide a compressed, efficient columnar data storage format
- Data format that allows querying + metadata along w actual data
- Metadata: Schema info, File level metadata, Column level, custom user level, stats for data skipping etc.
- Grafana Tempo switched from Protocol Buffers storage format to Apache Parquet last year.
- Supports schema and compression, because columnar easier to do compression (processing speed + storage reduction)
- See Delta Lake vs. Parquet Comparison | Delta Lake
-
Format
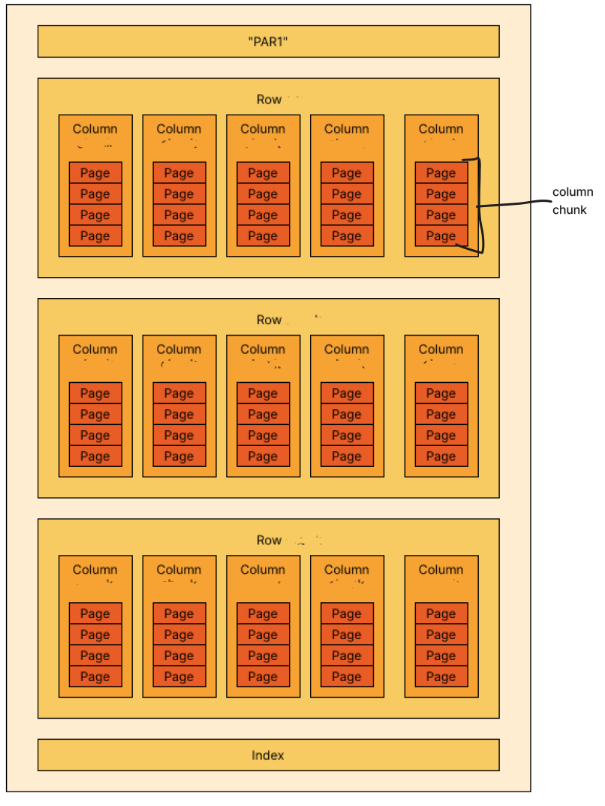
- Hierarchically:
File > row group(s) > Column(s) > 1 column chunk > page(s) - Uses the record shredding and assembly algorithm described in the Dremel paper to convert nested schema to columns.
- Data is stored in batches(“row groups”)
- Row Group = Batch = column(s)
- Each column can contain compressed data and metadata
- By itself does not support
append, i.e parquet files are immutable. See Delta Lake for append.
- Hierarchically:
-
Hive Style Partitions
# writing applications.to_parquet('somedir', schema = my_schema, partition_cols=['INCOME_TYPE']) # reading pd.read_parquet('somedir/NAME_INCOME_TYPE=Working/') # OR ( this does a seq scan for the partition unlike the direct path^) pd.read_parquet('somedir', filters=[('INCOME_TYPE', '=', 'Working')]) # OR pd.read_parquet('somedir') # read the whole thing
Apache Arrow (in memory)
- Arrow is an in-memory data format designed for efficient data processing and interchange.
- Arrow provides the efficient data structures and some
compute kernels, like a SUM, a FILTER, a MAX etc. - Arrow is not a Query Engine
- Its primary focus is to enable fast analytics on big data by providing a standardized, language-agnostic memory format that supports zero-copy reads.
- Makes it possible to exchange a pointer to some memory and other process would be able to read this memory without copy and use further.
- Example of DuckDB and Delta-rs
- Duckdb and deltars(data fusion) “speaks” arrow
- So you can read something in delta-rs and hand it over to duckdb engine in a format that both understand.
Open Table formats
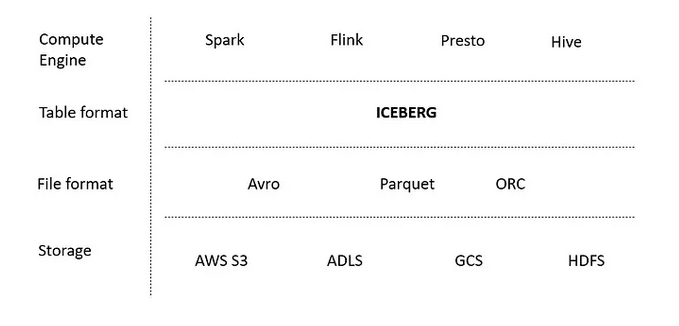
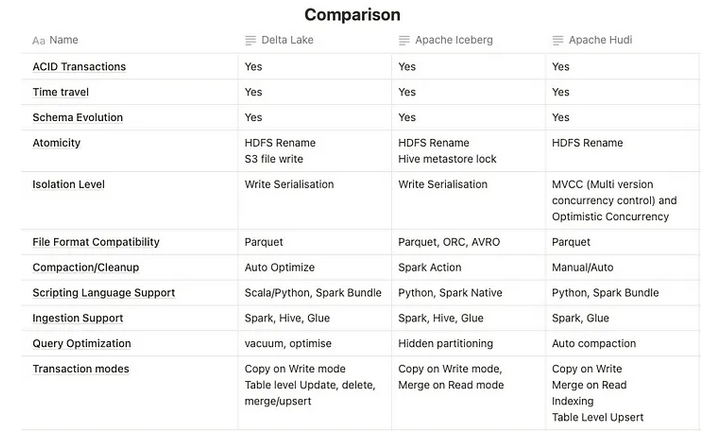 Open table formats such as delta or iceberg were developed to serve the big data engines, such as spark or flink. But this is slowly changing as Delta Lake is slowly becoming agnostic and now can be accessed from polars and DuckDB aswell.
Open table formats such as delta or iceberg were developed to serve the big data engines, such as spark or flink. But this is slowly changing as Delta Lake is slowly becoming agnostic and now can be accessed from polars and DuckDB aswell.
Delta Table/Lake
- Delta “Table/Lake” are interchangeable
Delta Lakeis used to implement the Databricks lakehouse.- It is the “transactional layer” applied on top of the data lake “storage layer” via the transaction log.
- Allows for ACID capabilities (see Database)
- Delta Lake features break assumptions about data layout that might have been transferred from Parquet, Hive, or even earlier Delta Lake protocol versions.
-
What?
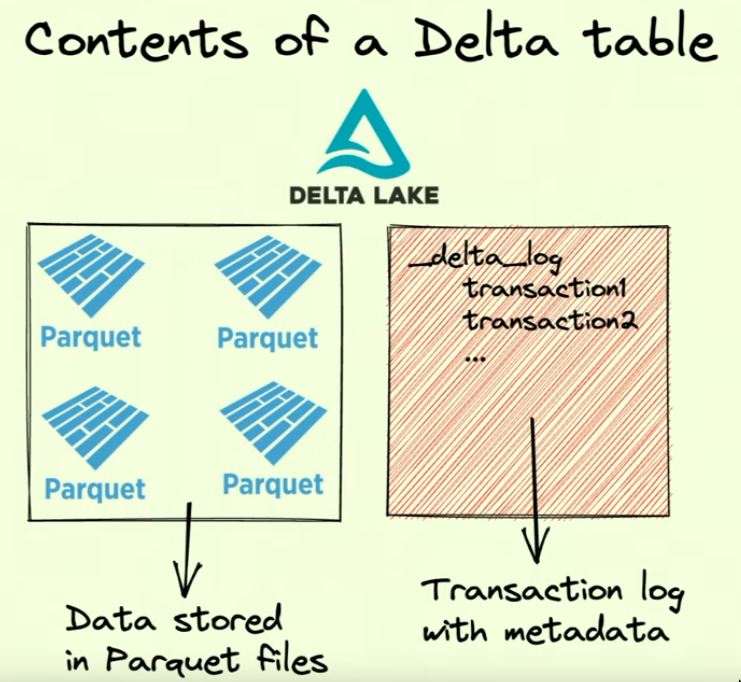
- It is a folder with
- Many parquet files, which are normally just added
- A transaction log folder with metadata. (Storing metadata in transaction log more efficient than storing it in the parquet file itself?)
- These parquet files build up our last version of the tables.
- You can imagine that readers and writers add and delete parquet files and are synchronized over the transaction log folder.
- It is a folder with
-
Why?
- If we just have simple parquet files in our data lake, we’d have to write additional logic for upsert/merge etc. But with using something like Delta Lake, this becomes simpler.
-
How
See Delta Lake
Dataframe libraries
Polars
More on Polars
- Polars can inter-operate with other data processing libraries, including PyArrow. (Note pyarrow and arrow itself are different and polars plays well with both)
- Polars merely uses arrow2 as its in-memory representation of data. Similar to how pandas uses
numpy. But on top of arrow2, polars implements efficient algorithms for JOINS, GROUPBY, PIVOTs, MELTs, QUERY OPTIMIZATION, etc. - You can convert data between Polars dataframes and other formats, such as Pandas dataframes or Arrow tables
- I wrote one of the fastest DataFrame libraries | Ritchie Vink
- It works nicely with DuckDB
DataFusion
DataFusion and Polars are like two sides of the same Rust coin: DataFusion is built for distributed, SQL-based analytics at scale, serving as the backbone for data systems and enabling complex query execution across clusters. Polars, on the other hand, is laser-focused on blazing-fast, single-node data manipulation, offering a Python-like DataFrame API that feels intuitive for exploratory analysis and in-memory processing.
Pandas
- Uses numpy as its data representation
Dagster
Local agent
- Whereever this agent is running, actual workload code would run in the same env
- There’s Dagster OSS and Dagster+ (+ is the better offering and does not make use of the
workspace.yamlfile)
Code location
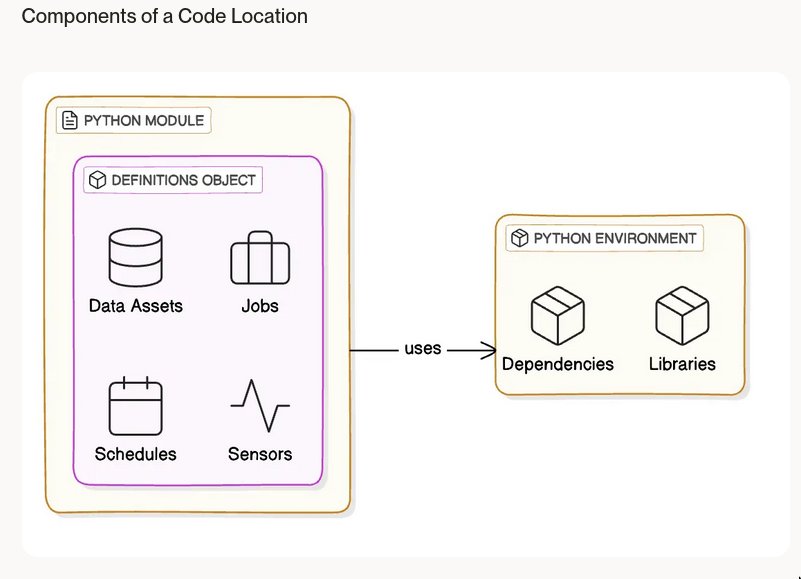 It can be a local file, or container image etc
It can be a local file, or container image etc
-
What?
- Organization: Helps in organizing and managing the code that defines your data assets and pipelines
- Exact entity: Reference to a specific Python module containing an instance of
Definitions, which encapsulates your data assets, jobs, schedules, and sensors. - Environment: Includes the Python environment required to load and execute this module.
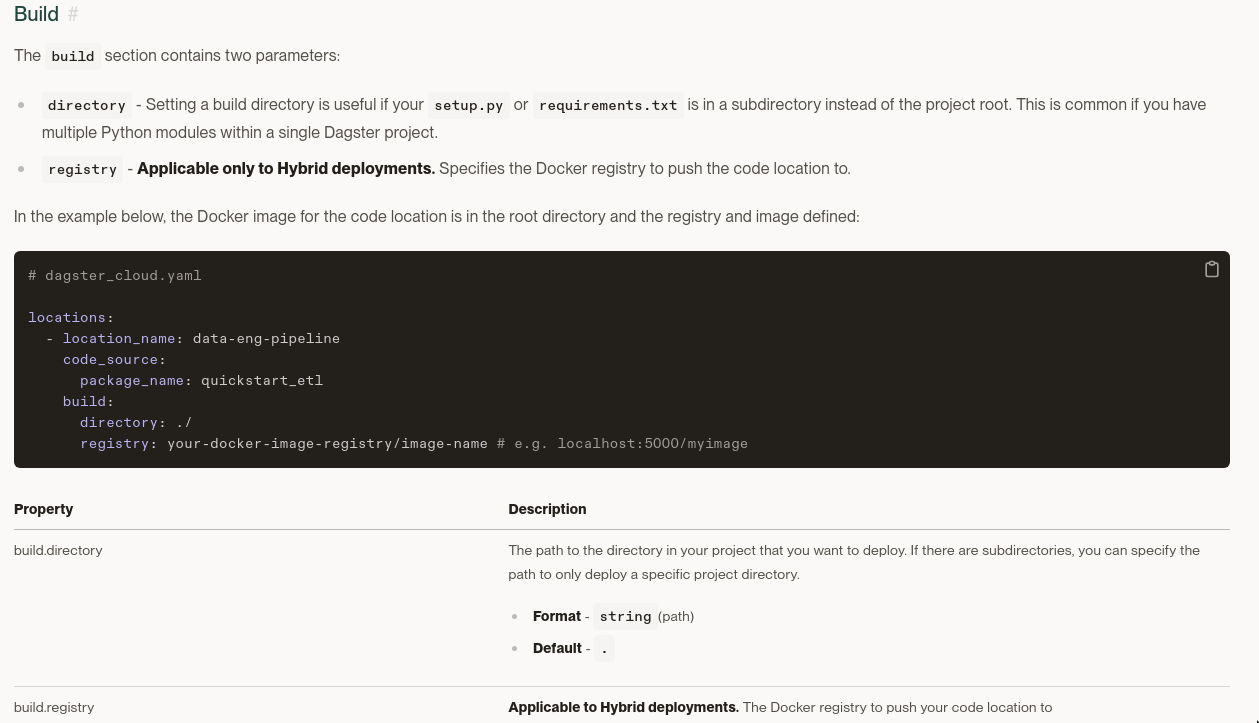
Building the imageo
We’re not using this, we’re building image in github actions
ETL
Meta Ideas about ETL
ETL or ELT?
- Combination of cheap storage + easy to run compute = switch from ETL to ELT
- In ELT, everyone just dumps the raw data and then does all the cleaning/transforming there with SQL.
Singer Spec (EL protocol)
- Singer is an open-source project/protocol that provides a set of best practices for writing scripts that move data.
- Singer uses a JSON-based specification for defining how data is extracted and load(
EL), and it has a growing ecosystem of pre-builttapsandtargetstaps: For extracting data from various sourcestargets: For loading data into different destinations
- Issue with Singer is tap/target quality. The spec itself is fine, but the tap/targets written by the community need to be more standardized.
- Singer is also a CLI tool??
Reverse ETL? (confirm?)
- This is basically creating operational/transactional database records from analytical db
Data Pipeline Frameworks (for EL, Extract and Load)
| Name | Singer? | OSS/Selfhost? | Cloud/Paid? |
|---|---|---|---|
| Stitch | YES | NO | YES(less) |
| Meltano | YES | YES | Not Yet |
| PipelineWise | YES | YES | NO |
| Fivetran | NO | NO | YES(very) |
| Airbyte | NO | YES | YES |
| Hevodata | NO | NO | YES |
- Cloud offerings usually have orchestration built in, so need not worry about that.
- Lot of Meltano extractors/loaders are airbyte wrappers
Singer spec based
-
Stitch
- Stitch obviously gets a lot of use out of Singer,
- Stitch, of course, inherits all of Singer’s problems, since it uses Singer.
-
Meltano
- Implementation of the
Singer spec - Singer SDK: Allows you to create a
tapandtargetsfor some sources, without groking the Singer spec. This tries to overcome issues about quality of taps/targets. - Meltano also inherits all Singer issues.
- Implementation of the
-
PipelineWise
- Not very popular but is in the same bucket
Airbyte
- Airbyte data protocol (still compatible with Singer’s one so you can easily migrate any tap to Airbyte)
- Trying to build a better standard and connector ecosystem than Singer.
- Doesn’t have an official CLI, everything happens over API calls. For automation, suggests a terraform provider.
Fivetran
- Fivetran is an ELT tool and a direct competitor to Stitch
DltHub
dltis new kid in town- When using with dagster, a `dlt` pipeline would be a dagster asset
- You can use singer taps with dlt, but it makes for a bad experience.
- dlt is upstream of dbt, dlt loads data, dbt transforms it.
- But they’re sort of leaning of gpt for some reason, I don’t understand why
Data Transformation Frameworks
Examples
-
DBT (T, Transform)
- Working isolated on a database server was complicated. A solution was introduced with dbt.
- Writing, versioning, testing, deploying, monitoring all that complicated SQL is very challenging. This is what DBT is good for. DBT doesn’t replace SQL, it simply augments it by allowing you templatize, modularize, figure out all the inter-dependencies, etc.
- Why DBT? You would generally use dbt as a transform framework for the same reason you’d use Ruby on Rails or Django etc as a web framework
- The unreasonable effectiveness of dbt
- Analogy (with MVC, See Design Patterns)
- Model : source
- Controller : ephemeral model
- View : materialized (view, table, incremental) model
- DBT Gotchas
- The filename in the
models/directory is thetable namethat the select statement will write to - Currently only works with
.ymlfiles, not.yaml - DBT is not a EL/Ingestion tool, the
sourceandtargetneed to be in the samedatabase. i.e, You can’t transform data from PostgreSQL to DuckDB, you’d have to do the loading/ingestion step separately and then in whichever DB preferable, you do the transformation. After the transformation is done, we can decide where to store the transformed data, i.e thetarget
- The filename in the
-
SQLMesh
- GitHub - TobikoData/sqlmesh : Better alternative to DBT??
Anomaly detection
- https://github.com/Desbordante/desbordante-core
- Great expectation etc
- See Tabular Data
Processing/Ingestion Types
While batch/stream processing and batch/stream ingestion are two completely different things, this section talks all of it in general.
Batch processing
- See Batch Processing Patterns
- Ingesting data that’s run daily and dumping into a bucket can be a batch operation
Stream processing
- Streaming use cases are defined by the consumption SLA of the data, not the production. 🌟
- This can mean different things for different people, eg. for some ingestion pipeline, streaming might just means anything ingesting more often than every ten minutes.
Update patterns
See https://docs.delta.io/2.0.2/delta-update.html#-write-change-data-into-a-delta-table
CDC
SCD Type2
Problems / Challenges
- De-duplication
- Schema drift, column type change in source
Storage
See Storage, Object Store (eg. S3)
Related Topics
Information retrieval
Caching related problems
Hotspots
- Horizontally scaled but shit going to the same node. UUID instead of incremental primary key would be a saver.
Cold start
- If cache crashes, all high traffic goes to db and db can crash again, so we need some way to warm up the cache beforehand
TODO Layered architecture
There is no one fits all architecture that makes sense for all situations. In fact it is mostly the opposite. The role of an architect is to know how to pick and choose patterns/technologies/methodologies to best solve a problem. The worst architects know one way of doing things and force it into every situation.
The medallion architecture is one way to architect a data flow. Sometimes 3 stages is good. Sometimes you just need one. Maybe some complicated ones need 5. Also the stages don’t necessarily need to be physically separate. A silver layer consisting only of views is perfectly valid.
And for the love of money don’t call the layers bronze, silver and gold. I’ve moaned before about it, it is meaningless to users/engineers… like calling 1, 2 and 3. Give the layers meaning to what you intend to use them for. Raw, validated, conformed, enriched, curated, aggregated … people will know exactly what that layer means just by the name.
- Reddit users
Medallion architecture
bronze/raw/staging/landing- for data you have little to no control over, like data imported from external sources
- We may or may not retain these
silver/intermediate/transform- your main work area, the bulk of tables go to this layer, little to no guarantee about forward/backward compatibility with external systems
- Minimal conversion to Delta Table. Minimal or no typing. Append only, may add columns for source file metadata or date or batch job id to rows. Will grnerally be 1/5th size of raw
gold/final- data that you expose to external system: optimized for queries, strict schema compatibility, etc
How many layers to have?
- Sometimes you might just need
bronze->gold, sometimes the problem might demand something more than these 3 layers etc.
What format should data be in each layer?
- The format could be anything, typical convention is raw will have parquet/json etc. Silver will have something like delta table etc, and gold will be some fast query db etc.
- But all of these 3 could be the same too. Eg. all of the 3 could be different postgres tables, all 3 could be delta lake tables.