tags : System Design, Systems, Inter Process Communication, Database, Concurrency, CALM, Clocks
Important links
- Foundational distributed systems papers : O’ double G
Theory
Predicate Logic
See Logic
- safety properties (next, stable, invariant)
- liveness properties (transient, ensures, leads-to, variant functions).
Formal tooling
See Formal Methods
What/Intro
A “distributed system” is simply a system that splits a problem over multiple machines, solving it in a way that is better, more efficient, possible etc than a single machine.
Use of the distribution
Use of the distribution provided by distributed system
- Can be used to provide fault tolerance and high-availability
FAQ
What Eventual Consistency?
How to Design Distributed Systems?
- A correct distributed program achieves (nontrivial) distributed property
X - Some tricky questions before we start coding:
- Is
Xeven attainable?- Cheapest protocol that gets me X?
- Can I use something existing, or do I invent a new one
- How should i implement it?
- Is
- We depend on the different entities participating in the distributed system on having some local knowledge
Thinking frameworks
Meta
- CAP and PACELC help us know what things we need to be aware of when designing a system, but they’re less helpful in actually designing that system.
- CALM provide a way to reason through the behavior of systems under Eventual Consistency
CAP
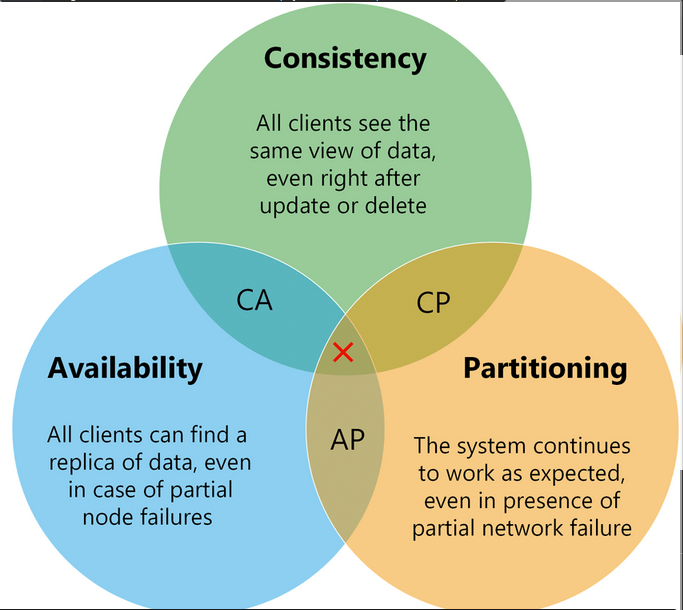
- See An illustrated proof of the CAP theorem (2018) | Hacker News
- Systems can do 2 of the 3, Eg. Abandon C(onsistency) but maintain (A)vailability and (P)artition tolerance.
- When talking about CAP we have to make a difference between
- The original CAP Conjecture
- The subsequent CAP Theorem
The pillars
- Consistency
- Requires that there’s a total ordering of events where each operation looks as if it were completed instantaneously.
- Linearizability is what the CAP Theorem calls Consistency. (See Concurrency Consistency Models)
- Availability
- All requests eventually return a successful response eventually.
- There’s no bound on how long a process can wait.
- Brewer: If a given consumer of the data can always reach some replica
- Gilbert & Lynch: If a given consumer of the data can always reach any replica
- Partition Tolerance
- Some subset of nodes in the system is incapable of communicating with another subset of nodes.
- All messages are lost.
- Partition Tolerance is the ability to handle this situation.
Case of “total availability”
- Total availability is not something that most datacenter applications care about.
- Mobile, IoT, and other frequently-disconnected applications do care about it.
Real World
-
CA
- Partition,
PWILL ALWAYAS BE THERE - You can’t really be
CA, Even though CAP says we can only choose 2, in real world though we can’t really ignore partition tolerance because network can always fail. - So since
Pis not optional in reality, systems make tradeoff betweenCandA. i.e Improve Consistency but weaken Availability and vice-versa.
- Partition,
-
AP & CP
- C and A are treated as more of a sliding scale. So systems can be
APorCPbut this is not the right way to think about Distributed Systems.
- C and A are treated as more of a sliding scale. So systems can be
PACELC
- Partitioned(Availability, Consistency) Else (Latency, Consistency)
- PACELC is a more nuanced than CAP for thinking about this stuff
- Definition
- If there is a partition (P)
- How does the system trade off availability and consistency (A and C);
- else (E), when the system is running normally in the absence of partitions
- How does the system trade off latency (L) and consistency (C)
- If there is a partition (P)
- CAP does not really choose between
CandAbut only makes certain tradeoff - PACELC tells, we choose between
ConsistencyandLatency - Eg. Cassandra is
PA/ELsystem.
CALM
- See CALM
Hellerstein’s inequality
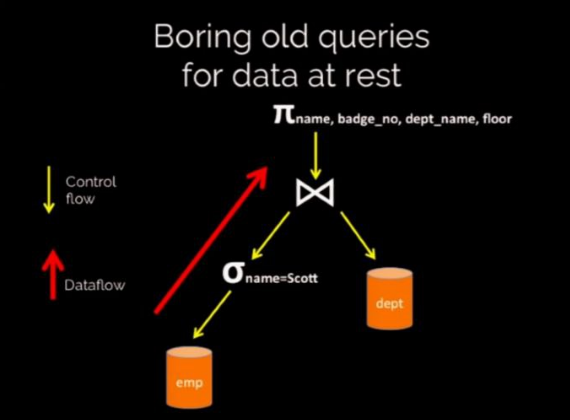
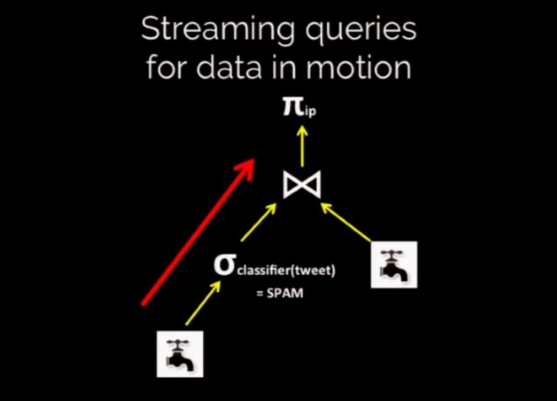

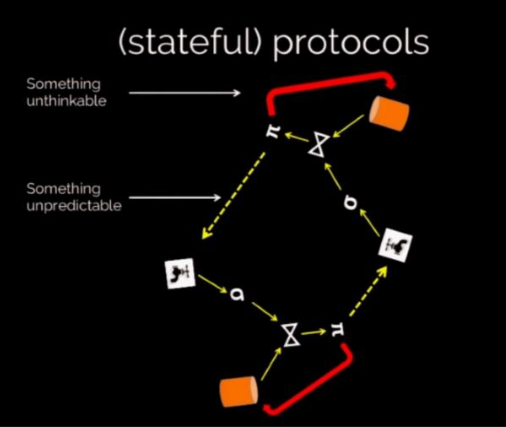
- Useful in cases when sql queries remain the same but in the backend you can keep on fine tuning stuff like add indexes and what not. But this way of developing applications is much more useful in cloud applications where the environment changes all the time.
- Distributed language requirements
- Something unthinkable: Need to represent time-varying state
- Something unpredictable: Need to represent uncertainty (i.e. nondeterminism in ordering and failure)
Impossibility Results
We can check the
Impossibility Resultsfor each of the different dist sys problems. Eg. CAP theorem considers the coordinating attack model for the atomic storage problem and shows that with arbitrarily unreliable channels, you cannot solve the atomic storage problem either.
- Example via 2PC: Two-phase commit and beyond
Results
coordinated attack
- Two Generals’ Problem - Wikipedia
- The coordinating attack result says that if the communication channels can drop messages you cannot solve distributed consensus using a deterministic protocol in finite rounds.
FLP impossibility results
- Paper summary: Perspectives on the CAP theorem
- Assume reliable channel, or eventually for a sufficient period reliable channels.
- Under an asynchronous model, you cannot solve distributed consensus using a deterministic protocol in finite rounds, in the presence of a single crash failure.
Solutions to impossibility results
These allow us to circumvent (not to beat) these impossibility results
consensus
fault-tolerance
- https://en.wikipedia.org/wiki/Self-stabilization
- Gray failure: the Achilles’ heel of cloud-scale systems | the morning paper
Time and Clocks
See Clocks
Problems in Distributed Systems
Synchronization
See Database Transactions, see Synchronization
2PC
- See Two Phase Locking (2PL) & Two Phase Commit (2PC)
- Leader writes a durable transaction record indicating a cross-shard transaction.
- Participants write a permanent record of their willingness to commit and notify the leader.
- The leader commits the transaction by updating the durable transaction record after receiving all responses.
- It can abort the transaction if no one responds.
- Participants can show the new state after the leader announces the commit decision.
- They delete the staged state if the leader aborts the transaction.
Real time sync
atomic storage problem
- CAP tries to solve this
Replication
- See Data Replication
Consensus
Distributed Snapshots
Distributed snapshots are trying to do as little work as possible to get a consistent view of the distributed computation, without forcing the heavy cost of consensus on it. For example, node A is sending a message to node B, we don’t care if we capture in:
- 1: A before it sends the message, B before it receives the message
- 2: A after it has sent the message, the message, and B before it receives the message
- 3: A after it has sent the message, B after it has received the message
No matter which of those states we restore, the computation will continue correctly.
- Distributed Snapshots: Chandy-Lamport protocol
- Distributed Snapshots: Determining Global States of Distributed Systems | the morning paper
Distributed Locks
- See Database Locks
- How to do distributed locking — Martin Kleppmann’s blog
- Purpose: Ensure that among several nodes that might try to do the same piece of work, only one actually does it (at least only one at a time).
Resources
- A robust distributed locking algorithm based on Google Cloud Storage – Joyful Bikeshedding
- Leader Election with S3 Conditional Writes | Hacker News
- distributed-lock-google-cloud-storage-ruby/README.md at main · FooBarWidget/distributed-lock-google-cloud-storage-ruby · GitHub
- Reddit - Dive into anything
- Distributed Locks with Redis (2014) | Hacker News
Service Discovery and Peer to Peer communication
- See peer-to-peer
Notes from LK class
Class 1
- Dist sys
- Running on several nodes, connected y network
- Characterized by partial failures
- System w partial failure + Unbounded latency
- Partial Failures
- Eg. Cloud computing vs HPC
- Cloud: Work around partial failures
- HPC: Treat partial failures as total failure. Uses check-pointing.
- Eg. Cloud computing vs HPC
- Byzantine Faults
- If you send a request to another node and don’t receive a response, it’s impossible to know why. (without a global knowledge system)
- Byzantine faults can be seen as a subset of partial failures
- Eg.
- There could be issues in M1 -> M2
- Network issues
- Queue congestion
- M1 breaking
- There could be issues in M2 -> M1
- M2 Lying
- Cosmic rays
- There could be issues in M1 -> M2
- Solution
- These do not address all kinds of uncertainties
- Timeouts and Retries
- Issue with timeouts is that it will not work well when the message causes a side effect. Eg. increment some counter
- Predict Max delay
- Eg. from M1->M2 =2d+r (if d is time for M1-M2 and r is processing time)