tags : Distributed Systems, Infrastructure, Message Passing, Zookeeper
What
- Reimplementing Apache Kafka with Golang and S3 - YouTube 🌟
- Publishing with Apache Kafka at The New York Times | Confluent
- Kafka is not a Database
- Can Apache Kafka Replace a Database? - Kai Waehner
Gotchas
- Kafka doesn’t scale well with partitions, throughput falls over quickly especially if using replication and acks.
- If each user has a topic your partitions are unbounded. You have at least one partition per user.
- Instead, I’d use a single notification topic, set a reasonable number of partitions on it and partition by user id.
Resources
- Webcomic: https://www.gentlydownthe.stream/#/3
- Windowing in Kafka Streams
- Apache Kafka Beyond the Basics: Windowing | Hacker News : See comments, has good learning roadmap
Redpanda
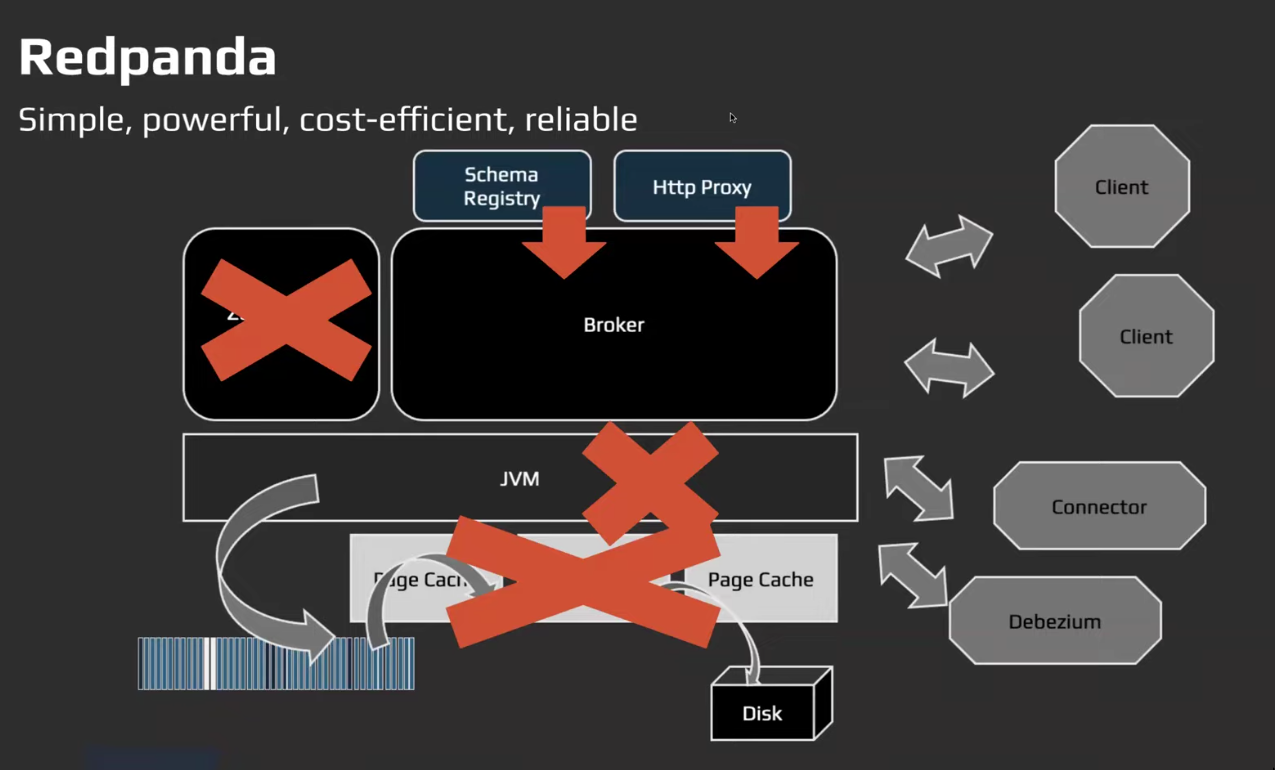
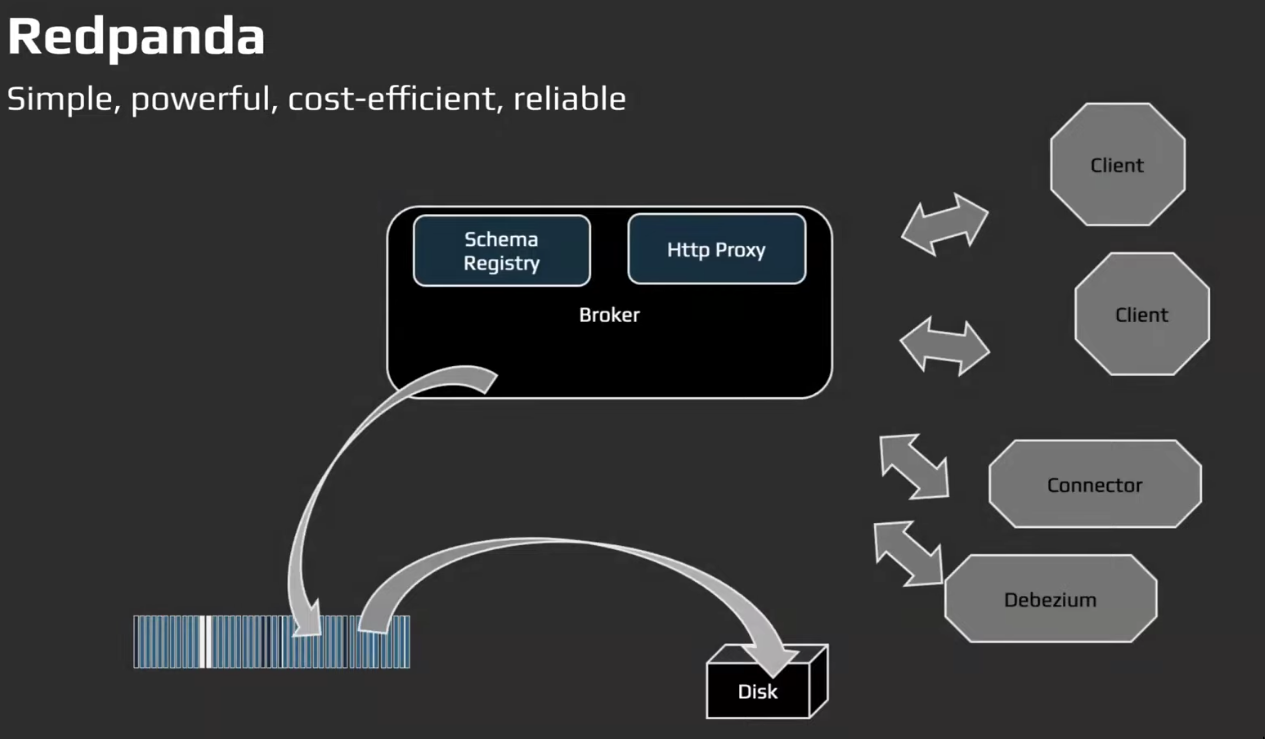
- Redpanda achieves this decoupling(producer/consumer) by organizing
eventsintotopics.
Topics & Partitions
Kafka guarantees ordered message delivery ONLY within a single partition
Topics (unordered)
Topic= a named log ofevents- It’s
unorderedcollection Topics= logical grouping ofeventsthat are written to thesame log.- Topic can have multiple producers and multiple consumers
- By default, a topic has at least one partition.
-
Topic storage
- Topic are stored in a tiered manner, local < object store etc.
consumercan use the same api to access both (immediate vs historical data etc.)- Historical: Consumers can read and reread events from any point within the maximum retention period.
- Topic are stored in a tiered manner, local < object store etc.
Topic Partitions (ordered)
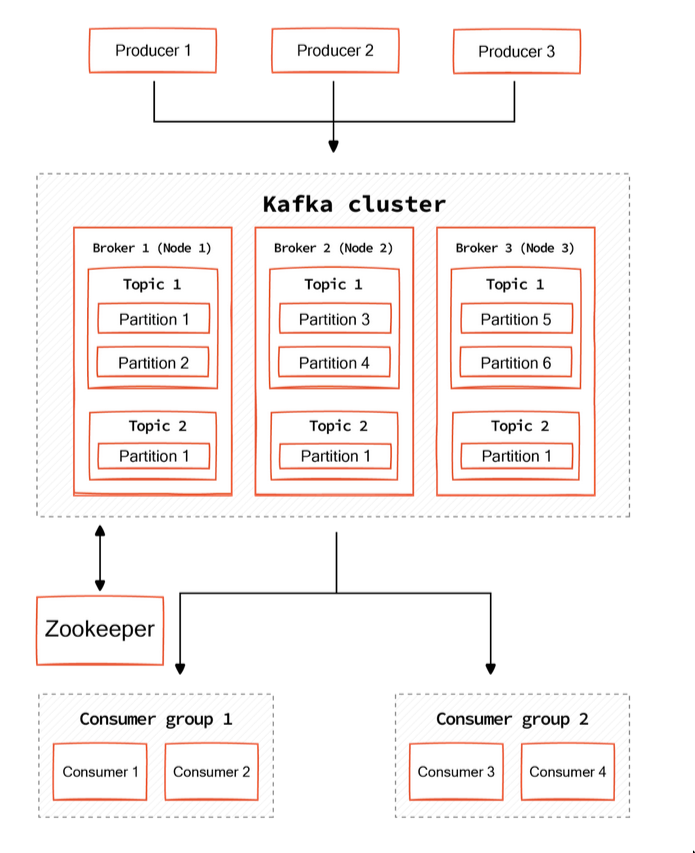
- The idea of
same logfile is altered when we introduce partitioning. We do this so that we can scale well.- So with partitions,
eventsare written to atopic-partition
- It’s
orderedcollection Sharding and distribution- Redpanda scales topics by sharding them into multiple partitions distributed across cluster
nodes/broker - Enabling concurrent writing and reading.
- Redpanda scales topics by sharding them into multiple partitions distributed across cluster
Event routing and orderingProducerssend messages tobrokers, and thebrokerroute the data acrosspartitions.eventssharing the samekeyalways going to the samepartition.eventsare ordered at thepartitionlevel.
Consumption and key-less routing- Consumers read
eventsfrombrokersfrom the topics they subscribe to.brokerthen managers thetopic-partitionpart. - When reading, per
topic-partitionevents are read in the order they were written. - If no key is specified, events are distributed among all topic-partitions in a round-robin manner.
- Consumers read
Topic Event replication consensus (for fault tolerance)
- For providing fault tolerance and safety, redpanda replicates the
eventsto othernodes/brokers. For this, it uses Raft - Every
topic-partitionforms a Raftgroup- group:
single leader+0 or more followers(replication factor)
- group:
Broker
- See Kafka broker
- Multiple brokers help with
- Fault tolerance: Data Replication can now happen via Raft
- Concurrency: Because topics are partitioned, we can write in a sharded manner
- It contains
topic-partitions(log files) that store messages in an immutable sequence. - Brokers have tunable parameters
Consumer
Consumer Group
The idea of
replicationandscaling outetc come when we introducepartitionsand introduceconsumer groupto manage things betweentopics,partitionsandconsumers. Since now that we’re dealing with replication etc, the concept ofleaderand Raft etc come out.
| Relation | Mapping | Description/Notes |
|---|---|---|
Partition <> topic-partition | - | Same thing. |
Partition <> Topic | N:1 | a topic is like a label/name for all a partitions in the topic. (A topic will atleast have one partition) |
Partition <> Consumer | M:N | multiple consumers can consume from same partition. |
Partition <> Data Pane Raft Group | 1:1 | This is how event/message replication happens |
Partition <> Control Pane Raft Group | 1:1 | Eg. Each partition |
CG <> Control Pane Raft Group | 1:1 | CG is essentially the raft group |
CG <> Topic | N:1 | A consumer group belongs to ONLY one Topic, there can be multiple CG belonging to the same topic. |
CG <> Consumer | M:N | many consumers can be part of a consumer group |
CG Coordinator <> Broker | N:1 | A broker/node can be handling data of multiple CG Coordinator, broker here is like a reverse proxy. |
If it goes down, it can take down multiple CG coordinators, but because of HA, we’ll have another broker will everything replayed. | ||
From the pov of the cg coordinator it is the broker (Buzz Lightyear Clones meme) | ||
CG Coordinator <> CG | 1:1 | Each CG only ever has 1 leader elected via Raft, the leader is the CG Coordinator |
Partion Leader <> CG Coordinator | - | Same thing |
CG Coordinator <> Control Pane Raft Leader | ??? | The CG Coordinator has affinity to raft leader. |
My doubts:
- Is there really a different
ControlandDatapane raft cluster? For my understanding it seemed easy to think of them as separate things but are they really separate in implementation? CG Coordinator <> Control Pane Raft Leader: What’s the mapping here?- https://gist.github.com/geekodour/443fb346719a05485e59821df7b2015f
Others
- Every
consumer/clientby default will read via theleader. This to ensure strong consistency - Reading from replica can be a usecase(and technically possible leading to Eventual Consistency) but currently that’s not the default practice and atm of this writing it’s not even supported.
- Renpanda does:
ACK=all.- i.e ACKs to all replicas. -> strong consistency, but eitherway we can’t read from replicas yet in redpanda
- This replicate the
consumer group state(i.e raft group state) - i.e the serialized
consumer group stateis replicated toallotherbrokersand “saved to disk”. (before the write goes back to the client)
Basics
Consumer Groupis part of the kafka protocol: Kafka consumer group- Usecase: Parallelism, Coordination between consumers, Tracking progress of consumer state, Availability
Consumersneeds to ingest from: (example scenarios)- single consumer consuming from multiple
topic-partition. - multiple consumers consuming from single
topic-partition
- single consumer consuming from multiple
- To coordinate all this example scenarios, We can either use our own logic for this, or we can use
Consumer Groupwhich make things easy for us. - By using
Consumer Group, we use theCoordination Protocol
Why Consumer Group?
Using this primitive, multiple consumer can now ingest from the same topic and consumer group takes all care of:
parallelism & coordination: which partition should thisconsumerread from?tracking progress: Helps w dealing w failures,consumersneed to manage offset, metadata, checkpointing etc.CGhelps with all that.- When using
CGto track progress, internally it uses Raft, theRaft Groupis essentially what theConsumer Group’s is. The data is serialized and stored on-disk.
- When using
availability- Because we have
CGgoing on, based on the spec/protocol, we’ll have replicas ready to go off if theCG coordinators
- Because we have
Identification of Consumer Group
- From what I understand, it’s identity is
(topic_id, consumer_group_id). So if you have the same consumer_group_id for 2 different topics, the actual entity ofconsumer_groupwill be different even if the value ofconsumer_group_idis same. ie.(topic1, cg_xyz),(topic2, cg_xyz), these two are 2 differentconsumer_group, completely separate. Usually it’s confusing to name things like this but if you happen to they’ll be 2 different consumer group. Aconsumer groupwill NOT share a topic. - Atleast in the case of redpanda connect,
consumer_group_idis created on the fly when you start theconsumer.
Consumer Group Coordinator
Consumer Group Rebalance
from the pov of the
CG coordinator, the system needs a “stable state” to make progress. After rebalancing, we achieve the stable state and then we go on. The “go on” is based on the debounce effect which extends the window for good.
Consumercomes/leaves out ofCG, or anything that changes the dynamic relationship betweenConsumerandCGtriggers something calledGroup RebalanceRebalance: Who should be consuming from whichpartition- If
CGhas a lot of members(consumers) or flaky members(consumers), we spend a lot of time in doingrebalancingplus ifrebalaningkeeps on happening we cannot make any progress. Eg. if a consumer keeps joining and leaving the CG every 10ms, we’ll be triggeringrebalanceevery 10ms and things would not make progress etc. - Solution is:
- Properly setting
deboundingperiod - https://github.com/redpanda-data/redpanda/issues/1335
- Properly setting
Leadership Coordination Protocol
- https://www.redpanda.com/blog/validating-consistency
- https://x.com/emaxerrno/status/1846196674982752697
See “The Magical Rebalance Protocol of Apache Kafka” by Gwen Shapira - YouTube 🌟
-
In event of one of the
leader broker(CG coordinator) failing- The leadership is changed by Raft
- Because we have the replicated
CG dataof the failed node in the newleader broker, we “replay that log” in the new leader. - Once the replay/recovery is finished, we announce to the cluster that I am the new leader for the Raft group. i.e the new
CG coordinator. - The
Consumer Group protocolensures that theconsumersswitch theCG coordinatorto the newly elected leader. (i.e clients/consumer automatically discover the address of the new leader node)- https://kafka.apache.org/protocol#The_Messages_FindCoordinator : This is defined in the Kafka spec. Clients/Consumers would query the
FindCoordinatorAPI to find the newCG coordinator. - Basically
client/consumerasks “whichbrokerin the cluster is acting as theCG coordinatorfor myconsumer group”. Anybrokerin the cluster can answer this question. It hashes theconsumer groupname and looks up the replicated&deterministic oncg <> cg coordinator brokermapping.- Mapping:
CG coordinator <> Partition Leader, but if both of them are the same we just have to find one.
- Mapping:
- https://kafka.apache.org/protocol#The_Messages_FindCoordinator : This is defined in the Kafka spec. Clients/Consumers would query the
- DOUBT: What do we mean when we ask “who is the leader of this
partition?”- OKAY clarification,
consumer/clienttalk in terms ofpartition, not in terms of CG coordinator. TODO - We’ve actually assigned the
leader of the partitionto theCG coordinator
- OKAY clarification,
-
How does the
client/consumer“really” get to know of the new broker for thetopicits’s trying to read from- This is the explanation of what
FindCoordinatorAPI does.
- This is the explanation of what
-
Hierarchy of things
client/consumerconnects to aConsumer Group