tags : Database, Database Transactions, Database Indexing, PostgreSQL, Distributed Systems, Concurrency, Concurrency Consistency Models
This is about two or more sessions try to access the same data at the same time. So we put locks in the transactions. So locks are things that we put in transactions.
- In databases, “locks” have a very specific meaning.
- What engineers would call a “lock”, is referred to as a “latch” in DBMS internals terminology.
- A “lock” then is a higher level abstraction that functions as a logical lock rather than a fine-grained physical one.
- Locks are generally used to control access to database objects like rows, pages, tables, etc, to ensure data integrity and transactional consistency.
- “Latches” are low-level synchronization primitives used to protect access to internal DB structures.
HN user^
FAQ
Exclusive vs Shared Locks?
- This is general terms, with something like PostgreSQL, we need to be more specific about which lock exactly are we talking about
- Usually
Exclusivewill mean you lock both R&W- NOTE: PostgreSQL does have an actual table lock named “EXCLUSIVE” but it’s refering to that specific lock and not to this generalized definition of
Exclusivelock. Same goes forSHARE.
- NOTE: PostgreSQL does have an actual table lock named “EXCLUSIVE” but it’s refering to that specific lock and not to this generalized definition of
- Usually
Sharedwould mean only W is locked, read can be done by other transactions etc
Preventing Conflicts
- Locks alone are not sufficient to prevent conflicts
- A concurrency control strategy must define how locks are being acquired and released
- As this also has an impact on transaction interleaving. (See Non-realtime interleaved execution model)
Types of Concurrency control
Different DBs have differnt names and implementations, this is just generalization.
See https://www.vldb.org/pvldb/vol8/p209-yu.pdf


Exclusive Locks

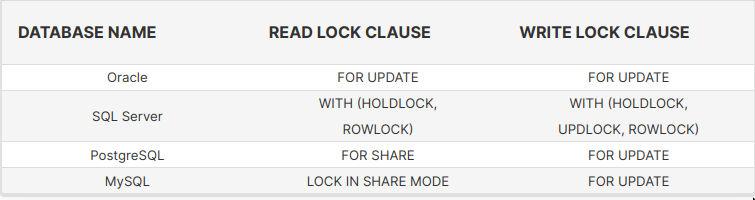
Read lock
- Prevents a resource from being written while allowing other concurrent reads.
Write lock
Blocks both Readers and Writers concurring for the same lock
Pessimistic locking (Avoid Conflicts)
Sidenote: RWMutex and Two Phase Locking (2PL) are similar, one is more used application development and the latter one more in database transaction safety etc.
RWMutex, Two Phase Locking (2PL) etc.- Atomics don’t scale either
- Such shared locking help, but they do not scale. In order to scale RWMutex,
- Time spent by readers while holding the mutex should be significant
- Otherwise, overhead of synchronizing between multiple readers becomes dominant, and the system won’t scale well. Because the synchronization itself is a write operation on the mutex’s internal data.
- See Amdahl’s law - Wikipedia, How to Quantify Scalability
Optimistic locking mechanism (Allow conflicts, better scalability, Time based)
- Allow conflicts to occur, but you need to detect them. Reader starts reading an object w/o any synchronization (optimistically hoping for success), and when it finishes it verifies that the object was not changed under its feet.
Logical clocks
- See Clocks
State distribution
- State distribution
- Also see Data Replication
MVCC
- See MVCC
- NOTE: There are some variants of MVCC which use Pessimistic locking. (Eg. MV2PL)
Other locks
Predicate locks
Range locks
Lock levels
- Serialized Database Access
- Making the database run queries one by one
- Terrible concurrency
- Highest level of consistency
- Table Lock
- Lock the table for your transaction with slightly better concurrency, but concurrent table writes are still slowed.
- Row Lock
- Locks the row you are working on even better than table locks, but if multiple transactions need this row, they will need to wait.
- Row-level read and write locks are recorded directly in the locked rows and can be inspected using the pgrowlocks extension.
- Range locks
- Between the last two levels of locks(Table and Row); they lock the range of values captured by the transaction and don’t allow inserts or updates within the range captured by the transaction.
Postgres Lock Modes
What are lock modes?
Specific to pg
When MVCC does not suffice, application devs can use these lock modes. They’re defined by which other lock modes they
conflictwith, which in-turn are used by differentcommands. Difference between one lock mode and another is: the set of lock modes with which each conflicts/compatible with.
- Lock modes are either
Table LevelorRow Level - Most PostgreSQL commands automatically acquire locks of appropriate modes to carry out things. Otherwise dev can use
LOCK(table only).TRUNCATEobtains anACCESS EXCLUSIVElock to carry out its actions.SELECTacquiresACCESS SHARElock modeUPDATE, DELETE, INSERTacquireROW EXCLUSIVElock modeCREATE INDEXacquiresSHARElock
Lock vs Lock Mode in Postgres
If we say “Transaction A holds an EXCLUSIVE lock on Table T”, we mean:
- There is an actual lock (mechanism) on Table T
- This lock is operating in
EXCLUSIVE mode(behavior)
Postgres Lock modes
How to take locks?
devs can acquire the advisory locks and as-well as the normal pg specific locks using the LOCK command. But the pg specific locks can be otherwise used implicitly via the “lock modes”. PG already takes implicit locks for its operations, we can tap into them by using the lock modes
-
Table level
LOCKstatement can be used to acquire ONLYtabel-levellock mode on-demand (this is usually not needed)
-
Row level
SELECT ... FOR UPDATEis the primary way to “explicitly” acquire arow-levellock. The other transaction will just wait till tx gets over.SELECT ... FOR UPDATE NOWAITsimilar toFOR UPDATE, but doesn’t wait, instead raises an errorSELECT ... FOR UPDATE SKIP LOCKEDskips any rows that are already locked by other transactions.
- Pure
SELECTstatements do not block reads, but another concurrentSELECT... FOR UPDATEoperation will block until the firstSELECT... FOR UPDATEtransaction completes. NOWAITonly works forSELECTstatement, if we wantNOWAITbehavior onUPDATE(which by default will just wait) then we’ll have to run a SELECT before UPDATE.WITH locked_workflow AS ( SELECT * FROM workflow_run WHERE workflow_run.id = $1 FOR UPDATE NOWAIT ) UPDATE workflow_run SET status = $2 WHERE workflow_run.id = $1 AND EXISTS (SELECT 1 FROM locked_workflow); -- this is just so that CTE is evaluated
Catalog
https://pglocks.org/ https://leontrolski.github.io/pglockpy.html
-
Table Lock modes (8)
NOTE: Some locks have “row” in the name but they still mean table level locks
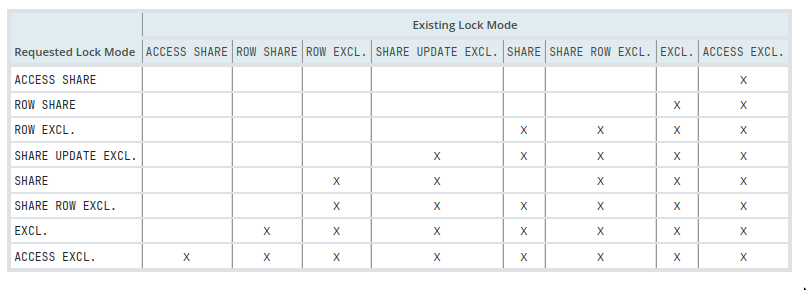
- Once acquired, a lock is normally held until the end of the transaction.
- If a lock is acquired after establishing a savepoint, the lock is released immediately if the savepoint is rolled back to.
-
Row Locks modes (4)
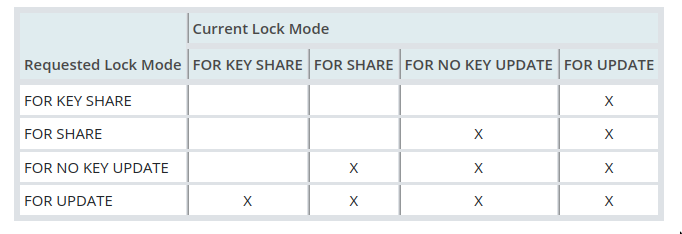
- These too like table level locks are used automatically by postgres when required by different commands
- The same transaction can hold conflicting locks
- on the same row
- on the same row, even in different subtransactions
- 2 different transactions can never hold conflicting locks on the same row.
- Release is similar to table lock release
TODO Advisory locks
Advisory locks are application-defined locks that are not tied to a particular database object (like a table or row). Instead, they are associated with arbitrary integers defined by the application. They allow you to implement locking schemes at the application level that are managed by the database.
- Locks that applications can use
- Eg. emulate pessimistic locking strategies typical of so-called “flat file” data management systems.
- While a flag stored in a table could be used for the same purpose, advisory locks are faster, avoid table bloat
- Automatically cleaned up by the server at the end of the session
- Acquire
- Session level
- Held until explicitly released or the session ends
- TODO Unlike standard lock requests, session-level advisory lock requests do not honor transaction semantics: a lock acquired during a transaction that is later rolled back will still be held following the rollback, and likewise an unlock is effective even if the calling transaction fails later. A lock can be acquired multiple times by its owning process; for each completed lock request there must be a corresponding unlock request before the lock is actually released.
- Transaction level
- Session level