tags : SQL, Distributed Systems, PostgreSQL, Database Transactions
Database types

Based on Relational(SQL) v/s Non-relational(NoSQL)
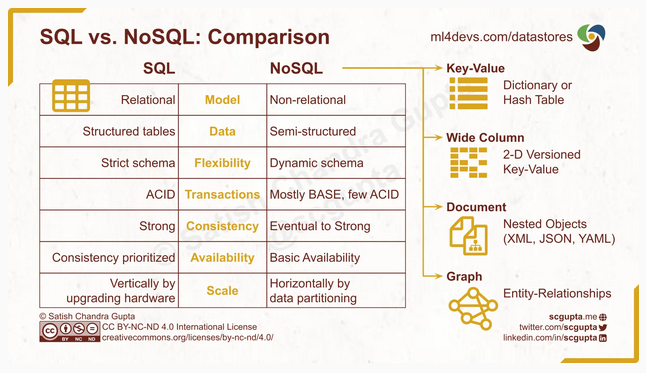
- SQL: Usually columnar storage or row storage
- NoSQL: Usually K/V, Wide Column, Document, Graph etc.
- Wide-column and columnar storage are totally different!!
Relational
- Schema
- PostgreSQL, MySQL etc
Non-Relational / NoSQL
- Access paths
- Relational model allows you to do “point” queries. i.e you can get “any” or “all” of something. Eg. any or all comments, any or all users.
- w Non-relational(usually tree), you need to worry about access path.
- Find any comment? you need to know what post it is attached to.
- Find all comments? you have to traverse all posts to all comments.
- If path changes, you have to go update application logic
- Start node
- Finding start nodes is what SQL explicitly excels at.
- Once we do have a start node (a comment, post, user, etc.), a Graph query language is a better fit for application queries than SQL.
Few words by tantaman^
- Schemaless
- This should have been named NoRDBMS instead because it’s not no sql that is. Infact, no-sql dbs can support sql like queries etc.
Based on CAP
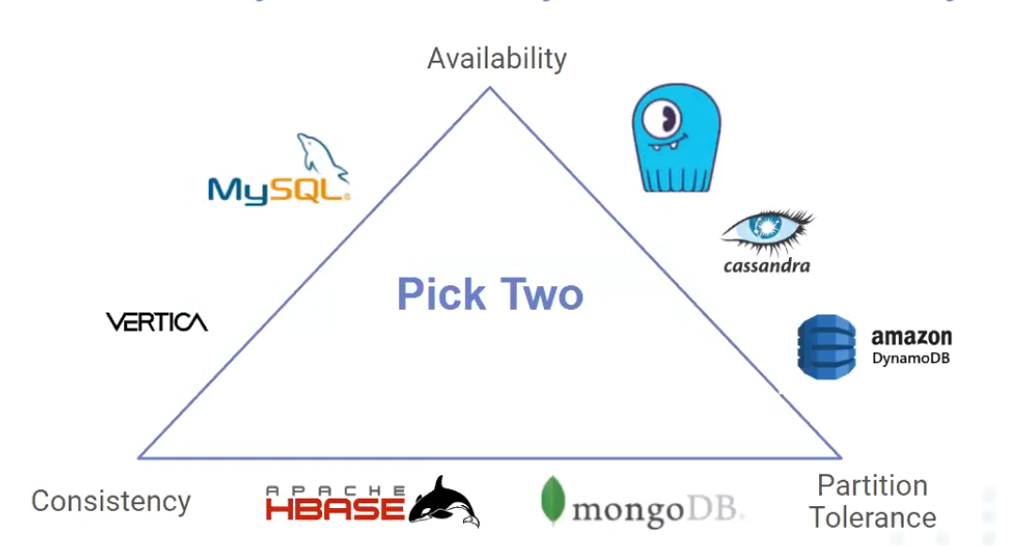
- While most Relational DBs guarantee ACID, NoSQL DBs give you BASE
- There are distributed SQL database aswell: Eg. CockroachDB, Yugabyte etc. which try to give you ACID guarantees while being distributed. (hard problem)
Based on Data model
These data models can be implemented in both Relational and Non-Relational types. Eg. PostgreSQL can also be turned into column store/json data store with indexes and extensions etc. But database built for specific data models would most probably be the ideal solution rather than make up for it w extensions etc.
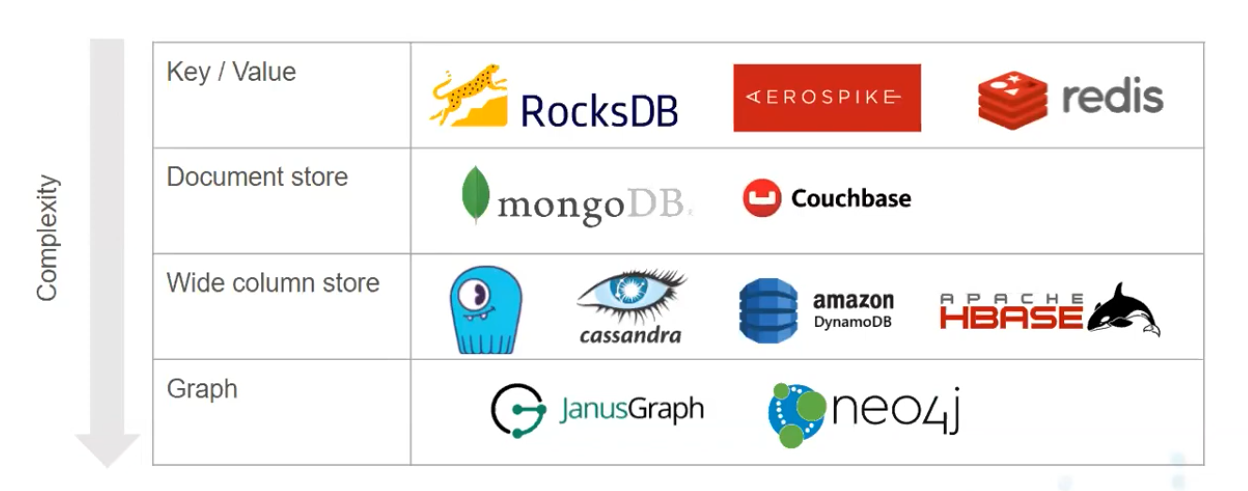
- NOTE: This picture is missing “column oriented” databases
- “wide column” != column oriented.
Eg. KV, Graph, Document/Object, Column-family(wide column), Columnar, Row oriented, Array/Matrix/Vectors etc.
KV
- Redis, DynamoDB etc.
- See LSMT in Trees
Document/Object based
- MongoDB, DocumentDB etc.
Row store oriented
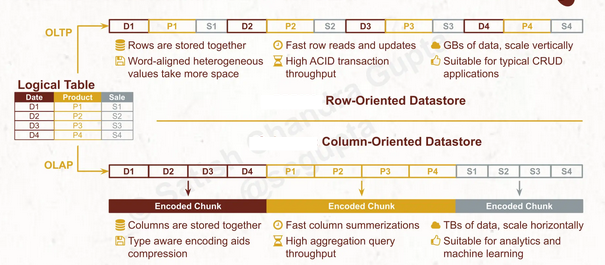

Column store oriented
- Usually Column store database are used in OLAP systems
- aka Columnar Storage
- AWS Redshift, DuckDB, Clickhouse(SQL OLAP DB)
- Data Warehouse are usually built on columnar storage, See Data Engineering
Wide Column
Naming confusion
- Wide column != column store oriented db!
- Most (if not all) Wide-column stores are indeed
row-oriented stores! : parts of a record are stored together.- The name “is” confusing, even though it has “column” it the name it does not really store the data in columnar format like real “columnar stores”. It uses the concept of column family.
- nosql - What difference between columnar and wide column databases? - Database Administrators Stack Exchange
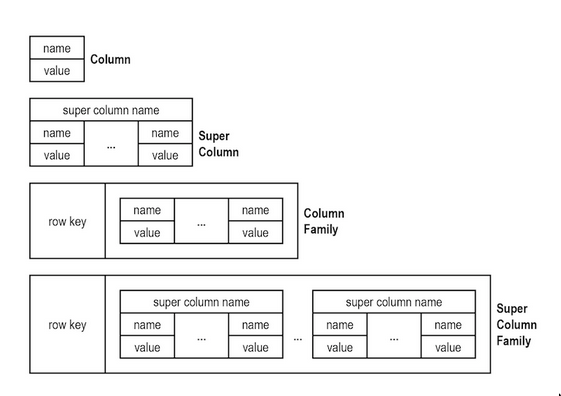
- Wide column data model is usually used in NoSQL databases.
- Wide column:
(Partition Key, Cluster Key, Value) - Example: ScyllaDB, Cassandra, Hbase
Based on Query
- Both SQL and NoSQL database can be either OLAP/OLTP or both based on what the database has to offer
- As mentioned previously:
- SQL: Usually columnar storage or row storage
- NoSQL: Usually K/V, Wide Column, Document, Graph etc.
- Wide-column and columnar storage are totally different!!
Differences
- For example Scylladb(OLTP) unable to run
select sum() from multibillion_table group by millions_key- And vice versa CH(OLAP) is super slow on
select value from multibillion_table where key=
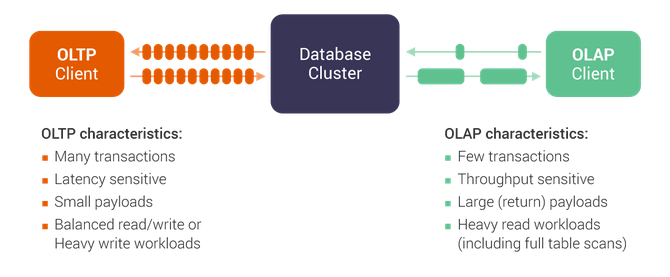
OLAP
- Analytics workload
- Clickhouse, Snowflake, DuckDB, Apache Druid
OLTP
- Transactional workload
- PostgreSQL(SQL, row-based), SyllaDB(NoSQL)
Operational
- “automated interventions in the business”
- Think of OLTP workload on a OLAP database
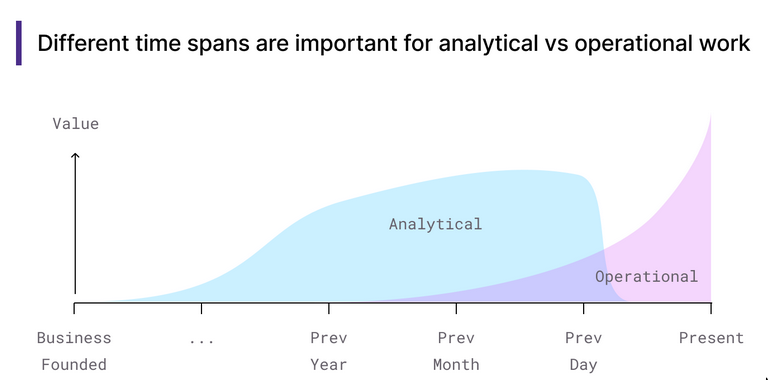


- Operational is slightly different from transactional&analytical, somewhere in the middle
- Usually involves maintenance workloads etc. Sometimes queries need to run on big datasets.
- Operational workloads have fundamental requirements that are diametrically opposite from the requirements for analytical systems
- If an operational system goes down for the day, there are people who will either be unable to do their job
- Similarities with Analytics workload is that both sort of will share SQL queries that are complex, join-heavy, multi-level.
- Solutions
- Reverse ETL (See Data Engineering) for this purpose
- Cache results (but now need to worry about cache invalidation)
Time Series DB
- Ask HN: State of Timeseries Databases in 2024 | Hacker News
- Timeseries Indexing at Scale - Artem Krylysov
Relational Model basics
Meta
- Access path independence: Decouple “what data do I want to retrieve” from “how do I retrieve it.”
Components
- tables = relations
- Unordered set that contain the relationship of attributes that represent entities.
- Table w
n-ary relation= Table w n columns
- attributes = columns (has a type/domain)
- tuple = row = set of attributes/columns
- Values
- Normally atomic/scalar
NULLis a member of every domain if allowed
Modeling of Databases
See DB Data Modeling
Partitioning
- See Scaling Databases
- A rather general concept and can be applied in many contexts.
- Partitioning could be
- Different database inside MySQL on the same server
- Different tables
- Different column value in a singular table
Horizontal/Row based
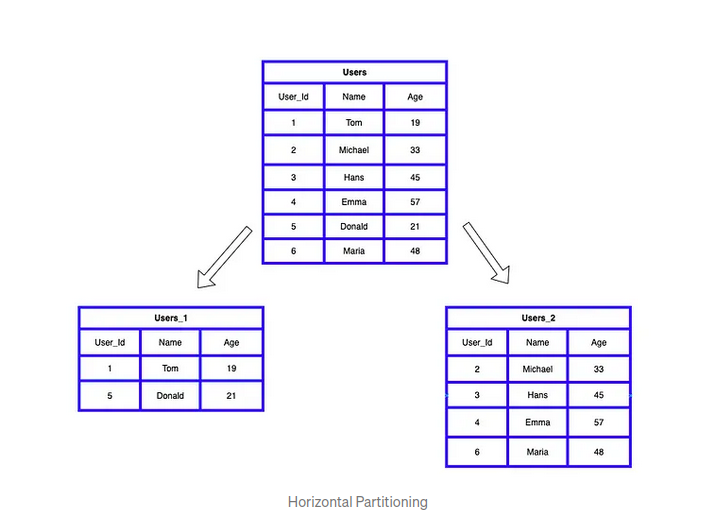
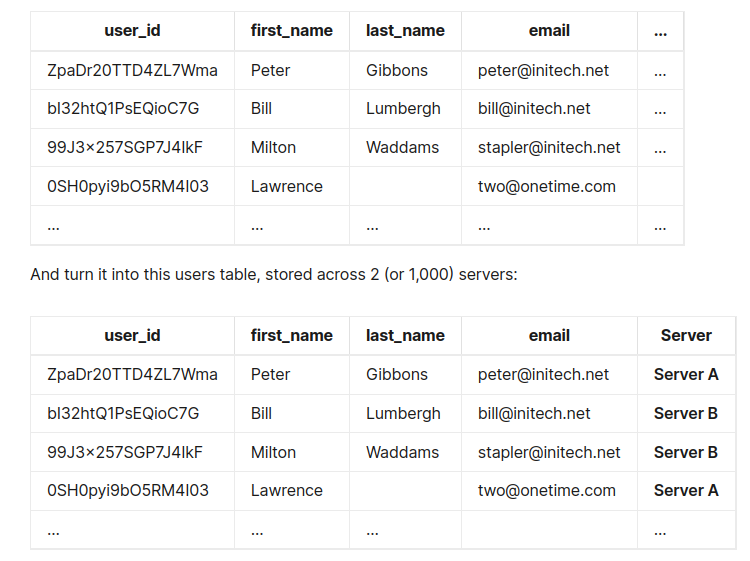
- Splitting one table into different tables. Same table structure.
Vertical/Column based
- Splitting one table into different tables. Each table will have a different table structure.
- This is similar to the idea of Normalization
- Usually vertical partitioning refers to a physical optimization
- Whereas normalization is an optimization on the conceptual level
Important Features
Caching
External
- External Materialized views
- Query caching
- See ReadySet | Same database, (much) faster queries
- Redis should also be able to do this?
Migrations
- There are different migration patterns
- Tools
Migration FAQ
-
Migration version issue
- Sequential versions vs Timestamps
- 0005_first_developer_account_changes.sql vs 2017…08_first_developer_account_changes.sql
- See this thread for proper explanation
- Solution is to use a hybrid approach.
- If using goose, it has the fix command which is suggested to be run in CI. Goose will also create a table
goose_db_versionin the same postgres schema. Timestamps- in Local/Dev
- Avoid annoying file renaming & conflicts on rebase
Sequential- in staging/prod
- Rename those timestamps-based filenames to serial numbers
- If using goose, it has the fix command which is suggested to be run in CI. Goose will also create a table
- Sequential versions vs Timestamps
-
Online/Live/Realtime Migrations
- Migrating from one database to another without downtime and compromising data correctness
Tips
-
No direct table access
Never expose real tables to an application. Create an “API” schema which contains only views, functions, procedures, and only allow applications to use this schema. This gives you a layer of indirection on the DB side such that you can nearly eliminate the dance of coordinating application changes and database migrations
-
Get comfortable with
forward-only migrationsRollbacks work fine for easy changes, but you can’t rollback the hard ones (like deleting a field), and you’re better off getting comfortable with
forward-only migrations
-
Application code and Migrations
- Usually recommended to decouple schema rollout from the application
- Whether you can run migrations before application startup is something to be decided based on provisioned infra. Eg. in k8s, some ppl run migrations in init containers, don’t do rollbacks.
- It isn’t possible to atomically deploy both the migration and the application code that uses it.
- This means if you want to avoid a few seconds/minutes of errors
- You need to deploy the migration first in a way that doesn’t break existing code
- Then the application change
- And then often a cleanup step to complete the migration in a way that won’t break.
Cursors
Functions
Triggers
Stored Procedures
Deferred Constraints
Application code constraints
Query Planner
- Also see Query Engines. The term query planner and query optimizer is synonymous.
- There can be muliple ways a result of a DB query can be found. Query planner’s role is to determine which strategy is the best option.
- Eg. choosing which indexes to scan for a given query,
- Eg. choosing the order in which to perform joins, and
- Eg. choosing the join algorithm to use for any given join
- It analyzes the queries + optimize them before running.
- Some query planner offer escape hatches for end user to fiddle with
- The life of a query begins and ends in the database itself.
Component of Query Planner
These are not actual component names but abstract ideas for understanding.
-
Compiler
- A query will be lexed, parsed, typechecked, translated into an intermediate representation, “optimized”
- Finally directly translated into a form more suitable for execution.
-
Domain knowledge extractor
- Approximate domain knowledge that it can exploit to make queries run as fast as possible.
- This is done through making approximations on
statisticscollected. Eg. In the following query this needs human intervention, but query planner will try its best to detect which way to go with from thestatistics(how big is each table, how many distinct values does each column contain, etc).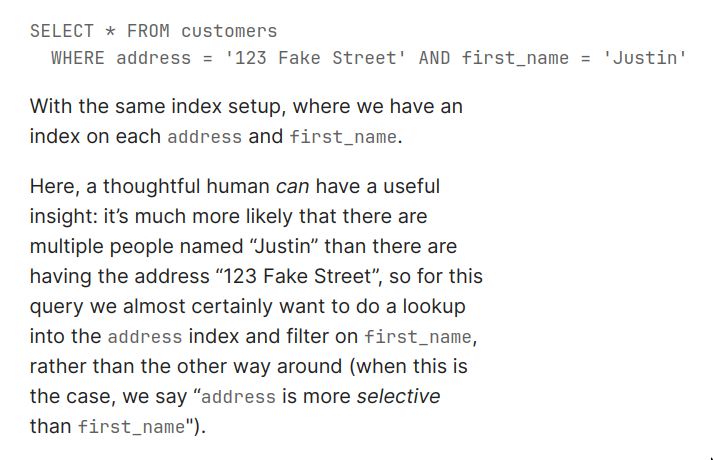
TODO Plans
-
Postgres Specific
- General plan
- Custom plan
-
Physical Plan
- The plan that gets executed
Others
- Locks: See Database Locks
- Vacuum: See PostgreSQL
- Indexes: See Database Indexing
ACID
- ACID are correctness criteria properties of database transactions
- See Database Transactions
What are these?
- Loose description instead of a strict implementation standard.
- Properties database transactions need to guarantee to their users for validity even in the event of crash, error, hardware failures and similar.
- These guide application developers what’s their responsibility v/s what the databases provides
ACID can have multiple meanings
- There are tradeoffs in implementing ACID capabilities/properties. So, if a DB claims to be ACID complaint, there might still be edge cases
- Each property has its own spectrum, the spectrum is of about trafeoffs. So implementation of the property will fall somewhere in the spectrum based on the tradeoffs the DB developers took
- Implementing some capabilities is more expensive than others.
consistencyandisolationare pretty expensive.
The properties
Atomicity
- Database ordering of transaction if different from what application dev sees in their code. If you want it two transactions to maintain order, better wrap them in a database transaction.
ROLLBACKhelps with atomicity
Consistency
Atomicity+Isolationleads to consistency- Consistency has different meanings based on context. (See Concurrency Consistency Models)
- When it comes to ACID in databases, it simply means satisfying application specific constraints. Think of maintaining referential integrity etc.
Isolation
- Question to ask: “Is it serializable?”
- Question to ask: “Whether or not concurrent transactions can see/affect each other’s changes”
- Helps avoid race conditions
- Isolation is achieved using Database Transactions
-
Weak and Strong
- Weak isolation = faster + more data races
- Weak doesn’t mean unsafe
- Strong isolation = slower + lesser data races
- Eg. Cockroach and SQLite have effectively serializable transactions. But they don’t catch all bugs either.
- Weak isolation = faster + more data races
-
Read Phenomena/Issues/Anomaly
NOTE: See PostgreSQL: Documentation: 16: 13.2. Transaction Isolation for better summary
-
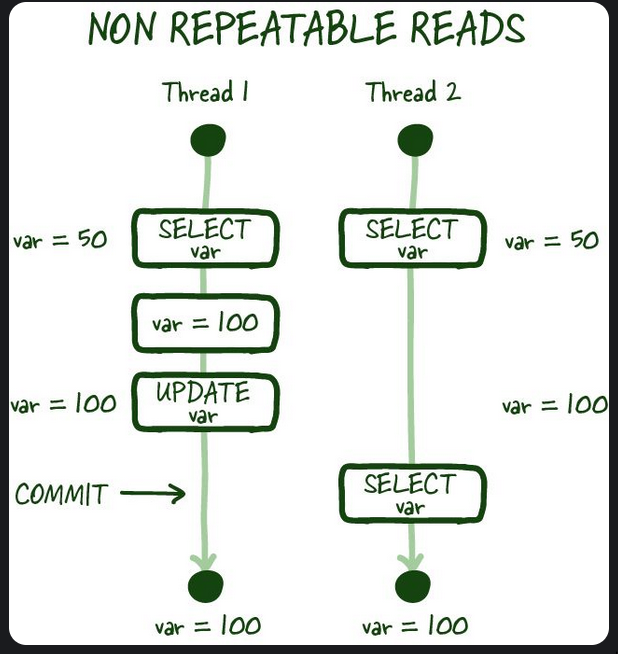
Non-repetable reads
In the same thread, you read the same data twice and you now get different value because another thread committed. That’s non-repetable! i.e you’re not getting consistent results
-
Dirty reads
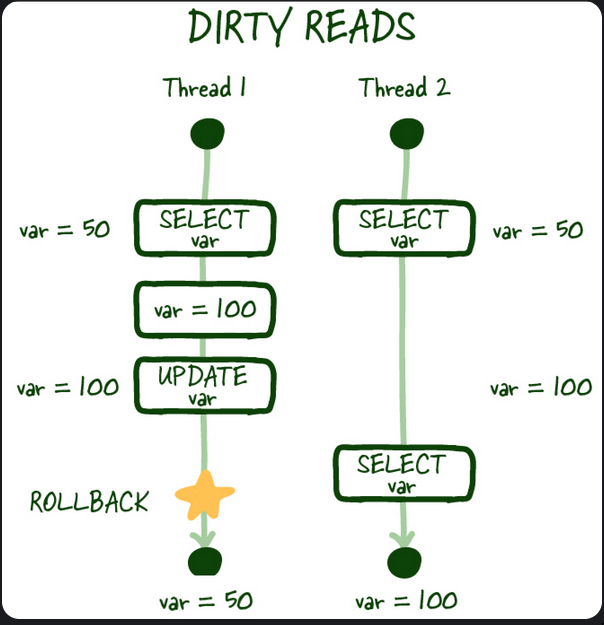 In the same thread, you read the data, but another thread also changed the same data but did not even commit. You read the data again, you’re seeing uncommitted data now in your thread.
In the same thread, you read the data, but another thread also changed the same data but did not even commit. You read the data again, you’re seeing uncommitted data now in your thread.
-
Phantom reads
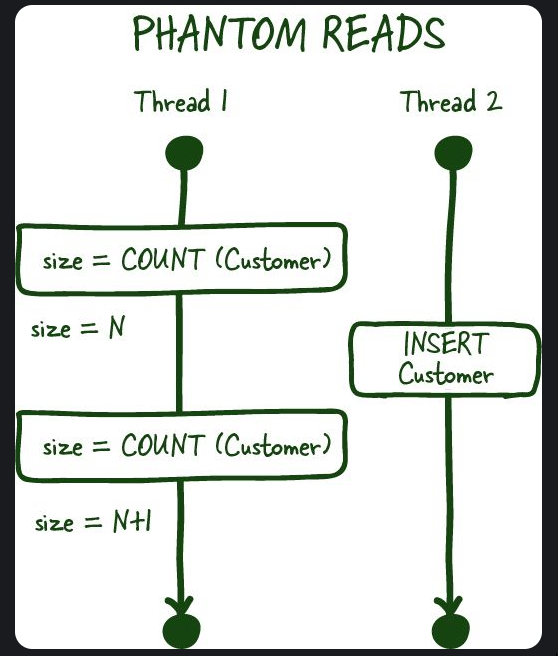
- This is similar to Non-repeatable reads but more related to search conditions/aggregates finding that previous results of the search/aggregations and current results are different
-
-
SQL standard isolation levels
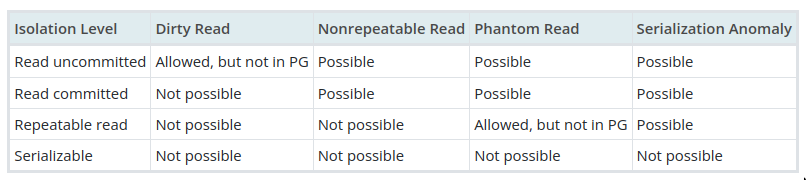 There are more levels to this than what the SQL standard offers. Eg. Google’s Spanner guarantee external serializability with clock synchronization (stricter isolation but not in the SQL standard, see Concurrency Consistency Models)
There are more levels to this than what the SQL standard offers. Eg. Google’s Spanner guarantee external serializability with clock synchronization (stricter isolation but not in the SQL standard, see Concurrency Consistency Models)Name Description Strength(1-4) Availability Serializable As if execution was sequential 4 Unavailable Repeatable reads Changes by other transactions aren’t visible, but can see own uncommitted reads. 3 Unavailable Read committed Only committed changes are visible, no uncommitted reads. New committed changes by others can be seen (potential for phantom reads).2 Totally Available Read Un-committed Allows dirty reads, transactions can see changes by others that aren’t yet committed. 1 Totally Available - The isolation levels only define what must not happen. Not what must happen. (i.e
BTNH, See Correctness criteria) Read commitedis the default in PostgreSQL but allows no phantom reads.- Most DBs don’t even implement
Read Un-committedas it’s not much useful
- The isolation levels only define what must not happen. Not what must happen. (i.e
-
Databases and their implementation of isolation
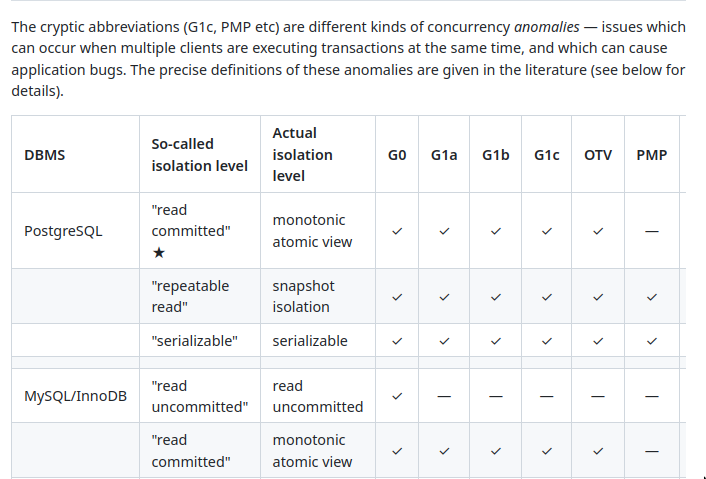
- Martin Kleppmann’s Hermitage is an excellent resource on this.
- DBs provide different isolation layers based on tradeoffs, SQL standard has 4. Eg. PostgreSQL only provides 3.
- DBs say something and mean something else from Concurrency Consistency Models
- See ept/hermitage
Durability
- This is about what happens after
COMMIT - When i hit save, things should go to non-volatile shit, so that if system crashes, i can still read the data
- Some sacrifice durability for performance.
- This is again different for different DBs, eg. SQLite only acknowledges a transaction when it is safely persisted to the underlying storage.
Database Administration
See Infrastructure, System Design
Sessions, Connections and Transactions
Read this: How to calculate max_connections for PostgreSQL and default_pool_size for pgbouncer?
Connection
| DB | Default connection limit |
|---|---|
| sqLite | N/A, limited by single-writer |
| poStgresql | 100 (configurable) |
| mySql | 150 (configurable) |
- A Connection is established when a client (like an application or a user) connects to the PostgreSQL server.
- Each connection runs in its own process in the server.
- Idle connections consume resources. pgbouncer has
server_idle_timeouton which it’ll close a connection to the db if it has been idle for more than the specified duration. - In terms of PostgreSQL, each connection is then handled by a
worker backend - “To get more storage, you buy SSD, and to get more connections, you buy more RAM & networking hardware”
Session
- A Session begins when a connection is successfully established.
- In PostgreSQL, a session is essentially synonymous with a connection.
- PostgreSQL can handle multiple connection/sessions concurrently
Transaction
- Transaction is a sequence of one or more SQL operations treated as a unit.
- A session can have muliple transactions
- All
queryrun within a transaction - Life cycle: starts, runs the queries it contains, and ends
Pools
- See How to Manage Connections Efficiently in Postgres, or Any Database
- See Scaling PostgreSQL with PgBouncer: You May Need a Connection Pooler
- The fundamental idea behind PgBouncer is to reduce the overhead associated with opening and closing connections frequently by reusing them.
- Usually
sessionandconnectionhave 1-1 relationship, pools change that. - Check
- Free connection is available: Assigns connection to the client.
- No free connection, pool not at max: Opens new connection, assign client.
- Pool at max: Queue client request
-
pgbouncer
Since pgbouncer is single threaded, you can run multiple of it like this
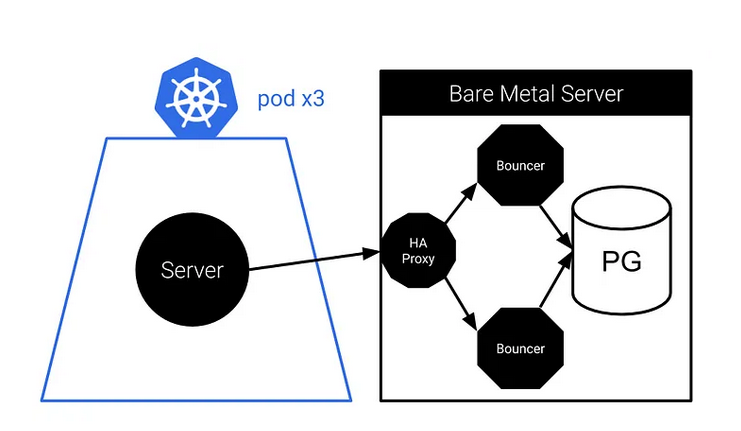
-
Pooling types
However session pooling is only useful for limited use cases such as maintaining a long-lived connection for short-lived clients. In most cases, people use transaction pooling to handle more connection than postgres would allow.
-
Session pooling
- Pgbouncer merely acts as a connection broker
- We still get the 1-1 connection-session relationship with added queue
-
Transaction pooling
- Can assign the
connectionto different client- Once the current transaction is completed
- Session might not be complete
- i.e same connection be used for multiple sessions
- i.e connections can be shared among different sessions
- Limitations when working with Prepared Statements.
- We must make sure that, we do not depend on session-level states (like temporary tables, session variables)
- Can assign the
-
-
Configuring pgbouncer
-
Auth (2 ways)
I prefer the
auth_querymethod. But even when usingauth_querymethod, we’ll still need to useauth_file(userlist.txt) forauth_userpass. (yeah it’s damn confusing)- Adding the SCRAM verifiers to the
userlist.txtfile that the pgbouncer.ini references - Setting up an
auth_queryto be used by the pgbouncer.ini method
- Adding the SCRAM verifiers to the
-
-
Helpful check (from twt)
A quick check to know if you’d benefit from pgbouncer, run this query:
SELECT count(*), state FROM pg_stat_activity GROUP BY 2;If you’re idle account is high (yes this is dependent on your view, but to me if it’s above 25-30 range, and especially if active is until half that) then you’d already start to benefit from pgbouncer. If it’s at 10,000 then post haste get pgbouncer in place.
-
Edge and Databases
- Usually edge environments don’t support making arbitrary TCP outbound connections
- Only HTTP and WebSockets are allowed.
- DBs usually use a custom TCP-based network protocol. (now that’s a conflict)
- You will need to use a HTTP -> TCP proxy of some sort
- Some edge ready DBs are now supporting
- HTTP fetch (best for single-shot queries)
- WebSocket (for sessions and transactions)
Management Processes
See PostgreSQL
ORMs
They are simply an abstraction with a quintessential pro and con—they abstract away some visibility and occasionally incur some performance hits.
- Produce
- ORM: Produce objects. (directed graph)
- DB tables: Bidirectionally linked data via shared keys (undirected graph)
- See Sketch of a Post-ORM
Notes on various database software out there
LevelDB
- Uses LSMT (See Trees)
- Progression:
BigTable > LevelDB - Embedded key-value store, (library in an application)
- I/O
- Heavy write throughput workloads
- NOT great at random reads
- Designed for disk
- Merges using bulk reads and writes: they minimize expensive seeks
- LevelDB Explained - How to Analyze the Time Complexity of SkipLists?
RocksDB
- RocksDB is a fork of LevelDB started at Facebook
- Designed for SSD and RAM
- Comparison to LevelDB: Tunable trade-offs for reading/writing and space usage.
- RocksDB: Not A Good Choice for a High-Performance Streaming Platform | Feldera
Cloudflare D1
Journey to Optimize Cloudflare D1 Database Queries | Hacker News