tags
: Storage, Scraping, peer-to-peer
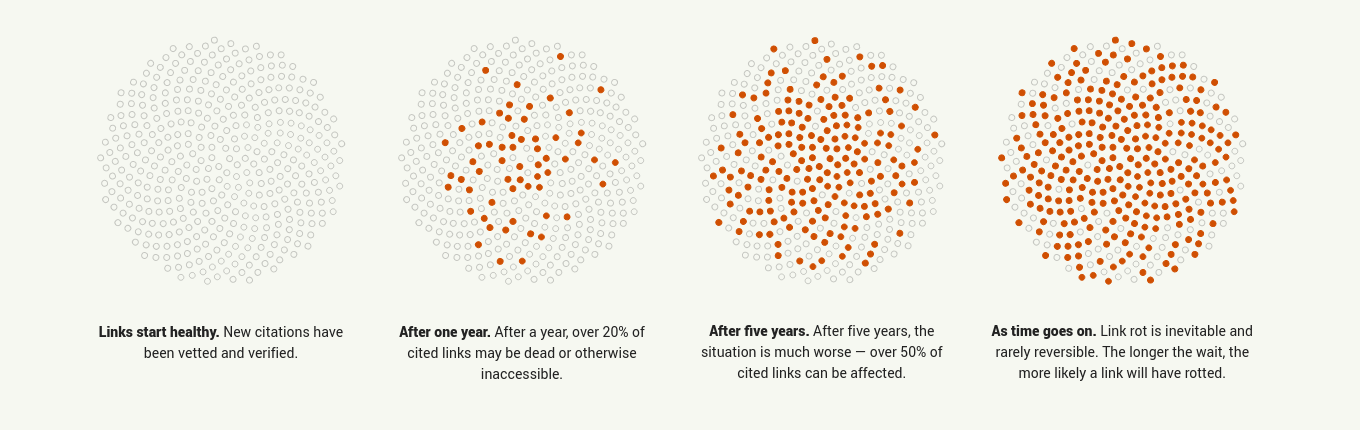
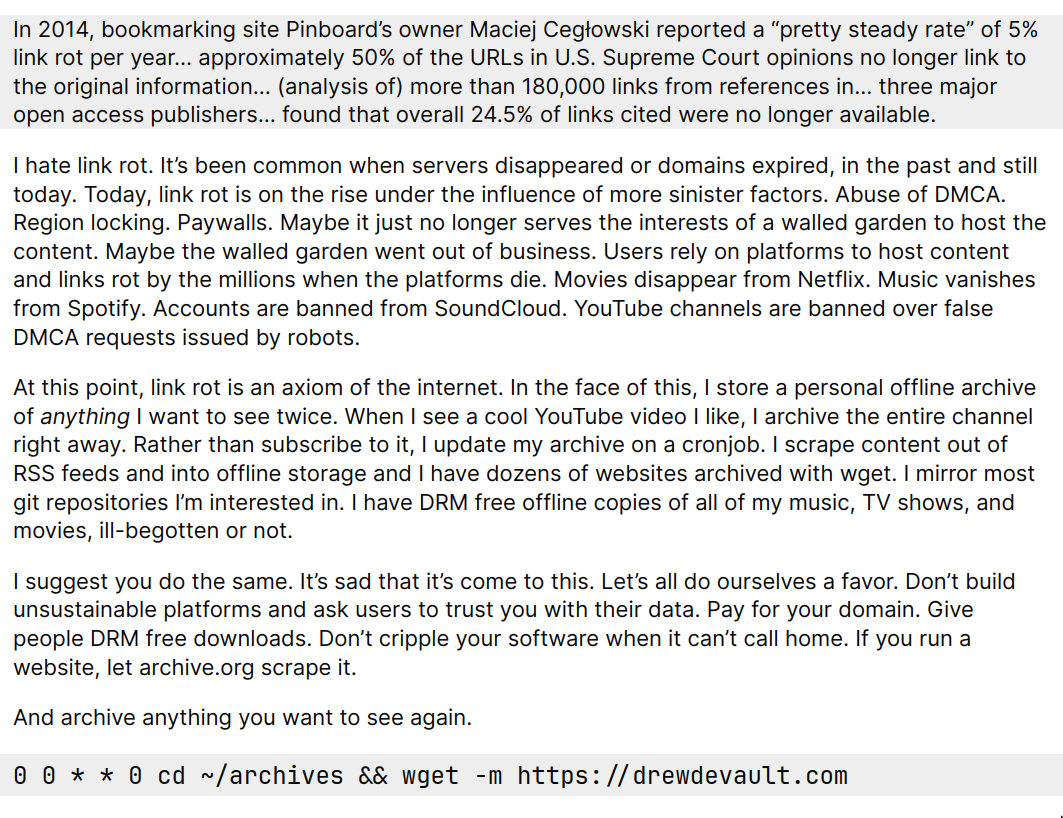
Web Archiving Workflows and Best Practices §
Institutional Archiving §
Large institutions typically employ a workflow that involves:
- Selection - Identifying content to preserve
- Acquisition - Using crawlers like Heritrix to collect content
- Storage - Preserving WARC files with redundancy
- Access - Providing replay through Wayback Machine-like interfaces
- Preservation - Ensuring long-term accessibility through format migration
Personal Archiving §
Individual users have different needs:
- On-the-fly capture - Browser extensions like ArchiveWeb.page or SingleFile
- Local storage - Managing personal collections with tools like ReplayWeb.page
- Format considerations - Balancing completeness vs. convenience
- Sharing capabilities - Using portable formats like WACZ
Quality Assurance in Web Archiving §
Critical considerations for effective archiving:
- Completeness - Capturing all required resources
- Fidelity - How closely the archive resembles the original
- Replayability - Whether interactive elements function
- Longevity - Format sustainability and migration paths
Usecases §
| Category | Tool | Description |
|---|
| Website Downloaders | wget, httrack | Standard tools for downloading entire sites (see offlinesavesite alias) |
| Skallwar/suckit | Alternative to httrack |
| Y2Z/monolith | Downloads assets as data URLs into single HTML file |
| WebMemex/freeze-dry | Library (not tool) for freezing web pages; has useful “how it works” page |
| gildas-lormeau/SingleFile | Decent browser extension/CLI for saving web pages |
| Offline Browsing | dosyago/DownloadNet | Site downloading focused on offline browsing |
Other Archiving Solutions §
Major Digital Archives §
| Organization | Founded | Description |
|---|
| Internet Archive | 2001 | American digital library with the stated mission of “universal access to all knowledge.” |
| Archive Team | 2012 (archive.is) | A loose collective of rogue archivists, programmers, writers and loudmouths dedicated to saving our digital heritage. |
| Sci-Hub | - | Research paper repository providing free access to paywalled academic papers. |
| Z-Library | - | Book repository, initially a clone of LibGen with more accessible UX and monetization. |
| Anna’s Archive | - | Open-source data library related to Z-Library. |
Regional Archives §
| Name | Website | Description |
|---|
| Perma.cc | perma.cc | Service that creates permanent archived versions of web pages. |
| Megalodon | - | Web archiving tool. |
| Bitsavers | bitsavers.org | Archive focusing on historical computer software and documentation. |
| Bellingcat Auto-Archiver | github.com/bellingcat/auto-archiver | Automated archiving tool from Bellingcat (investigative journalism organization). |
Physical Archival §
Other notes §
- Use the Webrecorder tool suite https://webrecorder.net! It uses a new package file format for web archivss called WACZ (Web Archive Zipped) which produces a single file which you can store anywhere and playback offline. It automatically indexes different file formats such as PDFs or media files contained on the website and is versioned. You can record WACZ using the Chrome extension ArchiveWeb.page https://archiveweb.page/ or use the Internet Archive’s Save Page Now button to preserve a website and have the WACZ file sent to you via email: https://inkdroid.org/2023/04/03/spn-wacz/. There are also more sophisticated tools like the in-browser crawler ArchiveWeb.page Express https://express.archiveweb.page or the command-line crawler BrowserTrix https://webrecorder.net/tools#browsertrix-crawler. But manually recording using the Chrome extension is definitely the easiest and most reliable way. To play back the WACZ file just open it in the offline web-app ReplayWeb.page https://replayweb.page.
- Slightly biased (I work with Webrecorder haha) but yeah, our tools are really good at preserving complete webpages. u/CollapsedWave Give the ArchiveWebpage browser extension a shot! If you’re looking to save single pages as you come across them, it’s a good tool! Every page you capture gets its text extracted for text search. I’ll also add (because they mentioned file format standardization and longevity) that WACZ files are actually ZIP files which contain some indexing metadata that enables fast playback within a single portable file. The actual archived data is stored as a WARC wthin the WACZ and it doesn’t get much more standardized than that! Regardless of what you end up using, I’d really recommend capturing as WARCs or WACZ for cross-compatibility with other software.