tags : Algorithms, Data Engineering, GPGPU, Computer vision, Modern AI Stack, Deep Learning, Modern AI Stack, Deploying ML applications (applied ML)
FAQ
What really matters?
- Traditional Neural Networks
- Good results comes from composing multiple layers (depth) rather than optimizing single layers
- Key components: convolutional layers, recurrent layers, linear layers, dropouts, activation functions. Finding the right thing is useful, but picking the right depth and composition is more important
- Power lies in modularity and depth of composition
- Language Model Evolution
- See Open Source LLMs (Transformers)
- Moving beyond just using/fine-tuning existing models like GPT
- Focus shifting to building task-specific architectures
- Architecture design becoming more important than training techniques (like RLHF)
Keras vs Pytorch vs TF
- Keras is high level framework and has less boilerplate so easy to understand etc. It earlier only largely supported TF but now supports pytorch
- Pytorch is good for training and dev but is hard to put to prod.
- TF is pytorch alternative.
Classical ML vs DL
- See Why Tree-Based Models Beat Deep Learning on Tabular Data
- The combination can be very useful sometimes, for example for transfer learning for working with low resource datasets/problems. Use a deep neural network to go from high dimensionality data to a compact fixed length vector. Basically doing feature extraction. This network is increasingly trained on large amounts of unlabeled data, using self-supervision. Then use simple classical model like a linear model, Random Forest or k-nearest-neighbors to make model for specialized task of interest, using a much smaller labeled dataset. This is relevant for many task around sound, image, multi-variate timeseries. Probably also NLP (not my field).
Categories
- Text
- Text classification
- Test generation
- Summarization
- Audio
- Audio classification
- Automatic speech recognition
- Vision
- Object detection
- Image classification
- Image segmentation
- Multi Modal
- Visual QA
- Document QA
- Image captioning
Generative AI
Diffusion models
These are different from transformers in arch, training process, how they infer, usecase etc.
- See
-
Finetuning diffusion models (Stable Difussion)
-
Dreambooth
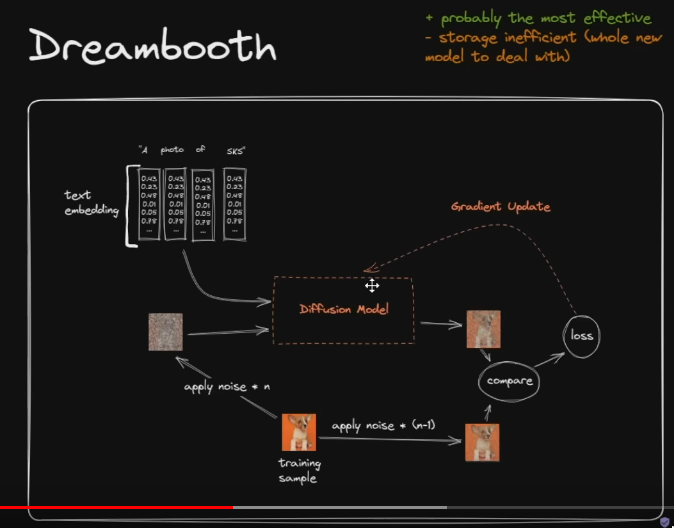
-
Textual Inversion
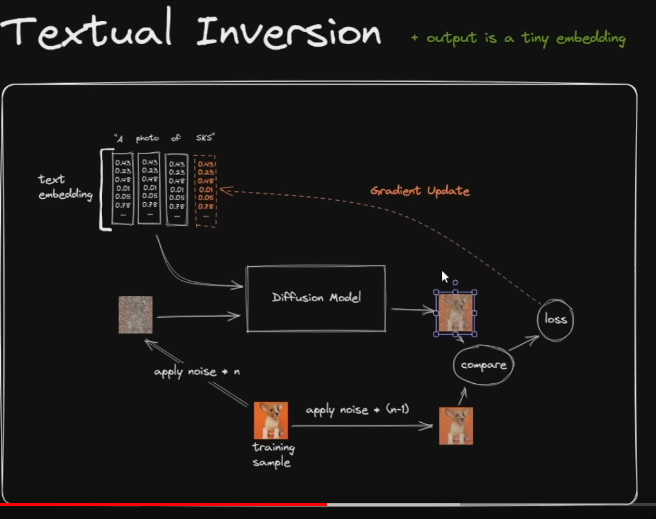
-
LoRA
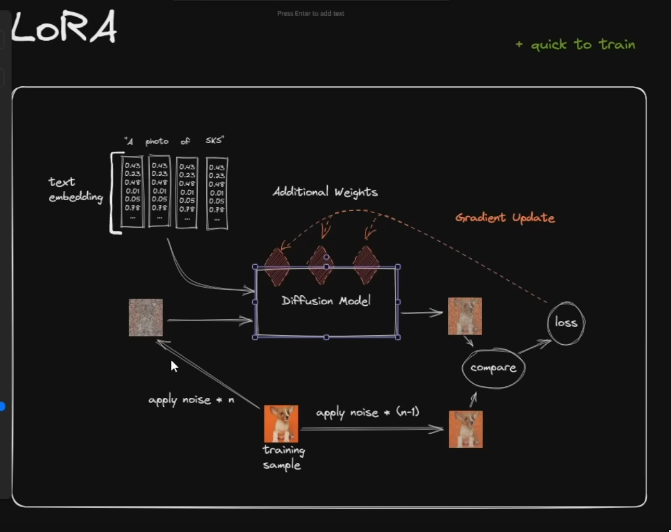
-
Depth-2-Img
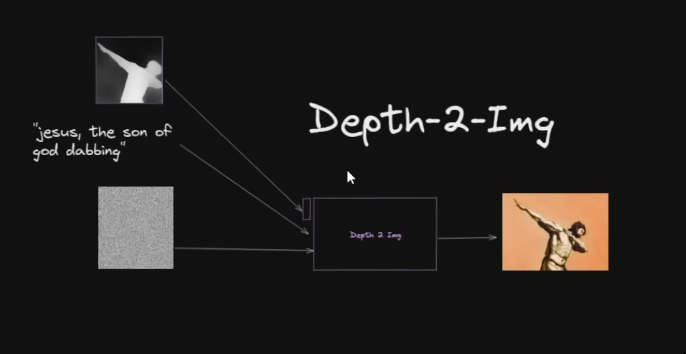
-
ControlNet
- It’s a training strategy, a way of doing fine tuning
- It’s different from Dreambooth and LoRA in ways that they don’t freeze the original model.
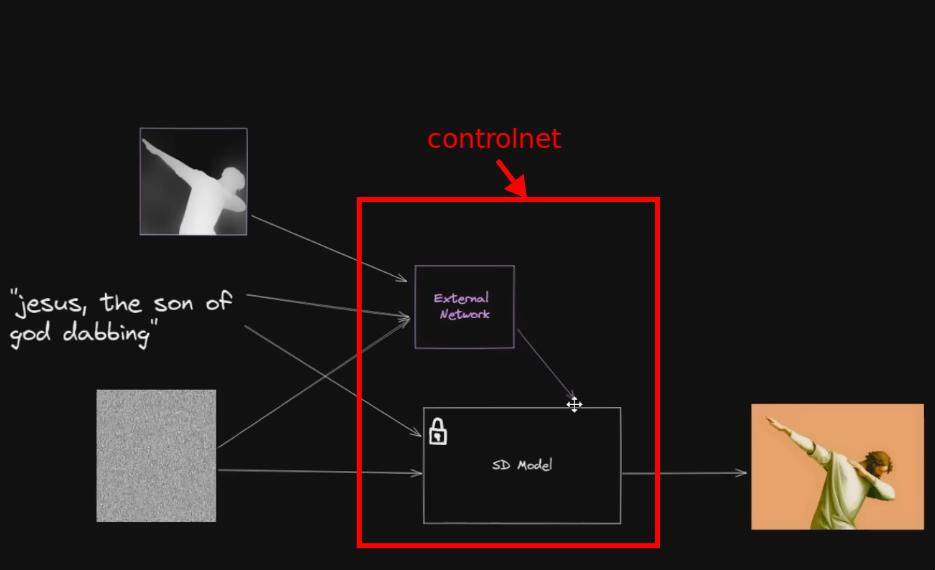
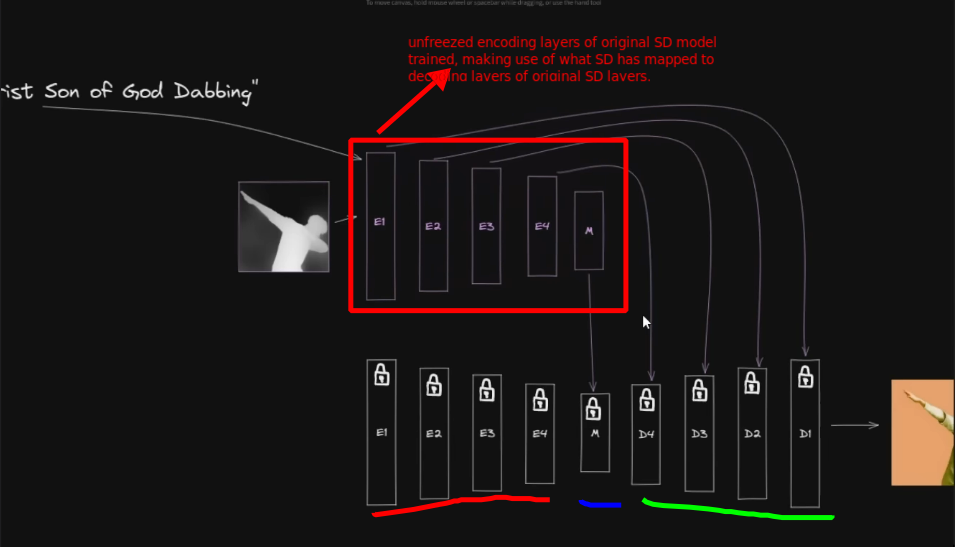
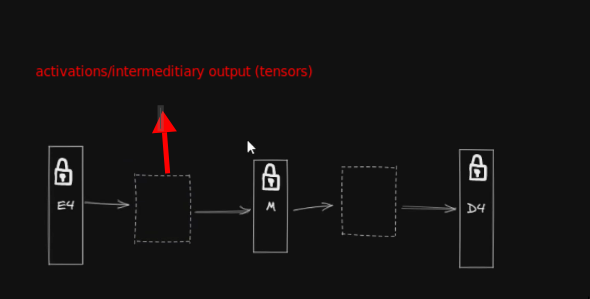
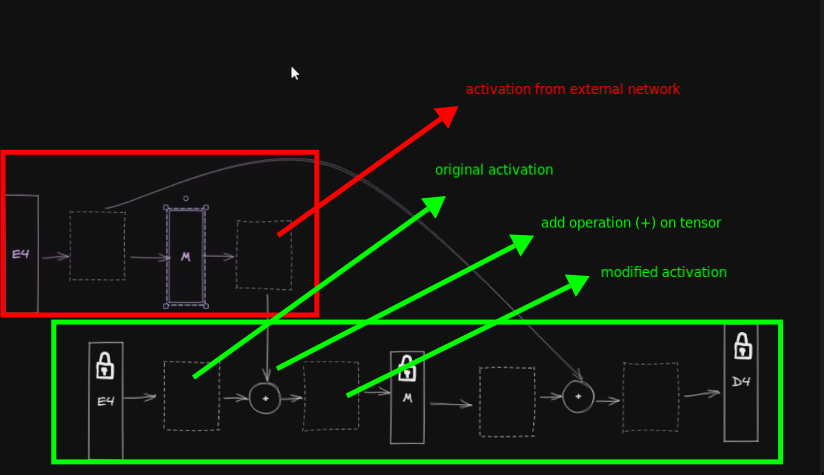

- The complimentary external model can be distributed independently or can be baked into one model.
- The complimentary model is specific to freezed main model so it’ll only work with that version so we need to care about compatibility
-
Transformers
Deep Learning
NLP
Time Series Forecasting / Tabular Data
Retrieval
Clustering
Vision
Voice/Audio
TTS
-
Bark
-
tortoise
- Dia
STT
Scientific Computing
- How to solve computational science problems with AI: PINNs | Hacker News (People not a fan)
Learning Roadmap
Mathematics and Calculus
-
- Linear Algebra
This is what essentially provides the mathematical framework for understanding and manipulating vectors and matrices, which are the building blocks of almost any ML algorithm. A full grasp of these concepts is essential. As always, Khan Academy is a great resource. Below are a list of the essentials, along with the appropriate Khan Academy course materials. You can always choose your own course if you wish to.
-
- Calculus
Calculus, and particularly derivatives and gradients, play a key role in optimization algorithms used in ML. You will rely on Calculus for optimization techniques such as gradient descent, and key components of DL such as Backpropagation - which heavily relies on the chain rule of calculus. Studying integrals and derivatives are fundamental for understanding the rate of change in functions and how they behave, which is crucial for interpreting and modeling real-world use-cases.
-
- Probability and Statistics
Another essential building-block. Probability theory provides a math framework for quantifying uncertainty. In ML, models often need to make predictions or decisions based on incomplete or noisy data. With probability, we can easily express that uncertainty and reason about it. There’s myriad other reasons for learning probability, of course; just keep in mind that Language Models generate text by taking your input and calculating the probability distribution of the next sequence of words that would follow it, and pick the most likely output to complete your input text.
You can take only the lessons you think might be important and then take the Course Challenge.
- Discrete and continuous probability distributions: binomial and normal (Gaussian).
- Bayesian Statistics
That should probably be enough for Math. I might’ve missed a few essential things, but I will add more as I come across them.
Programming
The current programming language dominating the ML community is Python. Not surprising, since the ease of use allows you to focus on writing efficient code without needing to spend too much time learning the intricacies of the language’s syntax. There’s a good chance you already know Python, but we’ll go over the basic steps anyway.
-
Learn Python Basics
The
roadmap.shPython Developer roadmap is an incredibly useful resource for this. What it essentially boils down to, however, is:- Learn the Basic Syntax and Data Types
You’ll need to familiarize yourself with Python’s syntax, variables, data types (integers, floats, strings, lists, dicts), and basic operations (arithmetic, string manipulation, indexing, slicing).
- Control Flow
Understand conditional statements (
if,elif,else), loops (for,while), and logical operators (and,or,not). Very important for implementing decision-making and repetition in your code.- Functions and modules
Learn how to define and use functions to encapsulate reusable blocks of code. Also, you’ll need to understand how to import and utilize modules (libs).
- Data Structures and Manipulation
Get yourself acquainted with fundamental data structures like lists, tuples, sets, and dictionaries. Learn how to manipulate and transform data.
- NumPy
A fundamental library for scientific computing in Python. You will need to gain proficiency in using NumPy arrays for efficient numerical computations.
- Pandas
You will often need Pandas DataFrames to clean, transform, filter, aggregate, and analyze your datasets.
- Plotting and Data Visualization
Become familiar with libraries such as Matplotlib and Seaborn for creating plots, charts, and visualization. Not strictly necessary, but recommended.
-
Learn Advanced Python
At this stage, you’ll be sufficiently familiar with Python and ready to tackle the ML aspects of Python. Very exciting.
- Machine Learning Libraries
Explore the popular ML libraries, such as PyTorch, TensorFlow, or scikit-learn. It’s recommended to focus on only one, and as of now, PyTorch is the most popular.
- Object-Oriented Programming (OOP)
Get yourself comfortable with the principles of OOP, including classes, objects, inheritance, and encapsulation. Allows for modular and organized code design.
Machine Learning Concepts
At this point, you can follow whatever ML course you’re comfortable with. A popular recommendation is fastai. It’s a great resource for almost everything you’ll need to learn about ML. Otherwise, pick any of the concepts below that interest you and get to learning.
-
Supervised Learning
This Coursera curriculum on Supervised ML will be useful. As of writing this guide, the course is completely free. The main points to learn are:
- Classification: Predicting discrete class labels.
- Regression: Predicting continuous values.
-
Unsupervised Learning
This course should provide the adequate amount of knowledge on Unsupervised Learning. The main points to learn are:
- Clustering: Grouping similar data points together.
- Dimensionality Reduction: Reducing the number of input features while preserving important information.
- Anomaly Detection: Identifying rare of abnormal instances in the data.
-
Reinforcement Learning
Coursera provides this course on Reinforcement Learning, which should be a good starting point.
-
Linear Regression
This resource should be a useful starting point. The main outtakes are:
- Understanding linear regression models and assumptions.
- Cost functions, including mean squared error.
- Gradient descent for parameter optimization.
- Evaluation metrics for regression models.
-
Logistic Regression
Read through this resource as a starting point. Main outtakes will be:
- Modeling binary classification problems with logistic regression.
- Sigmoid function and interpretation of probabilities.
- Maximum likelihood estimation and logistic loss.
- Regularization techniques for logistic regression.
-
Decision Trees and Random Forests
This incredible resource by Jake VanderPlas should be extremely useful. Main outtake are:
- Basics of decision tree learning.
- Splitting criteria and handling categorical variables.
- Ensemble learning with random forests.
- Feature importance and tree visualization.
-
Support Vector Machines (SVM)
Read through this resource. The main outtakes are:
- Formulation of SVMs for binary classification.
- Kernel trick and non-linear decision boundaries.
- Soft margin and regularization in SVMs.
- SVMs for multi-class classification.
-
Clustering
Read through this excellent Google for Developers course on Clustering. The main outtakes are:
- Overview of unsupervised learning and clustering.
- K-means clustering algorithm and initialization methods.
- Hierarchical clustering and density-based clustering.
- Evaluating clustering performance.
-
Neural Networks and Deep Learning
See Deep Learning The heart of the matter. Read through the papers for each:
-
Evaluation and Validation
Read the following papers:
- Using J-K fold Cross Validation to Reduce Variance When Tuning NLP Models
- Leave-One-Out Cross-Validation for Bayesian Model Comparison in Large Data
And this HuggingFace guide on Evaluating ML models.
-
Feature Engineering and Dimensionality Reduction
Take a look at this article for a general oveeview. Also read these papers:
-
Model Selection and Hyperparameter Tuning
This is where you’re finally dabbling in model training. Good job! You will need to learn:
- Grid search, random search, and Bayesian optimization for hyperparameter tuning.
- Model selection techniques, including nested cross-validation.
- Overfitting, underfitting, and bias-variance tradeoff.
- Performance comparison of different models.