tags : Information Theory, NLP (Natural Language Processing), Machine Learning, Embeddings
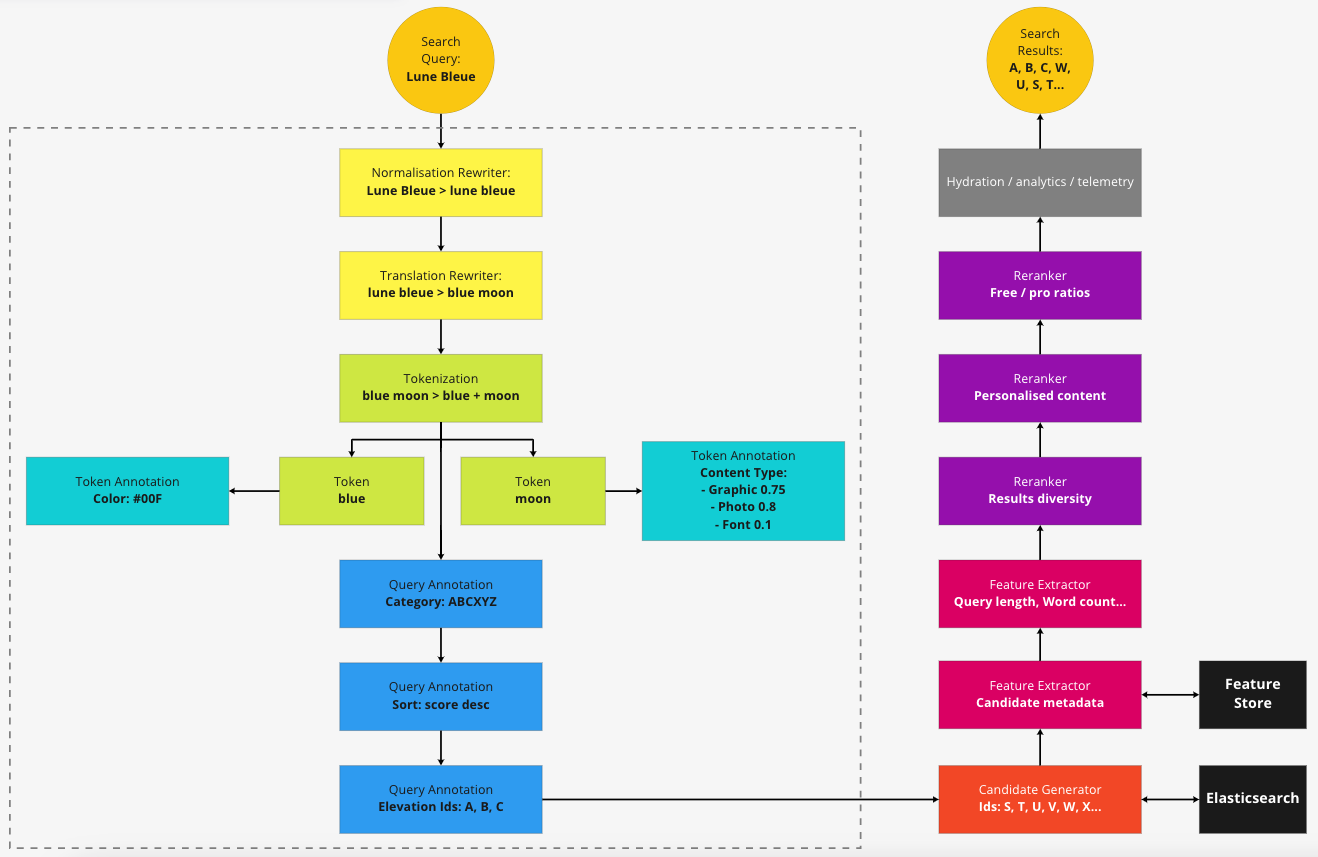 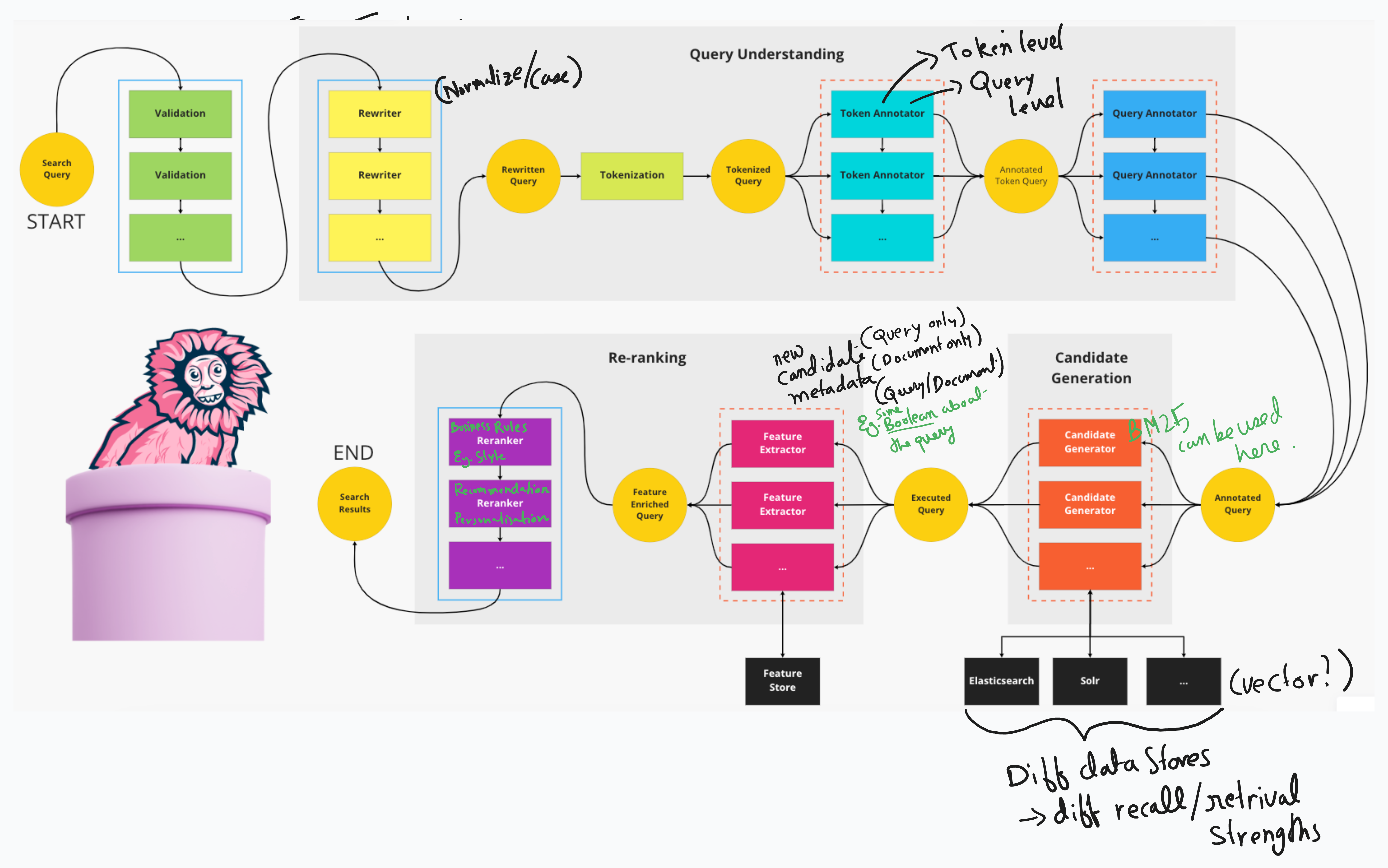

- See GitHub - kuutsav/information-retrieval: Neural information retrieval / semantic-search / Bi-Encoders
Theory
General idea
- IR is about scale, you have a huge data you should be able to get things out.
- There have been traditional methods used but more recently people have also use BERT, Embeddings, even LLMs to do IR tasks.
- The use of IR can be task specific
- For search, you might just want a limited retrival where you return n ranked reponses
- For something like fact checking, you’d want it to get everything, run analysis and get back with the result
Forward Index
- Eg. Doc123 => “the”,“apple”,“in”,“tree”
- Keywords can be marked more or less relevant etc
- Problems: capitalization, phases, alternate spellings, other stuff.
- Inverted index can be generated out of it
Ranking
TF-IDF (Term Freq. and Inverse Doc. Freq)
- Not used too much these days but old OG
-
Formula
- Term Freq: How often word appears in doc
- Doc Freq: How often word occurs in ALL set of documents. (Tells us that “is” is pretty common)
- Relevancy =
- i.e Term Freq * 1/Doc Freq
- i.e Term Freq * Inverse Doc Freq
- i.e TF-IDF
Page Rank
- Again not used a lot anymore but the algorithm was similar to TF-IDF but includes backlinks and a damping factor into the eqn.
Recommendation Engines
Search Engines
You can decompose a “search engine” into multiple big components: Gather, Search Index, Ranking, Query
Gather
Search Index
- Database cache of web content
- aka building the “search index”
- See Database, NLP (Natural Language Processing)
Ranking
- Algorithm of scoring/weighing/ranking of pages
Query engine
- Translating user inputs into returning the most “relevant” pages
- See Query Engines
Semantic Search Resources
- See Embeddings
- Spotify-Inspired: Elevating Meilisearch with Hybrid Search and Rust
- https://github.com/josephrmartinez/recipe-dataset/blob/main/tutorial.md
TODO Full Text Search (FTS)
Postgres
- You would have to build two different indexes, one with pg_trgm and one with tsvector. Alternatively you could use the partial match feature of FTS, with :*, but that doesn’t play well with stemming or with synonyms.
Meilisearch
Debugging
Ideally when run in development env, we should have the meilisearch UI running at MEILI_HTTP_ADDR but I am not sure why it’s not exposed. As a workaround for manual debugging/checks etc. We can use this: https://github.com/riccox/meilisearch-ui
Resources
- Build a search engine, not a vector DB | Hacker News
- Meilisearch Expands Search Power with Arroy’s Filtered Disk ANN
- Supercharge vector search with ColBERT rerank in PostgreSQL | Hacker News
- How do we evaluate vector-based code retrieval? – Voyage AI 🌟
- Hard problems that reduce to document ranking | Hacker News
- Improving recommendation systems and search in the age of LLMs | Hacker News