tags : Database
FAQ
How does Supabase work?
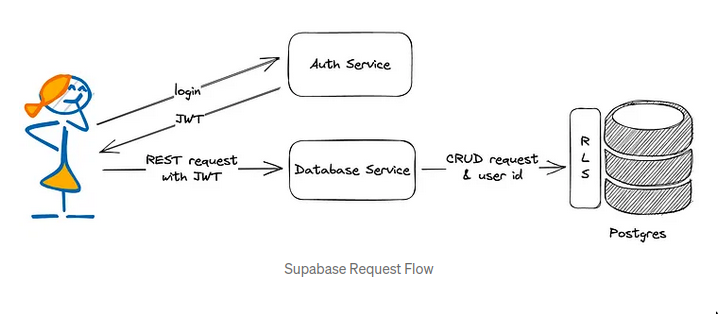
- Supabase is more of BaaS (Backend-as-a-Service) than a Database service
- Every table, view, and stored procedure is automatically mapped to a RESTful API.
- Supabase uses PostgREST
- See
What’s PostgREST?
- Also see REpresentational State Transfer, PostgREST is not really REST.
- PostgREST is based on the idea if you are accessing the database as a particular user, Row Level Security (RLS) will ensure that you’ll have access to the data you need.
- Users need to be authenticated and authorized.
- As this is like the backend now, some kind of pool for connections would be needed
- Its API looks like a mixture of RESTful and GraphQL.
How to use EXPLAIN?

- Can give you the cost before hand
- Can estimate how many rows it’ll return etc.
How to use ANALYZE?
- It runs the shit that collects the statics that the query planner uses and what we see when we run
EXPLAIN
Postgres by default runs in read committed, so transactions are not serializable. How is this acceptable?
- With
read committed, Query in a transaction- Sees only data committed before the query began;
- Never sees uncommitted data
- Never sees changes committed by concurrent transactions during the query’s execution
- This is slightly different for writes( See MVCC )
- The partial transaction isolation provided by Read Committed mode is adequate for many applications
Postgres Schema and Database Objects
Meaning of schema
- The concept of a schema is not very consistent between DBMSs.
- In mysql, it calls schemas databases, and only has one database.
- Schemas are the implementation in postgres of the namespace concept. It’s a collection of logical structures of data.
- This is different from the general idea of database schema
SHOW SEARCH_PATH
Hierarchy of “things” in postgres
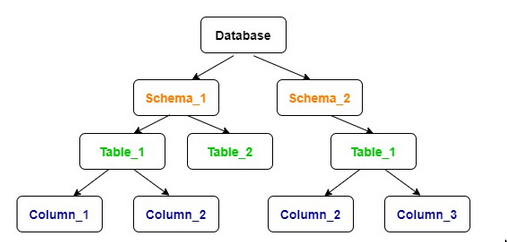
- A single machine/host can have multiple
clusters, clusters run in aport - A
clustercan have manydatabases,roles/usersand moreclusterlevelobjects. i.eroleanddatabaseare couples. butrolekeeps cheating, so a singlerolecan be the owner of multipledatabases. - Then we have
databaselevelobjects- Belonging to some
schema(namespaced)- Eg.
Tables,views, sequences, functions, procedures, types, domains, etc. - Eg.
Indexesandtriggersare always created in the same schema as the table they are for.
- Eg.
- Not belonging to some schema (no namespace)
- Eg. Extensions
- Belonging to some
- There can be
schemaswith the samenamein differentdatabases(but not in the samedatabase). objectsfrom onedatabasecannot interact withobjectsfrom another one (catalogs are kept separated). Eg. we can’t join across two databases. Useschemainstead.- A
databasecan have multipleschemas
Understanding usecase of schema and search_path in postgres
- Organization
- Think of
schemalike directories and database objects as files. You can do without directories but it helps organize. - Eg. In a single database, you can have schemas like
ecommerce,authetc. - Helpful in dumping, selecting all tables in a schema etc.
- Think of
- Access control
- This has roots into the usecase where a database has multiple users. In our web application world, we usually have one user accessing it. So we set the
search pathin the connection string. - Grant
privilegestorolesatschemalevel, so that allobjectsinside thatschemawill have those access.
- This has roots into the usecase where a database has multiple users. In our web application world, we usually have one user accessing it. So we set the
When to create schema, when to create database?
- If projects/users should be separate and be unaware of each other:
databases - If projects/users are interrelated, should be able to use each other’s resources:
schemas
search path and schema
search path
- When using schema, you need to use “qualified” names. Instead you can use
search path - If
objectis referenced withoutschemaqualification, thesearch pathis traversed until a matching object is found. schema pathis a list of path, whichever is found first is used.- The first schema in the
search paththat “exists” is the default location for creating new objects. - That is the reason that by default objects are created in the
publicschema.
- The first schema in the
- Eg. follwing shows tables from all schema
\dt *.*
Builtin schema
publicschema: There’s nothing special about the public schema except that it exists by default. It can be dropped, too. It’s just is there when you create a newdatabase, so if you createobjectswithout specifying any schema, it’ll go land up in thepublicschema of thedatabase.pg_catalogschema: Contains the system tables and all the built-in data types, functions, and operators.pg_catalogis always effectively and implicitly part of thesearch path.
Related access control notes
PUBLIC role / keyword
- It’s not exactly a
rolebut a keyword that can be a placeholder forrole - This keyword usually means “everyone”
- This is different from
publicschema. eg.REVOKE CREATE ON SCHEMA public FROM PUBLIC;(first “public” is the schema, the second “public” means “every user”) - It used to gives create permission on the
public schemato “all” users despite what grant is at play.USAGEprivilege granted toPUBLIC: Allows anyone to refer to objects in the public schema.CREATEprivilege granted toPUBLIC: Allows anyone to create objects in the public schema.- This is problematic!
- Postgrs14 onwards there is a fix for this issue
- new role
pg_database_owner, implicitly has the actual owner of the current database as a member. - public schema is owned by
pg_database_ownernow. - public schema does not have
CREATEprivileges anymore.
- new role
Postgres Syntax notes
JSONB
- Prefer jsonb over json if possible
Operators & Functions
- Checks
- exists:
?,?|(any),?&(all)- eg.
SELECT '["foo", "bar", "baz"]'::jsonb ? 'bar'; - Not nested
- works with array items
- works only with keys when items in array are objects
- eg.
- containment
<@- Can operate on nested elements
- Eg.
SELECT doc->'site_name' FROM websites WHERE doc @> '{"tags":[{"term":"paris"}, {"term":"food"}]}';
@>
- exists:
- Access
- subscripting
[x](Extract & Modify jsonb)- Result of subscript always a
jsonb - Array indexes start at 0, -ve indexes supported
- Can access nested element by successive subscripting
- Result of subscript always a
->- Array(index) and object(key) access
->>- Array(index) and object(key) access
as text
- Array(index) and object(key) access
#>(path)- Array(index) and object(key) access
#>>(path)- Array(index) and object(key) access
as text
- Array(index) and object(key) access
- subscripting
- Manipulation
||: concat objects-: subtract keys
Updating jsonb values
It’s important to note that in each of these examples, you’re not actually updating a single field of the JSON data. Instead, you’re creating a temporary, modified version of the data, and assigning that modified version back to the column. In practice, the result should be the same, but keeping this in mind should make complex updates, like the last example, more understandable. SO answer
- Ways to do it
UPDATE&SETUPDATE&SETcombined will work with subscripts- Eg.
UPDATE table_name SET jsonb_column_name['a']['b']['c'] = '1'; - This will create nested parent element if they don’t exist
- Unlike(?)
jsonb_set, it’ll try to fill things with null, and consider null column as{}etc.
- Eg.
- When using this, we can also use
||for “merge” like operation, this is useful when doing ON CONFLICT UPDATE for jsonb. See How can I merge an existing jsonb field when upserting a record in Postgres?- But this merge is only shallow, doesn’t work with nested JSON.
- For nested JSON check these:
- json - Merging JSONB values in PostgreSQL? - Stack Overflow (Vanilla PG, has nice answers)
- Use a separate Procedural Language add-on like PLV8
- https://gist.github.com/phillip-haydon/54871b746201793990a18717af8d70dc (function using plv8)
jsonb_set- Returns target with the item designated by
pathreplaced by new_value, or with new_value added. - Useful when you know the structure of the json.
- It can also do merging if you specify the path. But not much useful when you’re unaware of the structure.
- Returns target with the item designated by
Indexes on jsonb
- To use indexes(GIN), we need to apply the operator on the entire column of jsonb type, picking on specific field would not make use of the index if using
simple index, otherwise we can useexpression indexfor specific field in the json document. - Supported operators:
?,?|,?&,@>, jsonpath operators@?,@@
-
Types
jsonb_path_ops- Seems to have some advantage over
jsonb_opsthat I don’t care about at the moment
- Seems to have some advantage over
jsonb_ops- simple & expression
-
Expression indexes vs Simple indexes (jsonb_ops)
- Simple index
- Eg.
CREATE INDEX idxgin ON api USING GIN (jdoc); - Will store copies of every key and value in the jdoc column
- More flexible, supports any key but bigger in size and might be slower
- Eg.
- Expression index
- Eg.
CREATE INDEX idxgintags ON api USING GIN ((jdoc -> 'tags')); - Stores only data found under the
tagskey in the example
- Eg.
- Simple index
Management/Admin
See Operations cheat sheet - PostgreSQL wiki
See Difference between running Postgres for yourself and for others
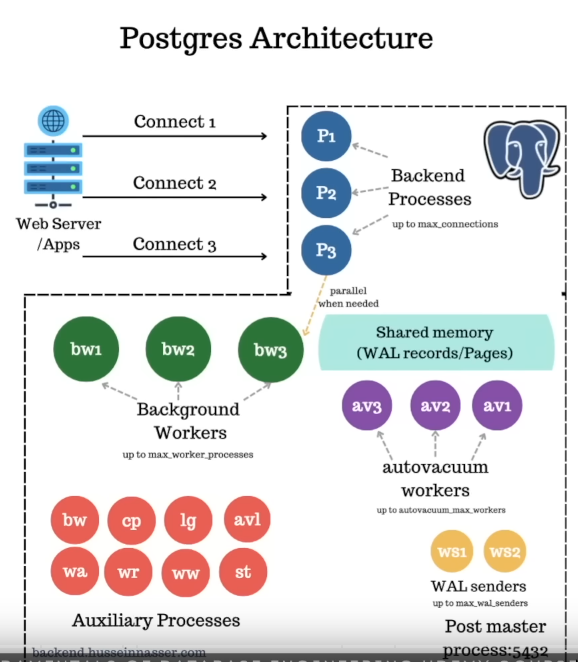
Postmaster & Backend workers & Backend processes
postmasteris the primary daemon process for a PostgreSQL server.- The use of term is not done these days, the primary daemon process is simply being called
postgresnow. - Responsibilities
- Initializes the database system, prepares it for incoming connections, and ensures that the system is in a consistent state.
- Manages connections (spun off processes/
backends processes) - Logging
Backens processes- Config:
max_connections - Backend processes communicate with each other and with other processes of the instance using
- semaphores and shared memory to ensure data integrity throughout concurrent data access.
- i.e
connection=backend process=session(unless usingpools)
- Config:
Background workers- Config:
max_worker_processes - The
backend processesspin up thebackground workersfor actual work if parallel is enabled. - This is different from
background writerwhich is a Auxilary process.
- Config:
Shared Memory
- As we read things from the disk etc. we put things in memory
- Everything that is shared, it lives here. Pages, WAL records etc.
- Every
backend processandbackend workerand everything else has access to it. - Related terms:
shared_buffers, buffer pools - Provisioned by mmap (?)
Auxiliary Processes
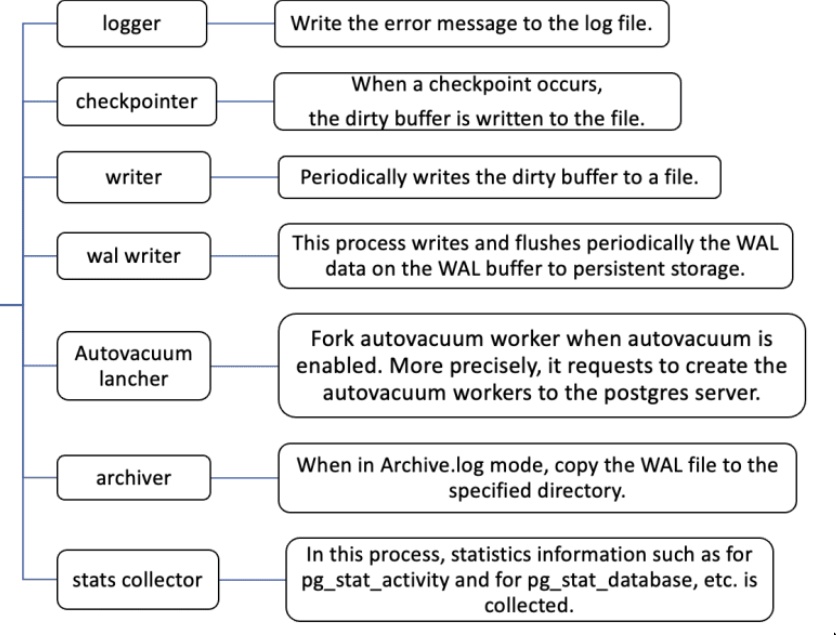
background writer: It writes the dirty pages to the OS periodically. So it frees up shared memory in thepostgresprocess but doesn’t ensure that shit actually got to disk, that’s upto the os whether it keeps it in the fs chache or what etc.checkpointer: Flushes pages+wal to disk. Ensure that things have reached the disk.Autovacuum Launcher- config:
autovacuum_max_workers - It launches
autovacuumworkers
- config:
walarchiver: Archives everything for the wal (can be used for replay)reciever: Runs where we want to receive the WAL changes.senders: Senders of the WALs to replicaswriter: Writing the WAL records from shared memory to disk. Controlled bywal_writer_delay
starter- This combines
checkpointerandwalfor REDO(roll-forward recovery). - Doesn’t let any incoming connection till it ensures that it loaded the wal into the shared memory and made that data dirty before the
checkpoint - Now you’re back in the same point before the crash happened.
- This combines
Cluster
What it’s NOT
- It is NOT what we popularly understand as cluster(compute cluster). This tripped me up for years man.
- If you were do that, you’ll end up creating cluster of postgres clusters. (This is basically bad naming for historic reasons)
- It’s unrelated to the keyword
CLUSTERwhich allows you to organize a table.
What it is
- A
postmaster/ primary postgres process and a group of subsiduary processes - These processes manage a shared data directory that contains one or more databases.
- It’s created for you when you do
initdb - Unusual for a basic or intermediate user to ever need to create clusters or manage multiple clusters as one cluster can manage multiple DBs
- Having multiple cluster means having >1
postmaster/ primarypostgresprocesses running on different ports. This is usually not needed. - See PostgreSQL: Documentation: 16: 19.2. Creating a Database Cluster
System Metadata
System Catalogs
System Views
Users and Roles
- ALTER: Modify a role for its attributes
- GRANT/REMOVE: Groups/Memberships leading to inheritance of privilege
Roles
select * from pg_roles;same as\du- PostgreSQL manages database access permissions using the concept of
roles - They have nothing to do with OS user.
ROLE= user / group of users. (Any role can act as a user, a group, or both)- Some attributes: SUPERUSER,CREATEDB,CREATEROLE,INHERIT,LOGIN,REPLICATION,BYPASSRLS (from the
CREATE ROLEcommand) - Can own
databasesobjectsin thatdatabase
- Can have
privilegesonobjects
- Can give/grant
accessto otherrole(s) on the ownedobjectsmembershipin itsroleto anotherrole(once two roles sharemembership, they can shareprivileges)
-
Predefined roles
- Predefined roles were introduced in pg14.
- Useful for things like granting readonly access etc.
-
“postgres” role
- The default
postgresrole doesn’t have an “empty password”, it literally has no password which means one cannot connect using a password-based method.
- The default
Privileges
objectscan require certainprivilegeto be accessed.- This
privilegecan be granted toroles- Indirectly: from
other roles - Directly: to
objects - See GRANT for more info.
- Indirectly: from
-
Inheritance
- Whether the
privilegesof the grantedroleshould be “inherited” by the new member. - NOTE: It does not apply to the special role attributes set by CREATE ROLE and ALTER ROLE.
- Eg. Being a member of a role with CREATEDB privilege does not immediately grant the ability to create databases, even if INHERIT attribute is set
- Controlled in 2 places
- Role level: Role can have the
INHERITattribute to inherit. - Command level:
GRANThasWITH INHERITto explicitly inherit.
- Role level: Role can have the
- Whether the
-
ALTER
- Assigned attributes to a
ROLEcan be modified withALTER ROLE ALTER DEFAULT PRIVILEGESallows you to set the privileges that will be applied to objects created in the future. (It does not affect privileges assigned to already-existing objects.)
- Assigned attributes to a
GRANT / REVOKE
- Used for mutating
membershipsand privilege to objects - GRANT and REVOKE can also be done by a
rolethat is not the owner of the affected object- If it is a member of the role that owns the object
- If it is a member of a role that holds privileges
WITH GRANT OPTIONon theobject.
- Can be GRANT’ed on 2 things
objects- GRANT INSERT ON films TO PUBLIC;
- GRANT ALL PRIVILEGES ON kinds TO manuel;
- One of: SELECT,INSERT ,UPDATE ,DELETE ,TRUNCATE ,REFERENCES ,TRIGGER ,CREATE ,CONNECT ,TEMPORARY ,EXECUTE ,USAGE ,SET ,ALTER SYSTEM and
ALL PRIVILEGES
roles- Eg. Grant membership in role
coolboisto userjoe:GRANT admins TO joe;
- Eg. Grant membership in role
Links
- Application users vs. Row Level Security - 2ndQuadrant | PostgreSQL
- PostgreSQL: Documentation: 8.1: Database Roles and Privileges
- PostgreSQL: Documentation: 8.1: Role Attributes
Timeouts
Vertically Scaling Postgres (Finetuning with ZFS)
 See
See - https://people.freebsd.org/%7Eseanc/postgresql/scale15x-2017-postgresql_zfs_best_practices.pdf
- Everything I’ve seen on optimizing Postgres on ZFS
- Templates/References
WAL management
- https://www.postgresql.org/docs/current/runtime-config-wal.html#GUC-CHECKPOINT-TIMEOUT
- postgresql - WAL files management - Database Administrators Stack Exchange
Should WAL be stored separate (It depends buit not really necessary)
- https://dba.stackexchange.com/questions/10053/is-wal-database-log-on-separate-disk-good-idea-on-raid10
- https://www.reddit.com/r/Database/comments/16jisvt/is_it_recommended_to_store_logfiles_on_a_separate/
- https://stackoverflow.com/questions/19047954/where-is-the-postgresql-wal-located-how-can-i-specify-a-different-path
- https://www.postgresql.org/docs/current/wal-intro.html
Logged vs Unlogged Tables
Table level version of wal_level=minimal

Checkpoints and WAL
- Default WAL: Checkpoints can reconstruct data from WAL if needed
- Minimal WAL: Checkpoints write data directly, with no WAL-based reconstruction capability
TLS/SSL for postgres
- TLS/SSL in a trusted network is not really necessary for postgres
- But you still would want to have SCRAM even in trusted networks
- Most of the time since pg would not have a public domain, you’d need to use self signed certificates instead of say LE.
TLS w PgBouncer
- Usually, when you do this, you’d have the certificate terminated at pgbouncer and the connection from pgbouncer to postgres would usually be trusted.
- See Certificate failure using tsl with pgbouncer and Postgres for more info
TODO TLS w/o PgBouncer (vanilla)
Optimizing Postgres
- https://www.crunchydata.com/blog/understanding-postgres-iops
- Database Tuning at Zerodha - India’s Largest Stock Broker - YouTube
- How to get the most out of Postgres memory settings | Hacker News
- PostgreSQL Statistics, Indexes, and Pareto Data Distributions | Hacker News
- Operating on a minimal two-core Postgres instance: Query optimization insight…
- Ten years of improvements in PostgreSQL’s optimizer | Hacker News
- max parallel workers
Reindex
- Issues
- Downtime: The REINDEX operation may lock tables, preventing writes (and possibly reads, depending on the PostgreSQL version and reindex method). Plan to run this during a maintenance window or at off-peak times.
- Disk Space: Reindexing can require a significant amount of disk space, temporarily duplicating the size of the indexes.
- Backups: Ensure that your databases are fully backed up before running this script.
Backup and Replication & Upgrade
- Backup and replication are related in postgres. While backup methods need to be looked at separately, the part where backups are done continuously it uses what we have for replication in postgres and vice-versa.
Following table is specific to postgres terminologies
| Backup | Replication | |
|---|---|---|
| Physical | Backing up of on-disk structure(can be continuous or snapshot) | Same as Streaming replication, streaming of literal bytes on disk(WAL in case of PG) |
| Logical | sql_dump | |
| Synchronous | Not a thing | Usecase of streaming replication (greater consistency guarantee) |
| Asynchronous | Not a thing | Usecase of streaming replication |
| Streaming | Same as Physical Backup (Sub category) | Same as Physical replication |
| Snapshot | Same as Physical Backup (Sub category) | Not a thing |
Meta ideas for replication and backups in postgres
Standby servers
Standby servers are usually read-only, unless promoted to be primary.
-
Warm standby (pg_standby) / Log shipping (2008)
- AKA “Log shipping”
pg_standbyis more of a restore utility
pg_standbyis no longer the most popular choice for doing streaming backup/restore as of postgres16.- It stays in permanent recovery(keeps applying WAL) until promotion/trigger(
manual intervention), so it couldn’t be read from as it was replicating. Usually some lag from primary will be there. pg_standbyallows creation of this.pg_standbyruns on a separate server than the primary server, and depends on the primary server to set properarchive_command,archive_library,archive_timeoutetc. So thearchive_commandwill somehow(eg. rsync) transfer the WAL files into the standby server and standby server would runpg_standbyas therestore_commandtrying to keep reading the WAL and gets triggered based on a file to change its mode from “standby” whenever thereis a failoverscenario.- There are newer alternatives like pg_receivewal for shipping logs. BUT IT SHOULD NOT BE USED WITH
remote_applybecause it’ll never apply. It uses the postgres streaming protocol but it’s NOT A SYNCHRONOUS SERVER, it just streams WAL into file system using the streaming protocol.
- There are newer alternatives like pg_receivewal for shipping logs. BUT IT SHOULD NOT BE USED WITH
-
Hot standby (2010)
- +1up from warm standby.
warm standbyonly were useful in failover scenarioshot standbyyou could use secondary servers to spread out read-only loads.
- Ability to connect to the server and run read-only queries while the server is in archive recovery or standby mode.
- Hot standby allows read-only queries and can be quickly promoted.
- CAN BE PROMOTED TO
PRIMARYfromSTANDBY“QUICKLY” - Q: What allowed hot standby to be possible?
- Hot standbys were enabled by improvements in different areas, Improved WAL record interpretation, Advanced buffer management, Enhanced transaction visibility logic, Conflict resolution mechanisms, Special handling for read-only transactions etc.
- +1up from warm standby.
-
Synchronous standby
- Rare usecase, stronger consistency guarantees
- Ensures transactions are written to both primary and standby before considering them committed.
- This usecase is different than WAL archiving, WAL archiving is needed for PITR
- 2 SYNCHRONOUS STANDBY BAD! 3 STANDBY GOOD!
- a basic two-server setup, if the standby goes down, the primary may become unavailable for writes, waiting indefinitely for confirmation from the standby.
- This CANNOT be achieved with WAL archiving alone because that WAL archiving works at WAL segments granularity and this is about granularity at commit level. and it’ll be too slow.
- For this we NEED to use
streaming replication protocol- Need to configure
synchronous_commitandsynchronous_standby_nameson the “PRIMARY”
- Need to configure
- Can be warm or hot(allows readonly queries)
- Using
hot_standby = on
- Using
-
Synchronous v/s Async commit
When using
remote_applywe need to cautious to not use it withpg_recievewalas it’ll never apply aspg_revievewaldoesn’t apply, it’s fine to use otherwise.
- It is possible to have both synchronous and asynchronous commit transactions running concurrently
- Certain transactions are always synchronous, eg. DROP TABLE, Two Phase Commit (2PC) prepared transaction etc.
- Options:
on: Wait for WAL local flush to disk. (default)off: Don’t wait for any confirmation (fastest but least safe)- PostgreSQL: Documentation: 16: 30.4. Asynchronous Commit
- This introduces the risk of data loss. (not data corruption)
- max delay is
wal_writer_delay, better than turningfsyncoff as no data inconsistency. - But for things like Event Logging, maybe this would be fine
- If using “synchronous standby servers” using
synchronous_standby_names, then- When any of these are applied we’re same as
on(locally) remote_write: Wait for standby to receive and write (but not flush) the dataremote_apply: Wait for standby to receive and apply the transactionlocal
- When any of these are applied we’re same as
Q: How to do manual syncing two databases (for development)
Following is from reddit comment from /u/Key-Chip
pg_dump and pg_restore: This is a standard PostgreSQL tool for backing up and restoring databases. You can use pg_dump to dump the data from the source database into a file, transfer that file to the destination server, and then use pg_restore to restore it into the destination database. This method is efficient for large datasets and can be scripted for automation.pg_dump with custom format and pg_restore: Using pg_dump with the custom format (-Fc flag) allows for parallel dumping of data, making it faster. Then, you can use pg_restore to restore the dumped data into the destination database.psql with COPY command: The COPY command in psql allows you to copy data between tables, or between a table and a file. You can use this to export data from the source database to a file, transfer the file, and then import it into the destination database. However, this method might not be the most efficient for very large datasets.Foreign Data Wrapper (FDW): PostgreSQL supports FDWs, which allow you to access data stored in remote databases as if they were local tables. You can set up an FDW in the destination database that connects to the source database, and then use SQL to insert the data directly from one database to the other.
Q: When do we evolve from “streaming replication” to needing multi-master etc. kind of setups?
- Read this: https://www.reddit.com/r/PostgreSQL/comments/122p5am/can_someone_share_experience_configuring_highly/ (Holy grail)
- See Data Replication
- If you have such requirement, rather than trying to make PG fit in those maybe check something else, otherwise following link discusses postgres HA if we really need it.
- While
streaming replicationandlogical replicationare officially supported features, and the replicas(standby(s)) are always read-only. - Multi-master replication allows multiple database servers to accept write operations and replicate changes between each other. And for leader-follower there are different variants there aswell. But as far as postgres goes we can consider the ones officially supported.
streaming replicationitself seems like a variant of leader follower. - Some third-party solutions attempt to provide this functionality.
- When this functionality is needed, better to jump ship and use something else. See Scaling Databases and Data Replication.
TODO Postgres Major version upgrade
- Postgresql Cluster Upgrade - Part 1: Foundations of production changes - YouTube 🌟
- Postgres major version upgrades with minimal downtime
- https://gist.github.com/take-five/1dab3a99c8636a93fc69f36ff9530b11 (archievbd)
- https://www.reddit.com/r/PostgreSQL/comments/1bpcu5d/logical_replication/
- https://knock.app/blog/zero-downtime-postgres-upgrades
Replication
Oogabooga replication / Log shipping / File based
- This is what happened first
- Ship WAL logs continuously to remote destination and continuously keep reading from it. This is what
pg_standbydid.
Streaming replication / Streaming binary / Streaming wal records/commits
- Good guide: https://www.reddit.com/r/PostgreSQL/comments/9fjeoe/postgresql_tutorial_getting_started_with/
- https://www.interdb.jp/pg/pgsql11.html
- PostgreSQL: Documentation: 16: Chapter 27. High Availability, Load Balancing, and Replication
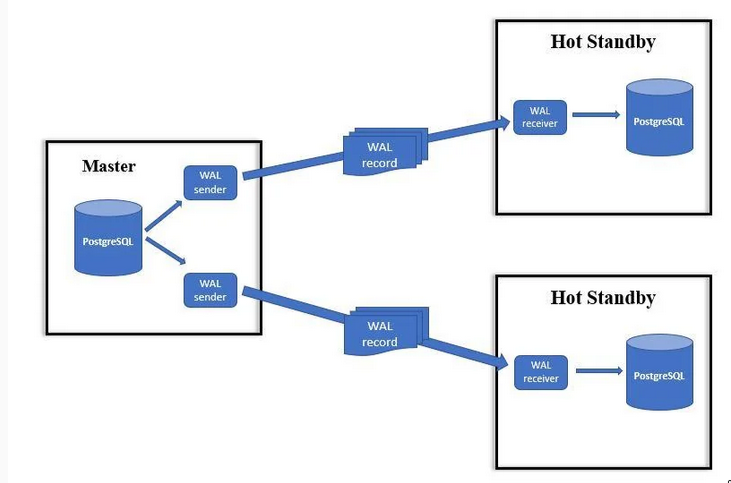
- Instead of relying solely on the WAL archive and recovery functionalities to transport WAL data, a standby server could connect directly to the primary server via the existing
libpqprotocol and obtain WAL data that way, so-calledstreaming replication.- This is much faster than log based WAL archival
- This is a
Leader <--> Followersetup. i.e only one read&write others will be readonly.
-
Side effects
-
synchronous standbys/replication
- Allowing commits to be received/applied by standbys
- 2 SYNCHRONOUS STANDBY BAD! 3 STANDBY GOOD!
- a basic two-server setup, if the standby goes down, the primary may become unavailable for writes, waiting indefinitely for confirmation from the standby.
-
pg_basebackuppg_basebackupwould use a normal libpq connection to pull down a base backup, thus avoiding complicated connection and authentication setups for external tools.- Makes the base backup easier instead of having to use
rsync.
-
cascading replication
- Allowing standbys to be created from standbys
pg_basebackupcould do this
-
pg_last_xact_replay_timestampfunction for easy monitoring of standby lag.
-
-
The streaming replication protocol (builtin)
- Enabled by
synchronous_standby_nameand optionally setting/????synchronous_commit - primary method of replication in PostgreSQL. It allows the standby server to connect directly to the primary and receive WAL records as they’re generated, reducing lag.
- WAL data is sent immediately rather than waiting for a whole segment to be produced and shipped.
- Enabled by
-
TODO Replication Slot
- The Insatiable Postgres Replication Slot - Gunnar Morling
- Is replication slot of any concern for Logical replication?????
- NOOOOOO, it’s needed when taking streaming replicaton etc
Logical replication
-
Usecase
- Logical replication is therefore a good option when your target is not Postgres
- Not a good usecase for “postgres backup”
-
History
- PostgreSQL 9.4: Logical decoding
- Introduced in PostgreSQL 10, this method allows replication of specific tables rather than the entire database. It’s more flexible but can be more complex to set up.
- In logical replication setups, subscribers can be writable, but these are not the same as physical standbys.
-
Main ideas
- publishers (servers that do CREATE PUBLICATION)
- subscribers (servers that do CREATE SUBSCRIPTION)
- Servers can also be publishers and subscribers at the same time.
wal_levelneeds to belogical(for logical decoding)- Logical replication allows replication of data changes on a per-table basis. In addition, a server that is publishing its own changes can also subscribe to changes from another server, allowing data to flow in multiple directions.
- third-party extensions can also provide similar functionality.
-
Gotchas
- I thinks if you have things like CURRENT_TIME(), NOW(), those things will be executed on the replica?? (and will drift from original), this problem is not there with physical replication. I am not sure if this is what actually happens. This is a doubt.
-
Postgres CDC
- WAL2JSON plugin is Debezium,
- See CDC ( Change Data Capture )
-
Resources
- pg_flo – Stream, transform, and re-route PostgreSQL data in real-time | Hacker News
- Logical replication in Postgres: Basics | EDB
- https://www.postgresql.org/docs/16/logical-replication.html
- https://gist.github.com/take-five/1dab3a99c8636a93fc69f36ff9530b11
- https://www.reddit.com/r/PostgreSQL/comments/1bpcu5d/logical_replication/
- https://www.2ndquadrant.com/en/blog/logical-replication-postgresql-10/
- https://medium.com/@piyushbhangale1995/logical-replication-in-postgresql-c448e4b3eb95
- https://www.crunchydata.com/blog/postgres-wal-files-and-sequuence-numbers
- https://amitkapila16.blogspot.com/2023/09/evolution-of-logical-replication.html
- https://www.pgedge.com/blog/logical-replication-evolution-in-chronological-order-clustering-solution-built-around-logical-replication
- https://wolfman.dev/posts/pg-logical-heartbeats/
Backup
| Type | Tool | Nature | Use |
|---|---|---|---|
| Logical | SQL Dump | Consistent but might not be uptodate | OK for small scale, can combine w restic |
| Physical | File/Data/FS Backup/Snapshot | STW(Frozen), might need to stop pg | OK for small scale, can combine w restic |
| Physical | Continuous Archival | Useful when large DB, no extra space to take a pg_dump |
SQL Dump (Logical)
When you somehow backup the shape and state of the data. Later you’d have a way to put it back together. Backups the “database objects”.
pg_dump: Takes consistent backups, other writes can keep happening concurrently. But using this as a backup solution might result in data loss. It’ll read every(based on params) db object, converting it to equivalent SQL, and writing it to some location.- This is what you’d call a “full backup” I presume.
- use
pg_dumpwith-Fcto ensure that you are using a custom format. This is the only way to prepare to do a parallelized restore using pg_restore (with the -j parameter)
- Concerns
- If a system has a simple pg_dump cron job that ships the archive to remote storage, when the leader crashes or dies, the time to detection, copying the archive to the follower, pg_restore completion times is the amount of downtime that’s required.
- The cron job, if configured at a certain time in the day, differs from the time the crash happens, the delta in the data until that time on the leader is a potential loss in data.
- It involve duplicating data over and over again. De-dupe(as restic does) doesn’t make sense for Postgres backups, the full/diff/trn-log that
pgbackrestdoes is what’s needed. But guess it works for small databases.
Filesystem Snapshots (Physical)
Can be refered to as snapshot backup. It’s a STW kind of a thing.
- Based on if the FS allows atomic snapshots we might or mightnot need to stop the pg before taking the snapshot
- ZFS filesyste: With ZFS you can trust snapshots + send/recv if, and only if, everything is on the same dataset (WAL and DATA). If you need PITR then you need something like Pgbackrest.
Continuous Archival (Physical)
See the continuous archival section
Continuous Archival
In PG8.0(2005), we had the ability to copy the WAL somewhere else.
With this, we can later play it back, either all the way or to a particular point in time. (ideally taking a
base backup)So (WAL storage separation + ability to replay from any point) = Continuous Archival + PITR
This had NO concept of
replicationinitially. Simple, store the WAL elsewhere and play it back. simple.Later, people figured you could
archive WALon one server and continuouslyrecover WALon another server. This gives us streaming!
- Initially people did this manually, later we got pg_standby with which built-in replication in PG was officially born(2008).
Meta Questions
-
Relevant configs/commands
- WO/RS: Without Replicated Slot
- WRS: With Replicated Slot
Type Strategy Name What it does pg_standbypg_basebackupmax_slot_wal_keep_sizemax_wal_sizepg_start_backuppg_stop_backupwal_keep_sizeSpecifies the minimum size of past WAL files kept in the pg_wal directory, in case a standby server needs to fetch them for streaming replication. Useful in case of slow connection etc. config WAL shipping(WORS)/Streaming/Logical wal_levelNeeds to be replicafor WAL shipping/streaming replicationStreaming max_wal_senders?? archive_modeWAL shipping(WORS) archive_commandtakes in a script (ideally idempotent). If exit status of 0 (success), the WAL file is recycled, otherwise archiving is retried until it succeeds. WAL shipping(WORS) restore_commandWhatever restores the archive on the warm standby when promoted WAL shipping(WORS) archive_timeoutWithout this sending out the archive can have long delays WAL shipping(WORS) archive_cleanup_commandThis needs to be run in the standbyas primary automatically re-cycles WAL entries after checkpoints
-
Tools Exploration
These help you do things like uploading to various object storage services, putting all the files together for restore, manage the lifecycle of the backup files, taking base backup periodically so that WAL replay does not become too big etc etc.
Name Description pg_basebackup official, allows for a base backup wal-g written in go, supports more than postgres pgbackrest See this comparision w barman barman Makes base-backup and does WAL archival repmgr idk what this do I’ve finally decided to go with wal-g for by continious backup strategy
-
WAL Recycling
From the docs
The segment files are given numeric names that reflect their position in the abstract WAL sequence. When not using WAL archiving, the system normally creates just a few segment files and then “recycles” them by renaming no-longer-needed segment files to higher segment numbers. It’s assumed that segment files whose contents precede the last checkpoint are no longer of interest and can be recycled.
Continuous Archival with PITR
When you drop a table in prod, you should be able to easily recover it. PITR allows that.
-
Log shipping based
Main idea
- One base backup as a starting point
- Continuous deltas in the form of the append-only log (WAL) files
NOTE:
- This does not involve it
replication slotas far as i understand. - Unlike “stream replication”, In this we send out by WAL segments(16MB) in certain intervals. So, data loss is still possible as well, since WAL files are only closed and archived at finite intervals. If you archive the WAL every 5 minutes, you can lose 5 minutes of data. But this is still better than using plain
sql_dump
-
Base backup
- Missing WAL logs from the archive might hamper future restore, so regular base backups will help keep the error surface area a little small.
- old base backup + too many WAL logs to restore increase the restore time.
- Use the pg_basebackup command from an external machine (or the same machine, with a different data directory setting), providing the connection info to connect to the leader.
-
WAL shipping
- each WAL file is exactly 16MB, they can be compressed down to only a few KB if they’re mostly empty
- Postgres suggests shipping the WAL per minute
- Allows backups to be taken much more frequently, with the Postgres documentation suggesting frequencies of once a minute.
-
Streaming replication based
Using
truestreaming protocol based replication, do you need- In
streaming replication, WAL data is sent immediately rather than waiting for a whole segment to be produced and shipped.
-
Streaming replication based backup + WAL Archival
- The log is written in 16MB segments in a directory (normally pg_wal). It will keep growing if you have replication slots enabled AND replication is failing (or the link is too slow). It will shrink as the data is able to be replicated.
-
Using replication slot based (no extra WAL archival needed)
- ????
-
pg_recivewalbased- ?????
- In
-
Using both (fallback)
You can and usually should combine the two methods, using streaming replication usually, but with archive_command enabled. Then on the replica, set a restore_command to allow the replica to fall back to restore from WAL archives if there are direct connectivity issues between primary and replica.
-
The case of replication slots
-
Without replication slots
- See this thread: https://www.reddit.com/r/PostgreSQL/comments/18yiyfb/question_on_archive_command_usage_with_streaming/
- Has
barmanusage
- Has
- In the simplest case, you still needed a WAL archive for complete robustness.
- If primary server didn’t actually keep a list of its supposed standby servers, it just streamed whatever WAL happened to be requested if it happened to have it. If the standby server fell behind sufficiently far, streaming replication would fail, and recovery from the archive would kick in. If you didn’t have an archive, the standby would then no longer be able to catch up and would have to be rebuilt.
- >If the asynchronous replica falls too far behind the master, the master might throw away information the replica needs if wal_keep_segments is too low and no slot is used. — What if wal_keep_segments is 0 (default) and a replication slot is in use?
- Then a replication slot is in use, so WAL is retained indefinitely. However, in PostgreSQL 13 there is now a max_slot_wal_keep_size option that sets a limit for slot WAL retention. Consider it an advanced feature, you probably don’t need it. Also note that wal_keep_segments was replaced with the max_wal_size setting.
- streaming replication is possible without using
archive_command- provided the data ingestion throughput never exceeds the rate of the follower streaming the logs directly from the leader, and applying them locally (also depends on the network latency).
- If the follower is not able to keep up with the logs, the logs on leader might get recycled, and the follower will keep waiting for the now-non-existent WAL file. Force-starting the follower in case of failure will result in data loss.
- See this thread: https://www.reddit.com/r/PostgreSQL/comments/18yiyfb/question_on_archive_command_usage_with_streaming/
-
With replication slots (introduced later)
- if you’re using replication slots, then you don’t need walarchive.
-
-
Continuous Archival without PITR (Not recommenced, Not really a backup)
If you drop a table on the master, oops, it’s dropped on the replicas too!
- This is basically
LogicalandStreamingreplication and using it in a way that it can be considered a “backup” for your usecase. - We continuously put the stuff out somewhere but we don’t get any point in time recovery mechanism. We have what we have replicated.
Resources
Features
Temporary Tables
- Implemented like regular tables, but uses
temp_buffersand uses disk for storing metadata and overflows etc. - Unlike regular tables, not guaranteed to be used by multiple connections at the same time, are not subject to locks, are not written to WAL, etc.
- Located in PostgreSQL system tables. In addition, for each table, one or more files are created on disk (by default, in the same folder as the files for regular tables).
- Allows different sessions to use the same temporary table name for different purposes
- Automatically dropped at the end of a session, or optionally at the end of the current transaction based on
ON COMMIT
Issues
- Autovacuum daemon cannot access and therefore cannot vacuum or analyze temporary tables.
- Need to be purged
DELETE ALLbad cuz MVCC is used for Temporary tables aswell and deleting records is slow (See Concurrency)- So we
TRUNCATE:TRUNCATEsimply creates a new file on disk and does an UPDATE of thepg_classtable.
Read more
UPSERT
-- canonical
INSERT INTO table (col1, col2, col3)
VALUES (val1, val2, val3)
ON
CONFLICT conflict_target conflict_action;
-- example
INSERT INTO employees (id, name, email)
VALUES (2, ‘Dennis’, ‘dennisp@weyland.corp’)
ON CONFLICT (id) DO UPDATE;
-- conflict_target: (id)
-- conflict_action: DO UPDATEGranular Access Control
Row Level Security (RLS)
- It needs to be enabled on per-table basis
- Access control is fully modeled inside the database
- It doesn’t matter as who you connect to it anymore
- As long as your request can be appropriately authenticated into a database role for that row in the table you’re good.
- Row security policies can be specific to commands, or to roles, or to both.
Nested/Sub Transactions
BEGIN; -- Start the main transaction
-- Perform some operations
INSERT INTO accounts (account_id, amount) VALUES (1, 1000);
-- Create a savepoint
SAVEPOINT my_savepoint;
-- Perform operations within the nested transaction
INSERT INTO transactions (trans_id, account_id, amount) VALUES (101, 1, 100);
UPDATE accounts SET amount = amount - 100 WHERE account_id = 1;
-- Decide to roll back the nested transaction
ROLLBACK TO SAVEPOINT my_savepoint;
-- The nested transaction's changes are undone, but the main transaction is still in progress
-- Continue with other operations
INSERT INTO logs (message) VALUES ('Nested transaction was rolled back.');
-- Finally, commit the main transaction
COMMIT;- See Database Transactions
- We want to avoid such nested transactions if possible.
- Let the application logic create the transaction and put things in. If possible don’t try to handle this at the DB level.
- Subtransactions can commit or abort without affecting their parent transactions, allowing parent transactions to continue.
- Started using
SAVEPOINT/EXECEPTION
WAL
- See A write-ahead log is not a universal part of durability | Hacker News
- Main idea: Changes to data files (where tables and indexes reside) must be written only after those changes have been logged
- With the WAL, we will be able to recover the database so we need not flush pages on every transaction
- When restoring the WAL after a crash, we’ll recover to the
checkpointcreated by thecheckpointer
WAL flush v/s Data flush
- The WAL file is written sequentially, and so the cost of syncing the WAL is much less than the cost of flushing the data pages.
- If DB is handling many small concurrent transactions, one fsync of the WAL file may suffice to commit many transactions.
commit_delaycan be used to increase the window of transactions to be flushed.
Journaling filesystems
- In certain cases if the underlying Filesystem (the sqlite VFS interface) there’s journaling support, in those cases we can probably not use sqlite journaling and gain some performance gains but this is not needed usually and unnecessarily complex. This can also be vice versa, we can disable filesystem journaling too.
MVCC Implementation
See MVCC
VACUUM
PostgreSQL uses a 32-bit counter for transaction IDs (XIDs), which means there are about 4 billion possible transaction IDs. When a database gets close to using all available transaction IDs, it needs to perform cleanup to prevent what’s called “transaction ID wraparound.”
To prevent this:
- PostgreSQL needs to periodically run VACUUM to mark old transaction IDs as reusable
- The autovacuum daemon typically handles this automatically
- You can monitor the risk using:
SELECT datname, age(datfrozenxid) FROM pg_database;
See A Detailed Understanding of MVCC and Autovacuum Internals in PostgreSQL 14
MVCC & Vaccum relation
-
Transaction IDs (XIDs) and MVCC
- PostgreSQL assigns sequential transaction IDs (XIDs) to each transaction
- These XIDs are 32-bit integers with a finite range of ~2 billion values
- XIDs determine row visibility through PostgreSQL’s MVCC (Multi-Version Concurrency Control)
- Each row has xmin (creation txid) and xmax (deletion txid) that control visibility
-
The Wraparound Problem
- Transaction IDs eventually wrap around after ~2 billion transactions
- Without intervention, this would cause older data to appear to be from “future” transactions
- This would make old data invisible and potentially cause database failures
-
Transaction ID Freezing
- VACUUM identifies rows with transaction IDs older than a certain threshold
- It replaces these old XIDs with a special marker (FrozenTransactionId = 2)
- Frozen rows are considered “always visible” to all transactions
- This process happens globally across the database, not per table
-
Important Considerations
- Regular/autovacuum is critical to prevent transaction ID wraparound
- Every UPDATE creates a new transaction ID (old row version gets an xmax, new version gets an xmin)
- Freezing only affects old transaction IDs; new ones are essential for proper isolation
- Freezing new transactions immediately would break MVCC and transaction isolation
- Unlogged tables still use transaction IDs but skip writing to the WAL for performance
Terms
- Live Tuples : Tuples that are Inserted or up-to-date or can be read or modified.
- Dead Tuples : Tuples that are changed (Updated/Deleted) and unavailable to be used for any future transactions. (This is what Vaccum clears)
Usecase
-
MVCC Version Cleanup
- VACUUM is like a Garbage collector for older versions of rows created by MVCC
transaction idis a32-bit integer- the
VACUUMprocess is responsible for making sure that the id does not overflow. - Never disable the VACUUM, else transaction wraparound
- the
- See Database Transactions
-
Run ANALYZE on tables (
vacuum analyze)- collects statistics and should be run as often as much data is dynamic (especially bulk inserts).
- It does not lock objects exclusive. It loads the system, but is worth it.
- It does not reduce the size of table, but marks scattered freed up place (Eg. deleted rows) for reuse.
-
vacuum full- reorganizes the table by creating a copy of it and switching to it.
- This vacuum requires additional space to run, but reclaims all not used space of the object.
- Therefore it requires exclusive lock on the object (other sessions shall wait it to complete).
- Should be run as often as data is changed (deletes, updates) and when you can afford others to wait.
- If you only have bloated indexes, it would be better to
REINDEX, notVACUUM FULL
Freezing

autovaccum conditions

Views & Materialized views
See SQL for more info on “views” in general.
Maintaining views
-
Theory
- See pgivm docs
-
Implementation
REFRESH MATERIALIZED VIEW- complete re-computation of contents
- Incremental View Maintenance (IVM) (pg extension)
- https://github.com/sraoss/pg_ivm
- more efficient compared to
REFRESH
TODO Locks
- See Database Locks
- Careful with That Lock, Eugene | Robin’s blog
- Row-Level Database Locks Explained - (Read vs Exclusive) - YouTube
Listen/Notify
https://www.postgresql.org/docs/current/sql-notify.html https://tapoueh.org/blog/2018/07/postgresql-listen-notify/ https://www.postgresql.org/docs/current/sql-listen.html
Internals
Pages
- AKA Data blocks
- Page number starts from 0
Buffer Pool
- See https://www.interdb.jp/pg/pgsql08.html
- The buffer pool is an array
- each slot stores one page of a data file.
- The Indices of a buffer pool array are referred to as
buffer_ids
Other extra info on Postgres
Psycogpg2 notes
Core Concepts
Connection > Transaction (each
with connblock) > Cursor
-
Connection
- Encapsulates a database session
- Thread Safe and can be shared among many threads.
- There’s a big problem here. (See my psycogpg2 FAQ section in this note)
- closing a connection without committing the changes first will cause any pending change to be discarded
-
Transactions
- transactions are handled by the
connectionclass- The
connectionis responsible for terminating its transaction, calling either thecommit() or rollback() - If
close()is called or something goes wrong in middle of a transaction its dropped by the db servr
- The
autocommitmodeconnectioncan be set to autocommit mode- no rollback possible
- All the commands executed will be immediately committed
- Transactions are per-session, i.e. per-connection.
- transactions are handled by the
-
Cursor
- Not thread safe
-
Client side cursor
- Allows Python code to execute PostgreSQL command in a database session(
connection->transaction) - Bound to a connection for the entire lifetime
- Allows Python code to execute PostgreSQL command in a database session(
-
Server side cursor
- When creating a cursor, if a name is specified, it’ll be a server side cursor
- By default a named cursor is declared without
SCROLLandWITHOUT HOLD
Context manager (with)
after with exit, it is closed? | after with exit, transaction is committed? | |
|---|---|---|
connection | NO | YES, if no exception. (i.e transaction is terminated) |
cursor | YES, any resources is released | NO, no notion of transaction here. |
withcan be used with bothconnectionandcursor. So thewithexit action only applies if its used to it. Eg. Having aconnectionbut only usingwithwith thecursorwill NOT close theconnection.- In a way using
withforconnectionis more conceptually along the lines of using context manager for thetransaction
- In a way using
- A
connectioncan be used in more than awithstatement (i.e more than one context)- Each with block is effectively wrapped in a separate
transaction
- Each with block is effectively wrapped in a separate
- Since context manager will not handle
connection.close()for you, if you don’t want a long running database session. Make sure to call it wherever it seems fit.
psycogpg2 FAQ
- In the docs there are mentions of
command, it simply means sql query. got me confused.
-
Do we need to commit SELECT(s)?
- SELECT is a transaction
- But you can get by without committing it, but always good to commit it (context managers will do it for you)
-
.commit() vs SQL COMMIT
- See python - Postgres: cursor.execute(“COMMIT”) vs. connection.commit() - Stack Overflow
- TLDR prefer whatever the api provides unless you have other reasons
-
On closing Transaction and Connections
- https://github.com/psycopg/psycopg2/issues/1044
- leaving a transaction open is a worse outcome than keeping a connection open
- “I prefer to have 300 leaking connections open than 3 transactions forgot open on a busy server.”
- Is it required to close a Psycopg2 connection at the end of a script?
- It’s good practice to as soon as you don’t need the connection
- Not closing the connection might have weird errors on logs pg side
-
What about using psycopg2 in multi-threaded setting?
- Multiple concerns
- According to the docs, the
connectionobjects are thread-safe and shareable among threads.cursorsare not.- But cursors created from the same context (connection) are not isolated!
- On top of that it’s not super clear what does
connectionobject being sharable among threads mean. - If if it does need to be very careful when sharing a connection across threads because commits and rollbacks are performed for the entire connection. If you have a multistep transaction and another thread performs a commit in the middle, you may not like the result.
- For all these general confusion, go with the general rule: Each thread should have its own database connection.
- Now we have 2 options
- Create a new connection in each thread and close it
- Something like:
with psycopg2.connect(your_dsn) as conn:
- Something like:
- Use a connection pool
- With psycogpg2 context manager is not supported with pools for, just something to be aware of.
- We should be releasing the connection instead of closing it
- Some more context: Transaction Handling with Psycopg2 | Libelli (might not be 100% correct)
- Create a new connection in each thread and close it
- MAX CONNECTIONS in psycopg2 and ThreadPoolExecutor/ Python Threading
- psycopg2 will just bail out of we reach max connection, so it’s upto us to create appropriate number of threads and make sure we are releasing connection back to the pool
- see postgresql - Python Postgres psycopg2 ThreadedConnectionPool exhausted - Database Administrators Stack Exchange
-
Long running connections
- The difficulty with long-lived connections is that you might not be entirely sure that they’re still there.
- Generally try to close the connection asap if possible
- If using something like a webserver, re-creation of connection can be expecisive. This is when you’d want to use connection pools, server or client side based on the architecture of your application
- The difficulty with long-lived connections is that you might not be entirely sure that they’re still there.
To read (TODO)
- https://www.psycopg.org/docs/usage.html
- https://www.psycopg.org/docs/advanced.html#connection-and-cursor-factories
- https://www.psycopg.org/docs/faq.html
- https://discuss.python.org/t/stuck-with-psycopg2-multithreading/39918/3
- https://www.timescale.com/blog/when-and-how-to-use-psycopg2/
Relevant Notes
- Initializing a postgres directory: After logging into the
postgresuser, you can create a directory with necessary postgres files with theinitdbcommand. It creates a directory in the file system and then you can start a postgres server directing it to that directory. - Tablespaces: All tables are by default created in
pg_defaulttablespace, creating in a tablespace does not affect the logical SQL schema.
Tools
Routing
Others
- Ways to capture changes in Postgres | Hacker News
- Richard Towers | Representing graphs in Postgresql
- https://github.com/pganalyze/libpg_query
- https://github.com/cybertec-postgresql/pgwatch2
- https://github.com/citusdata/pg_cron
- Postgres Just Cracked the Top Fastest Databases for Analytics | Hacker News
- https://github.com/cybertec-postgresql/pg_timetable
Extension
- The time keepers: pg_cron and pg_timetable | Hacker News
- Pg_jsonschema – JSON Schema Support for Postgres | Hacker News
Ecosystem
- gunnarmorling/pgoutput-cli: Examining the output of logical replication slots using pgoutput encoding
- https://github.com/dalibo/pg_activity : htop for pg
- https://gitlab.com/dmfay/pdot
- https://github.com/dataegret/pgcompacttable
- https://notso.boringsql.com/posts/the-bloat-busters-pg-repack-pg-squeeze/
- PgAssistant: OSS tool to help devs understand and optimize PG performance | Hacker News 🌟
Links
- https://challahscript.com/what_i_wish_someone_told_me_about_postgres
- Notes on tuning postgres for cpu and memory benchmarking | n0derunner
- How Postgres stores data on disk – this one’s a page turner | drew’s dev blog
- Types of Indexes in PostgreSQL
- Setting up PostgreSQL for running integration tests | Lobsters
- https://twitter.com/samokhvalov/status/1713094683159941508
- https://twitter.com/samokhvalov/status/1713094683159941508
- https://twitter.com/samokhvalov/status/1702812327261950130
- Explain Guide
- https://github.com/allaboutapps/integresql
- Five Tips For a Healthier Postgres Database in the New Year
- Making PostgreSQL tick: New features in pg_cron | Hacker News
- An automatic indexing system for Postgres | Hacker News
- https://roadmap.sh/postgresql-dba
- Postgres schema changes are still a PITA | Lobsters
Other comments
-
Some PostgreSQL footguns:
- default configuration
- long transactions mixed with OLTP workload
- repmgr (and other HA tools not based on consensus algorithms)
- LISTEN/NOTIFY
- “pg_dump is a utility for backing up a PostgreSQL database” says the official doc
- moving/copying PGDATA and ignoring glibc version change
- hot_standby_feedback on/off dilemma
- partitioning of tables having high number of indexes and receiving QPS >> 1k
- “setting statement_timeout in postgresql.conf is not recommended because it would affect all sessions” says the official doc
- using replication slots w/o setting max_slot_wal_keep_size
- relying only on statement_timeout & idle_in_transaction_session_timeout and thinking it’s enough (lack of transaction_timeout)
- data types “money”, “enum”, “timestamp” (3 different cases)
- int4 PK
- massive DELETE
- attempts to use transactional version of DDL (e.g., CREATE INDEX) under heavy loads
- subtransactions
- DDL under load without lock_timeout