tags : Data Engineering, Batch Processing Patterns, Kafka
FAQ
How does differential dataflow relate to stream processing?
A problem statement for restaurant orders :)
Let’s assume we are building a data pipeline for Uber Eats where we keep getting orders. We want a dashboard which shows each restaurant owner
- How many orders?
- What are the Top 3 ordered dishes (with order count)?
- What’s the total sale amount?
There are 3 buttons on the UI which allow the users (restaurant owners) to see these numbers for different time periods:
- Last 1 hour
- Last 24 hours (= 1 day)
- Last 168 hours (= 24h * 7 = 1 week)
The dashboard should get new data every 5 minutes. How do you collect, store and serve data?
Solution
There are techniques most data systems offer to handle periodic (5m, 1h, etc) computation on incoming data (from Kafka, etc).
- Dynamic table on Flink
- Dynamic table on Snowflake (as \fhoffa mentioned)
- Materialized views on Clickhouse
- Delta Live table on Databricks
The underlying concept is that these systems store metrics state (either in memory or on disk or another db) and update them as new data comes in. In our case they will update per hour and then dump it into a place to be read from later.
If you partition your data by hour, One thing to note is that the metrics you specified are additive (can be added across hours), if they are non additive (such as unique customer id count) that will require more memory (or other techniques such as Hyperloglog).
While most systems can handle these for you, its good to know the underlying concept, since that will impact memory usage/cost. Hope this helps. LMK if you have any questions.
What is it really?
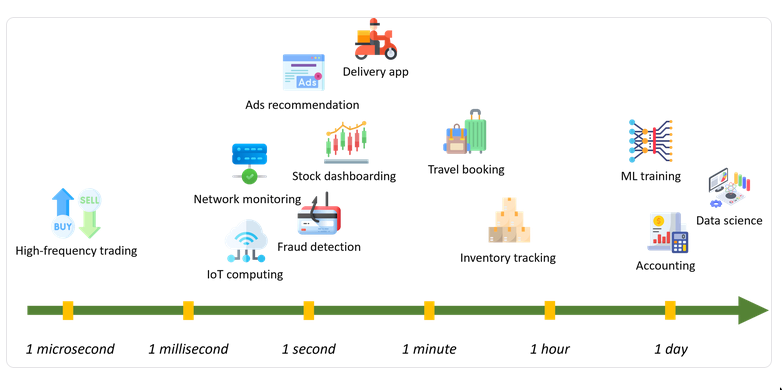
stream processingandstreaming ingestionare different things. There are systems which do one, there are also systems which do both, partially, fully, all tradeoffs.
Streaming ingestion
- This simply means ingesting to something in a streaming fashion (could be a OLAP database)
- This has to deal with things like de-duplications as OLAP systems don’t have a primary key etc. Schema and Datatype changes in source table etc.
- Along with streaming ingestion lot of OLAP databases allow for
continuous processing(different from stream processing)- Underlying concept is that these systems store metrics state and update them as new data comes in.
- Some examples are: Dynamic table on Flink, Dynamic table on Snowflake, Materialized views on Clickhouse, Delta Live table on Databricks etc.
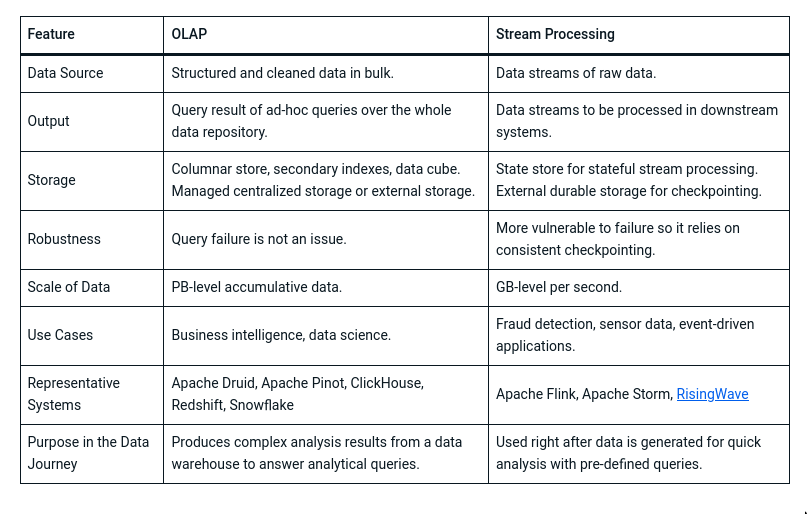
Stream processing
Stream processing systems are designed to give quick updates over a pre-defined query. To achieve that, incremental computation lies at the core of the design principle of stream processing. Instead of rescanning the whole data repository, stream processing systems maintain some intermediate results to compute updates based only on the new data. Such intermediate results are also referred to as states in the system. In most cases, the states are stored in memory to guarantee the low latency of stateful computation. Such a design makes stream processing systems vulnerable to failures. The whole stream processing pipeline will collapse if the state on any node is lost. Hence, stream processing systems use checkpoint mechanisms to periodically back up a consistent snapshot of global states on an external durable storage system. If the system fails, it can roll back to the last checkpoint and recover its state from the durable storage system.
- In most cases, they’re more flexible and capable than OLAP db’s
continious processingfeatures. So they sit in-front of the streaming ingestion into OLAP making sure OLAP gets cleaned and processed data.- But in most cases, you might not even not need stream processing, whatever
continious processingfeature OLAP DBs have might be enough, they’re great imo in 2024.
- But in most cases, you might not even not need stream processing, whatever
Architectures
- Lambda: Here we merge real-time and historical data together
- Kappa: If you don’t need a lot of historical data, and only need streaming data.
Tech Comparison
Comparison table
| RT Stream Processor | DBMS | Tech Name | RT Stream Ingestion | What? |
|---|---|---|---|---|
| Yes | No | Apache Flink | Yes, but not meant to be a DB | Can be used in-front of a OLAP store |
| Yes | No | Benthos/Redpanda Connect | No | Apache Flink, Rising Wave alternative |
| Yes | No | Proton | No | Stream Processing for Clickhouse ? |
| Yes | Yes (PostgreSQL based) | RisingWave | Yes, but not meant to be a DB | Apache Flink alternative, it’s pretty unique in what it does. See comparision w MateralizeDB |
| Yes | Yes(OLAP) | Materialize DB | Yes | Sort of combines stream processing + OLAP (More powerful than Clickhouse in that case), supports PostgreSQL logical replication! |
| ? | Yes(OLAP) | BigQuery | Yes | It’s BigQuery :) |
| Not really | Yes(OLAP) | Apache Druid | True realtime ingestion | Alternative to Clickhouse |
| No | Yes(OLAP) | Apache Pinot | Yes | Alternative to Clickhouse |
| No | Yes(OLAP) | StarTree | Yes | Managed Apache Pinot |
| No | Yes(OLAP) | Clickhouse | Yes, Batched realtime ingestion | See Clickhouse |
| No | Quack like it!(OLAP) | DuckDB | No | See DuckDB |
| No | Yes(OLAP) | Rockset | Yes | Easy to use alternative to Druid/Clickhouse. Handles updates :) |
| No | Yes(OLAP) | Snowflake | Yes but not very good | - |
| No | No | NATS | Message Broker | |
| No | No | NATS Jetstream | Kafka alternative | |
| No | No | Kafka | kafka is kafka |
Druid vs Clickhouse
ClickHouse doesn’t guarantee newly ingested data is included in the next query result. Druid, meanwhile, does – efficiently, too, by storing the newly streamed data temporarily in the data nodes whilst simultaneously packing and shipping it off to deep storage.
- Druid is more “true” realtime than clickhouse in this sense but that much of realtime is not usually needed in most of my cases.
- What Is Apache Druid And Why Do Companies Like Netflix And Reddit Use It? - YouTube

Risingwave vs Clickhouse
- They can be used together
Benthos(Redpanda Connect) vs Risingwave
- Both are stream processors
- Risingwave is a stateful streaming processor
- Benthos is sitting somewhere between stateless and stateful systems
NATS jetstream vs Benthos
- NATS jetstream seems like a persistent queue (Eg. Kafka)
- Benthos is something that would consume from that stream and do the stream processing and put the output elsewhere.
More on Redpanda
- See Kafka
More on Redpanda Connect / Benthos
- https://github.com/weimeilin79/masterclass-connect
- https://graphql-faas.github.io/benthos/concepts.html
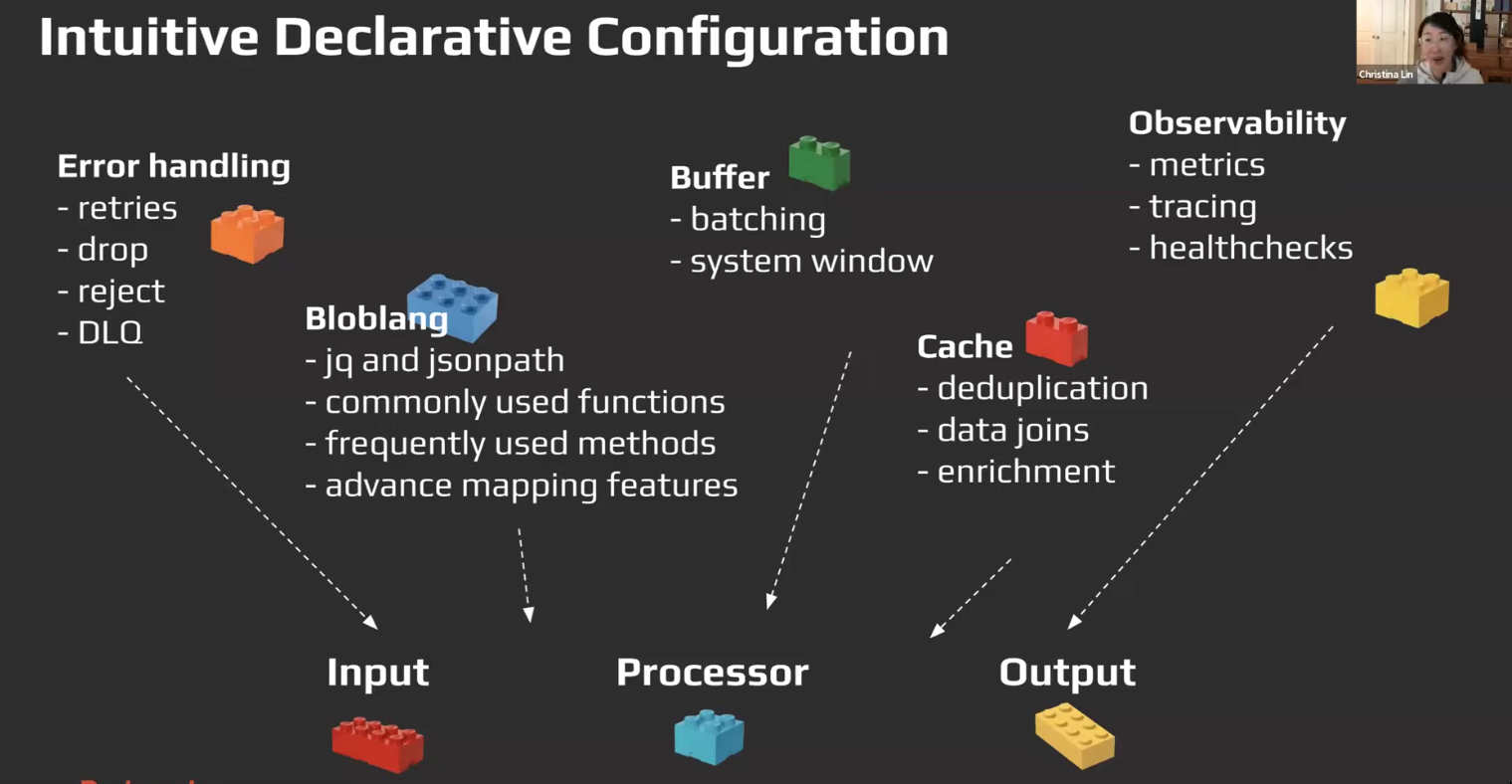
Delivery Guarantee
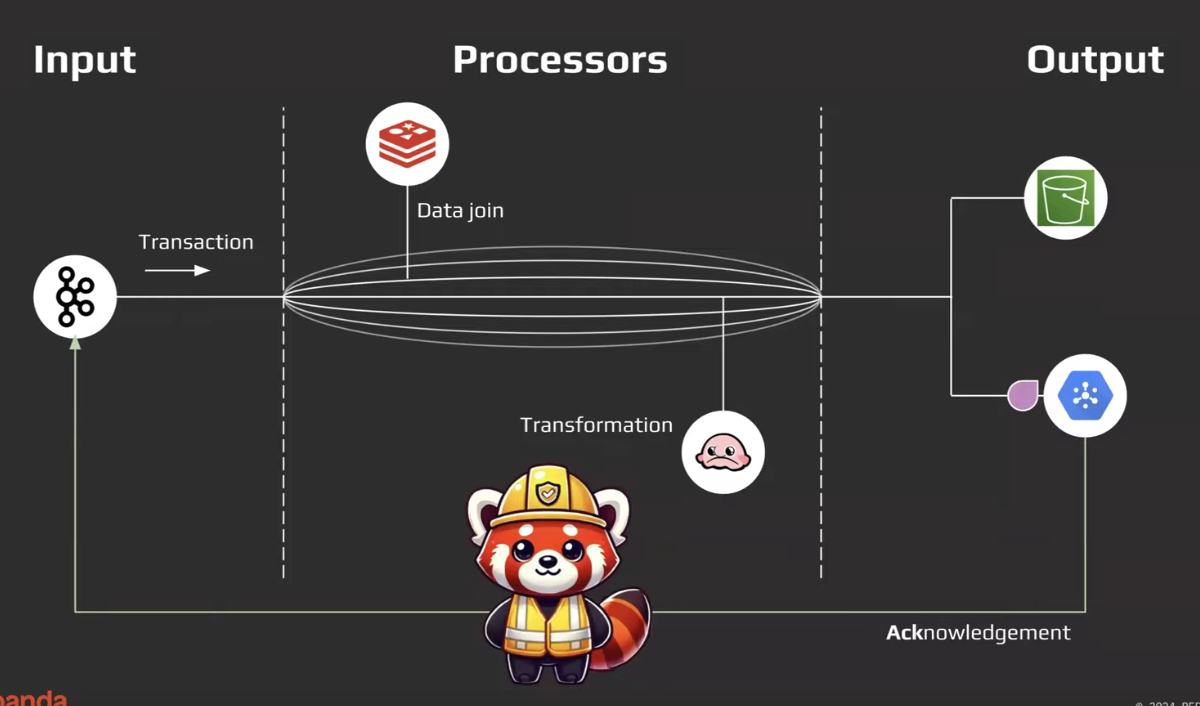
See Data Delivery
- In benthos/rp connect,
input <> process <> output, entire pipeline needs to run e2e(i.eoutputneeds to finish), then it sends anACKback to the input in which case it’ll move on to the next item in the list. - dropping a message also sends an
ACK, i.e we’ll move to the next message etc.
Lifecycle
- With
run, eg. after usinginput:filethe process will automatically kill itself - But if using
streams, they process will keep living - After “success” ACK is sent back to the input from the output, but synchronous response is also possible with
sync_responseoutput component.sync_responseonly work with few input components such ashttp_serversync_responsecan be used withinput:http_serverandoutput:http_clientturning redpanda connect into sort of a proxy webserver.
Message semantics

- messages have
metadata+context
Configuration, Components and Resource (Hierarchy)
- Configuration is passed via config file/api,
resourcesare passed in via the-rflag. -ris usually used to switch resources in different environments (used as feature toggle)
-
componentsrpk connect list, we sort of have components for these:- Inputs
- Processors
- Outputs
- Caches
- Rate Limits
- Buffers
- Metrics
- Tracers
- Scanners
- In some/most cases, the same
componentwill be available forinputandoutputbut the parameters will differ etc. configurationcontainscomponentscomponentsare hierarchical.- Eg.
inputcan have a list of childprocessorattached to it, which in turn can have their ownprocessorchildren.
- Eg.
-
resourcesresourcesarecomponents, identified bylabel.- Some
componentssuch ascachesandrate limitscan only be created as aresource.
- Some
- Main usecase is “reuse”, another similar concept is
templates - Can be specified in the same configuration, can also be specified separately and passed via
-r - Types
input_resources: []cache_resources: []processor_resources: []rate_limit_resources: []output_resources: []- It’s defined using the above config and used in
input/pipeline/outputvia theresourcecomponent
-
Other
- Eg. crazy number of levels
processors: - resource: foo # Processor that might fail - switch: - check: errored() processors: - resource: bar # Recover here
Batching
-
Batching at
inputvsoutput- It’s little confusing, some components apparently perform better when batched at input, and some at input. If you want to do “batch processing” then you’d want to batch in the
input.- If
inputitself doesn’t support batching, we can usebrokerand make theinputor multiple input support batching at input stage. brokeralso works similarly foroutput
- If
- It’s little confusing, some components apparently perform better when batched at input, and some at input. If you want to do “batch processing” then you’d want to batch in the
-
Creating and breaking batches
- A batch policy(input/output having
batchingattribute) has the capability to create batches, but not to break them down.- This also takes in
processorincase, you want to pre-process before sending out the batch.
- This also takes in
splitbreaks batches
- A batch policy(input/output having
Processor (array of processors in input/pipeline/output section)
proccessorare not just limited topipelinesection.- Native way of doing processing/manipulating shit is via
bloblang(viamappingormutation)- NOTE: The
mappingprocessor previously was called thebloblangprocessor(now deprecated)
- NOTE: The
-
Data Enrichment
-
Branching
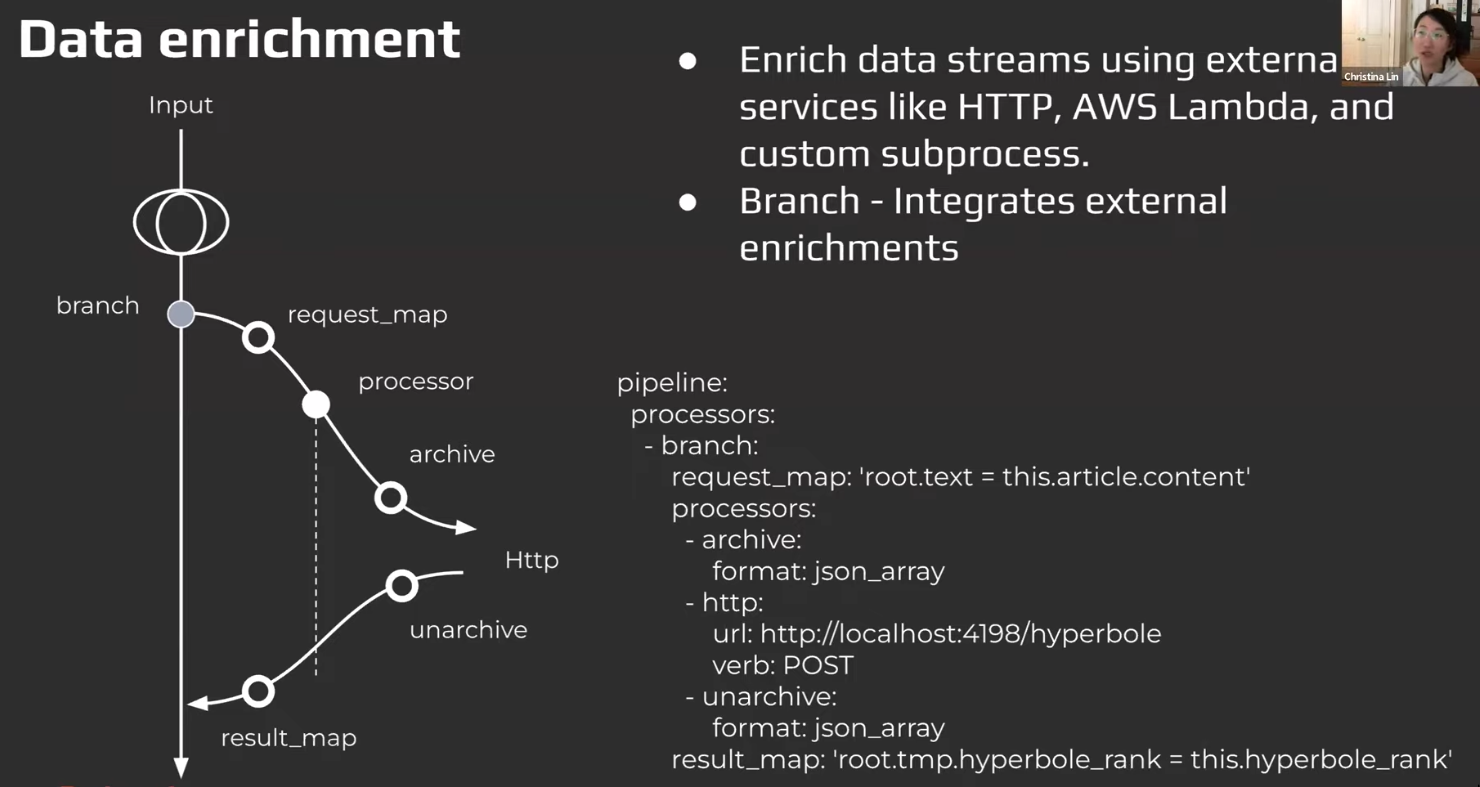
-
Workflow
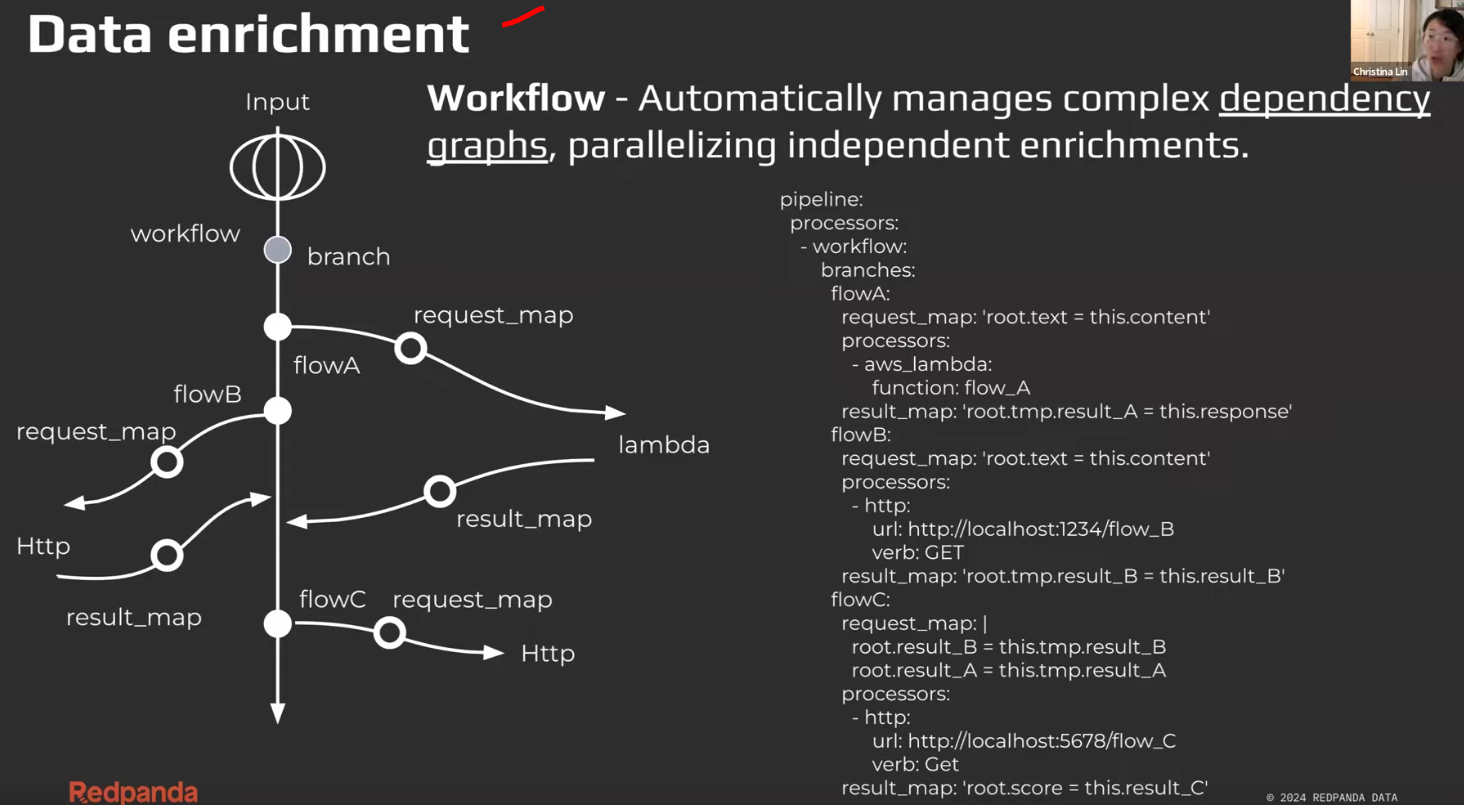
-
Caching
There’s
cacheand then there’scached-
cache
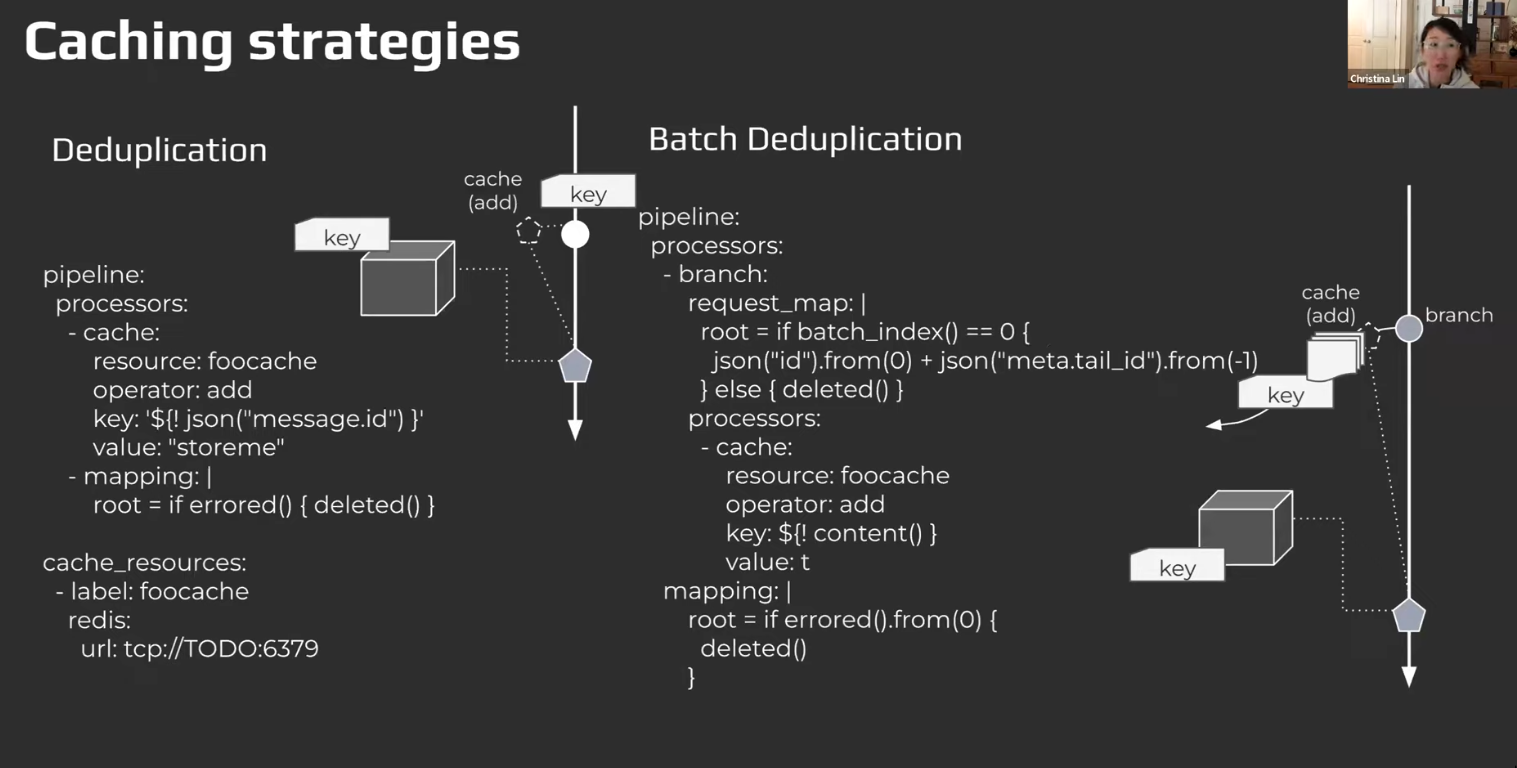

-
cached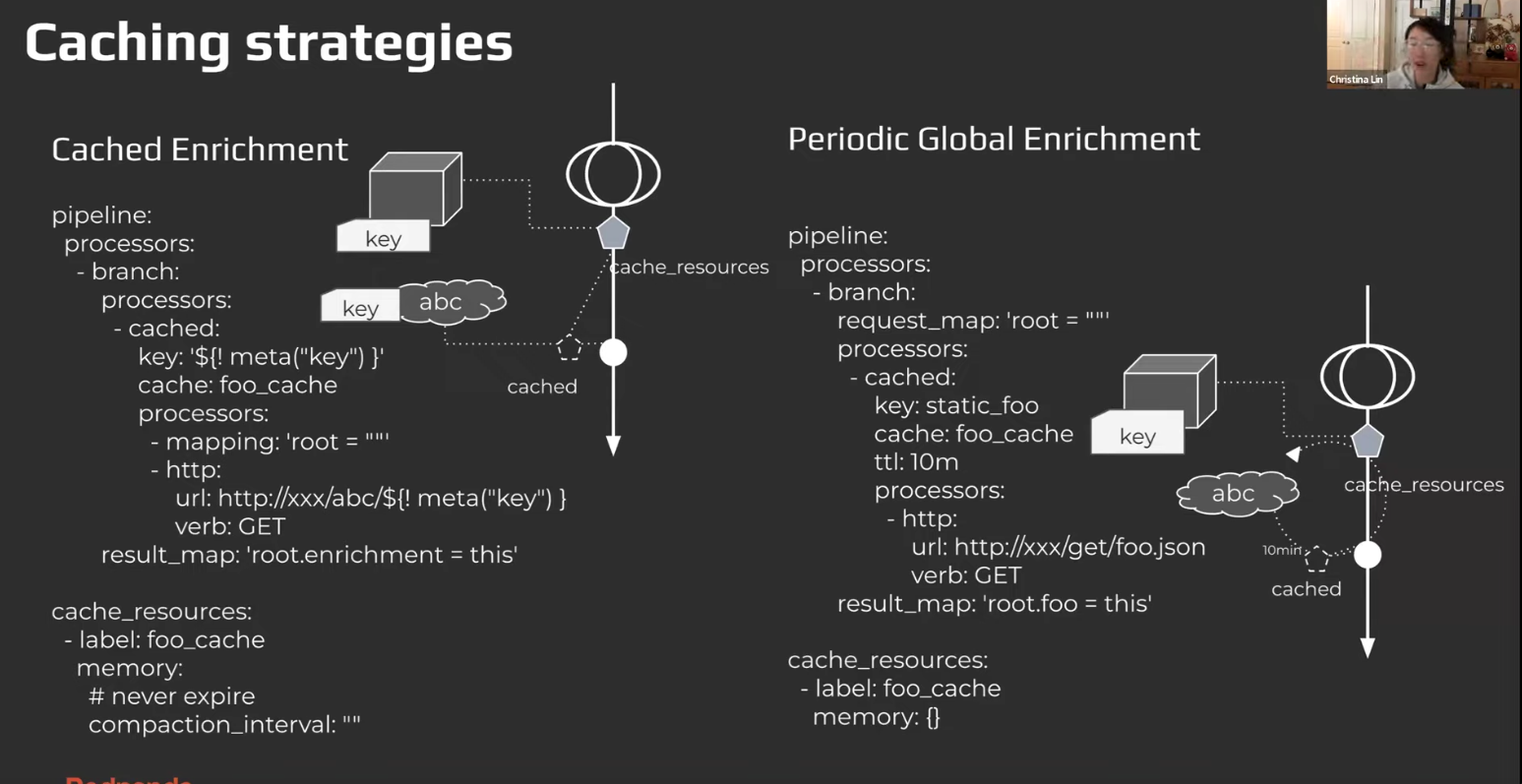
-
-
-
Batching & buffer
-
Basics
bufferis how we handlebatchingbuffercan be: window buffer,batchbuffer- Using
buffermight alter the delivery guarantees etc. might drop things. be cautious.
-
Transactions and Buffering
input -> processing -> outputis a transaction (an ACK is sent to the input after output finishes)- But when we use buffering, the semantics of this “transaction” is changed.
-
Pure Batching
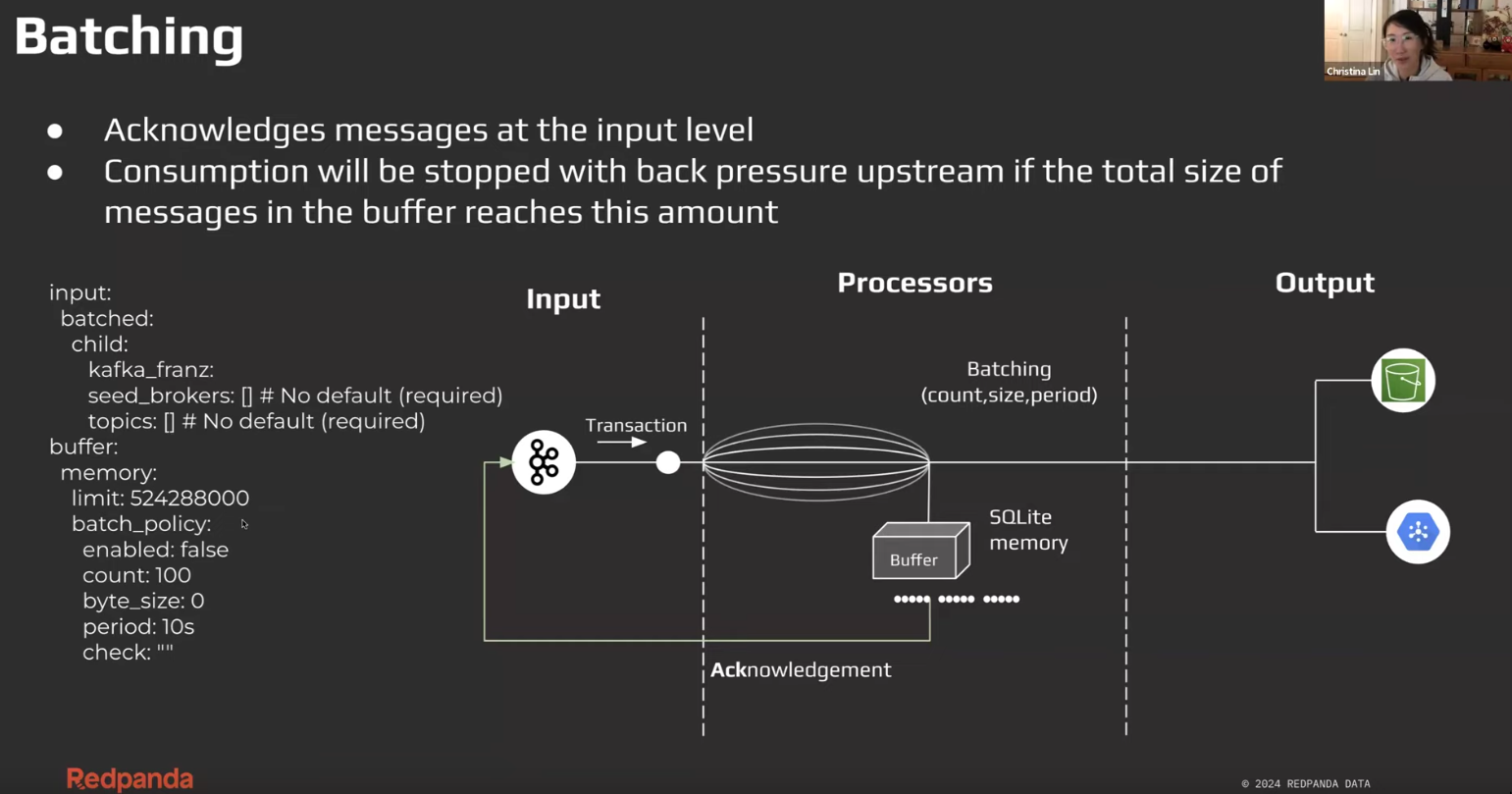
- config needed:
count, size, period
- config needed:
-
Windowing / Window Processing
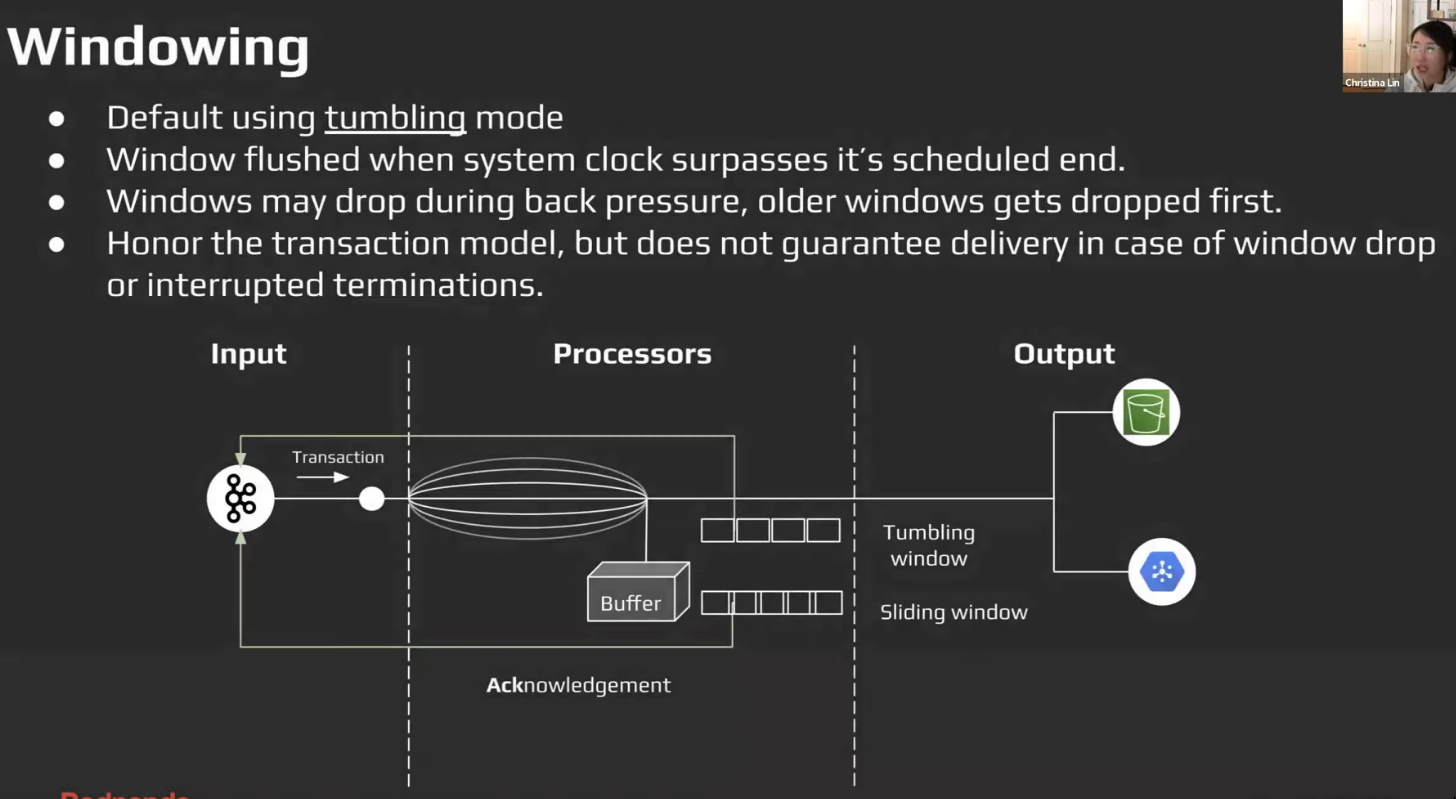
Tumbling window: No overlapSliding window: Overlap- config needed:
system_window&group_by_valuein the processor - This seems like but is NOT
stateful stream processing, benthos is stateless. (debatable)
-
Rate limiting
See Rate Limiting
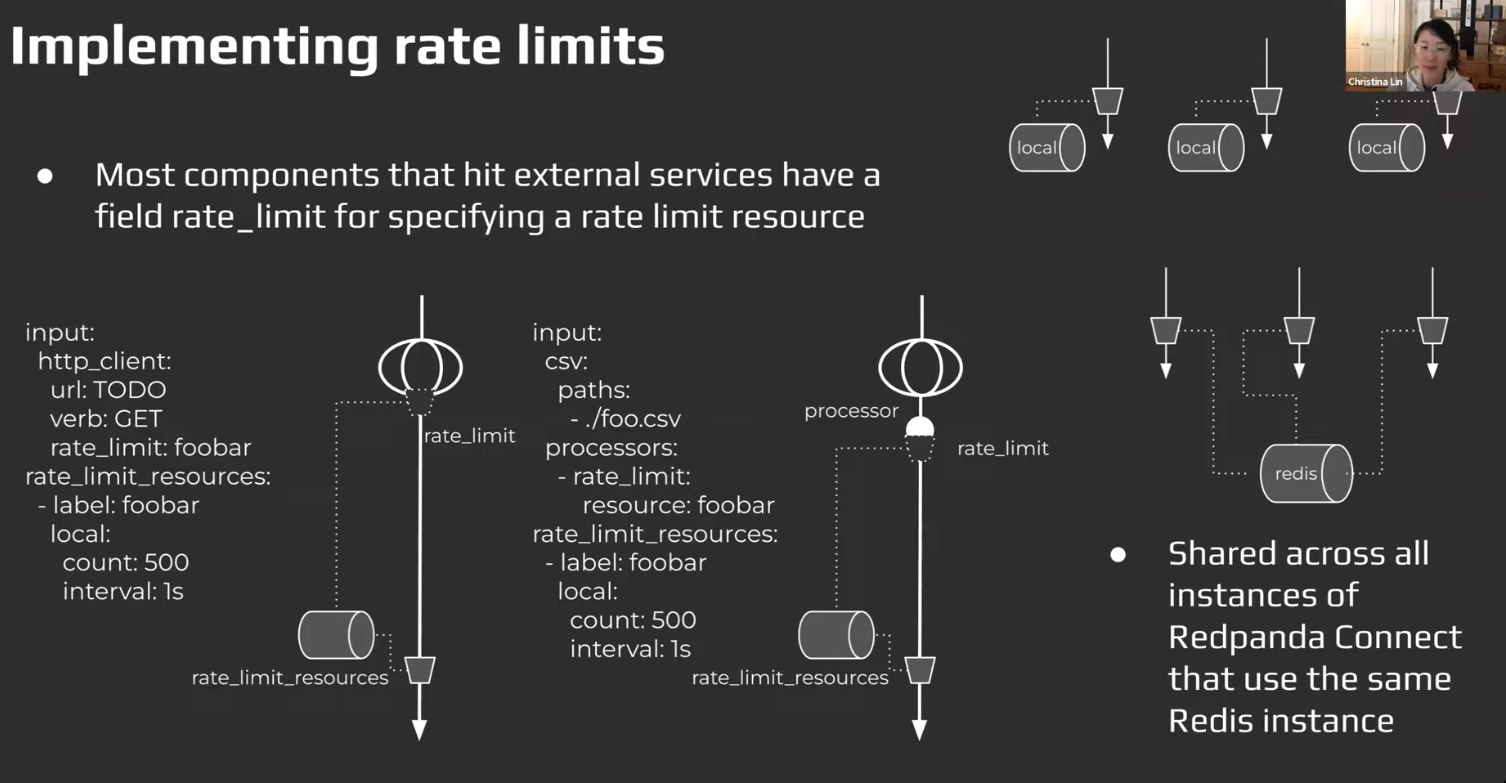
-
Exception handling
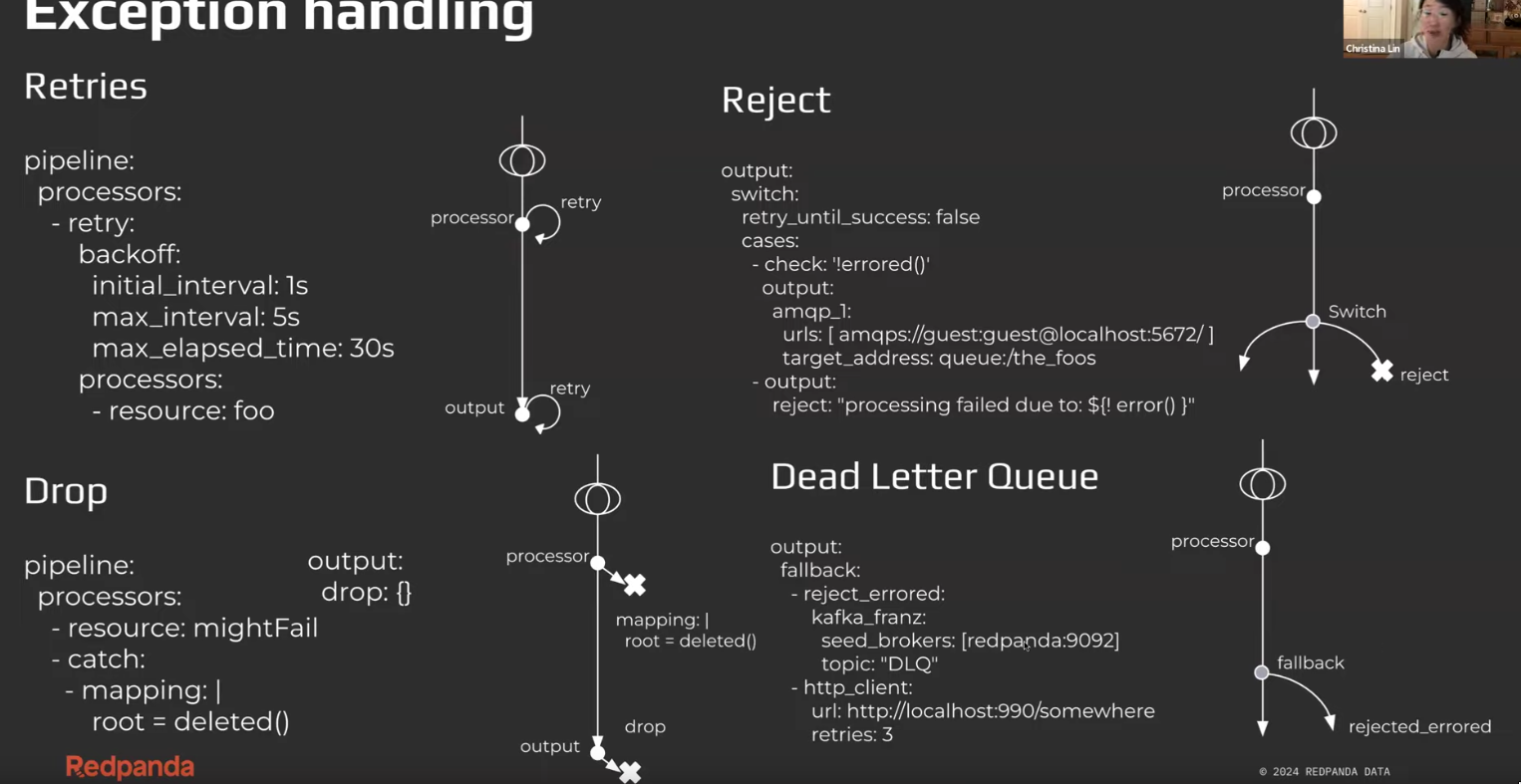
- Works w
processorandoutput, not winput??? (DOUBT)retryanddropwork for bothprocessorandoutputrejectanddlqwork only foroutput
-
Exception/Error creation
- an exception can be triggered by whatever happens when processing
- we can however have some control over how to create custom errors using blobl, otherwise if the processor itself errors out that works too.
-
Catching / Try / Drop
try(abandon) : If any of the processor in sequence fails, “skip” rest of it.retry(unlimited attempts)- This is similar to
tryas in like a blanket processor. Buttrysimply just takes in alist of processor, butretrytakes in some more params along withlist of processors
- This is similar to
catch(handle): catch the message/event w error and handle it somehow.catchcan be emulated withswitch:check:errored()(this is desirable if you want to maintain the error flag after success)- This is the
catchprocessor, which is different from thecatchfunction used inbloblang. catchcan then send off theerror()tologor remap thenew documentwith the error message etc.
-
Dropping message
mapping+errored()+deleted(): Dropping at processing stage. I personally would suggest dropping at output stage.reject_errored: (Dropping atoutputstage)- rejects messages that have failed their “processing” steps
- If
inputsupportsNACK/NAK, it’ll be sent a NAK at protocol level, and that message will NOT be re-processed. - Successful messages/events are sent to the child output
- Otherwise they’ll simply be reprocessed unless we use
fallbackand setup a DLQ mechanism.
- If
- rejects messages that have failed their “processing” steps
switch+errored()+error(): Maximum flexibility while handling how to route failed/errored messages.brokercan also be used to route messages accordingly.
-
Fallback(eg.DLQ) and Batching
- Redpanda Connect makes a best attempt at inferring which specific messages of the batch failed, and only propagates those individual messages to the next fallback tier.
- However, depending on the output and the error returned it is sometimes not possible to determine the individual messages that failed, in which case the whole batch is passed to the next tier in order to preserve at-least-once delivery guarantees.
Development Tips 🌟
-
Test script
input: stdin: scanner: lines: {} output: stdout: {}**
Bloblang
- 3 ways to use bloblang in
pipeline:
- Most common usecase is via
mapping. Some of the usecases ofmappingoverlaps with use ofjqprocessor and so on.
- Works in
processors(proper) and inoutput(via interpolation only)
- Processor
processor:bloblangprocessorr:mappingprocessor:branch:request_map/result_mapprocessor:<other processors>, eg.switchprocessor has acheckattribute which takes in a blobl query.- Output (via interpolation)
- additionally, can evaluate using:
rpk connect blobl/server

-
Interpolation & Coalecing
- Env var:
{ENV_VAR_NAME} - Interpolation of blobl:
${!<bloblang expression>} - Coalecing: root.contents = this.thing.(article | comment | share).contents | “nothing”
- Env var:
-
Variables
- Using
let& referenced using$ - Metadta access via interpolation or via
@insidemapping - Log all metadata
- log: level: INFO fields_mapping: |- root.metadata = meta()
- Using
-
Conditionals
- all conditionals are expressions
if: Can be astatementand can also be anassignemnt// this works root.pet.treats = if this.pet.is_cute { this.pet.treats + 10 } else { deleted() } // this also works if this.pet.is_cute { root.pet.treats = this.pet.treats + 10 root.pet.toys = this.pet.toys + 10 }match: Onlyassignment- Also accepts a parameter which alters the
thiscontext.
- Also accepts a parameter which alters the
-
Error handling & creation
- It seems like error handling is only supported in
pipelineblock and not ininputblock processors. (have to confirm) - Use of
catch - Error handling of
redpanda connect/benthosis different from blobl error handling. These consepts exists at different levels of the stack. - We create error either via
throwor via using helper functions which help in validating and coercing fields(eg.number, not_null, not_emptyetc.)
- It seems like error handling is only supported in
-
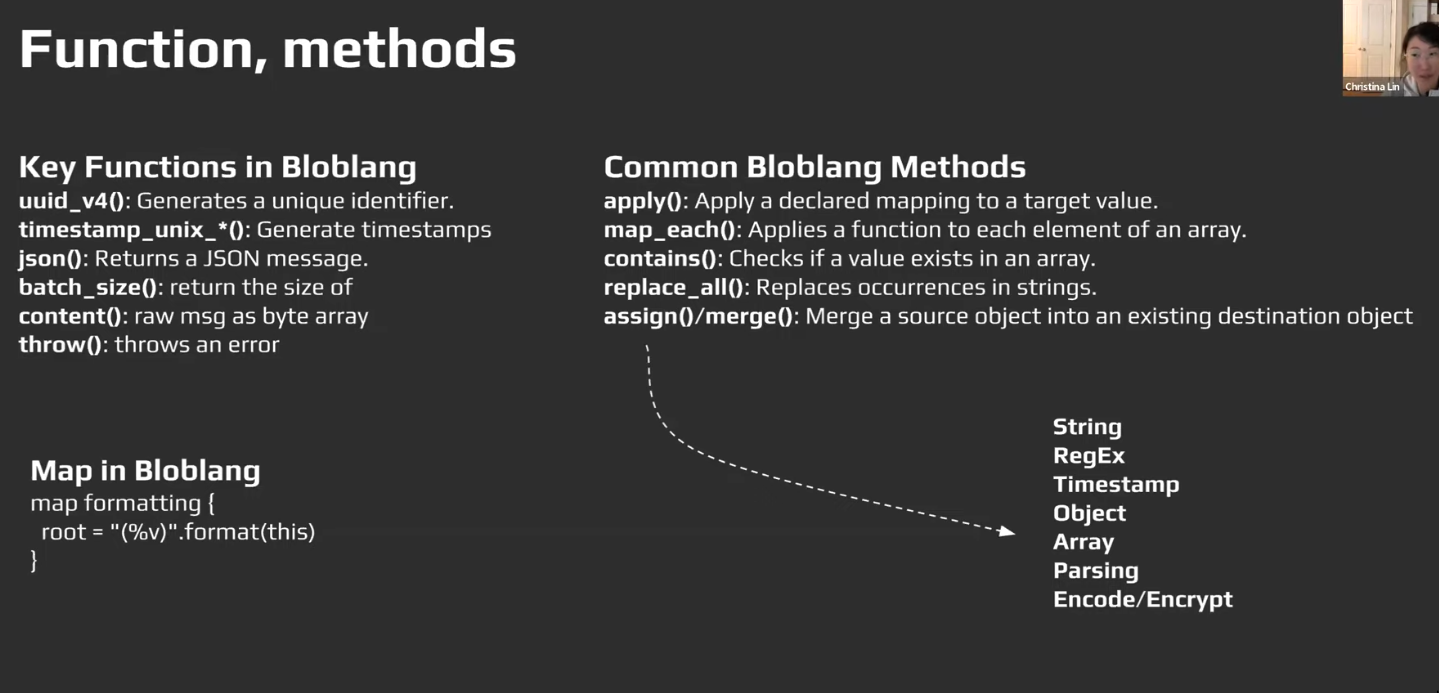
TODO Functions vs Methods
- Methods: Specific to datatypes/structured inputs etc. Eg. string.split etc
- Functions: Independent functions
-
Custom Methods
- We create
custom methodsby usingmapkeyword.thisinsidemaprefers to the parameter ofapplyrootinsidemaprefers to new value being created for each invocation of the map
- Can be applied to single values or to the entire object recursively.
// use map for a specific case map parse_talking_head { let split_string = this.split(":") root.id = $split_string.index(0) root.opinions = $split_string.index(1).split(",") } root = this.talking_heads.map_each(raw -> raw.apply("parse_talking_head")) // apply for the whole document recursively map remove_naughty_man { root = match { this.type() == "object" => this.map_each(item -> item.value.apply("remove_naughty_man")), this.type() == "array" => this.map_each(ele -> ele.apply("remove_naughty_man")), this.type() == "string" => if this.lowercase().contains("voldemort") { deleted() }, this.type() == "bytes" => if this.lowercase().contains("voldemort") { deleted() }, _ => this, } } root = this.apply("remove_naughty_man")
- We create
-
this& named contextthispoints to the “context”- Usually it points to the
input document, but based on usage it can point to other things, eg. inside amatchblock,match this.petnow inside thematchblock,thiswill point to the document inside the outerthis.pet, i.e reducing boilerplate inside thematchblock. - Instead of
this, we can also use named context with<context name> -> <blobl query>
-
thisandroot&mappingmapping“most of the time” refers to mappingJSON(structured) documents(Bothnewandinputdocuments)mappingpurpose: construct a brandnew documentby using aninput document as a reference- Uses
assignments, everything is an assignment, even deletion!
- Uses
- components
root: referring to the root of thenew documentthis: referring to the root of theinput document
- In a
mapping, on the LHS, if you omitroot, it’ll still be root of the new document. i.eroot.foois same asfooon lhs.
-
Non JSON documents
this(“this” is JSON specific)thiskeyword mandates that the current in-flight message is in JSON format- You should first ensure that your message is valid JSON by using
logprocessor (if it’s not, you can use thecontent()function in amappingprocessor to extract the message data and parse it somehow)
content()- Can be used in mapping the input as a binary string.
Eg. root = content().uppercase() vs root = this, result is similar butthisis json specific but withcontentwe’re reading with raw data.
- Can be used in mapping the input as a binary string.
Other notes
- @ vs meta
- root.poop = meta(“presigned_url”) # string
- root.doop = @presigned_url # binary
-
WASM
- I recommend using the redpanda_data_transform processor in connect. It’s based on WebAssembly and rpk can generate the boilerplate for you
- follow this tutorial: https://docs.redpanda.com/current/develop/data-transforms/run-transforms/
- But instead of using rpk transform deploy,
- point the built wasm module using https://docs.redpanda.com/redpanda-connect/components/processors/redpanda_data_transform/ that module_path property is a path to the wasm file from rpk transform build
- docs.redpanda.com
- Data Transforms in Linux Quickstart | Redpanda Self-Managed
- Learn how to build and deploy your first transform function in Linux deployments.
things ppl say
- We use debezium to stream CDC from our DB replica to Kafka.
- We have various services reading the CDC data from Kafka for processing