tags : Machine Learning, Deploying ML applications (applied ML), NLP (Natural Language Processing)
Concepts
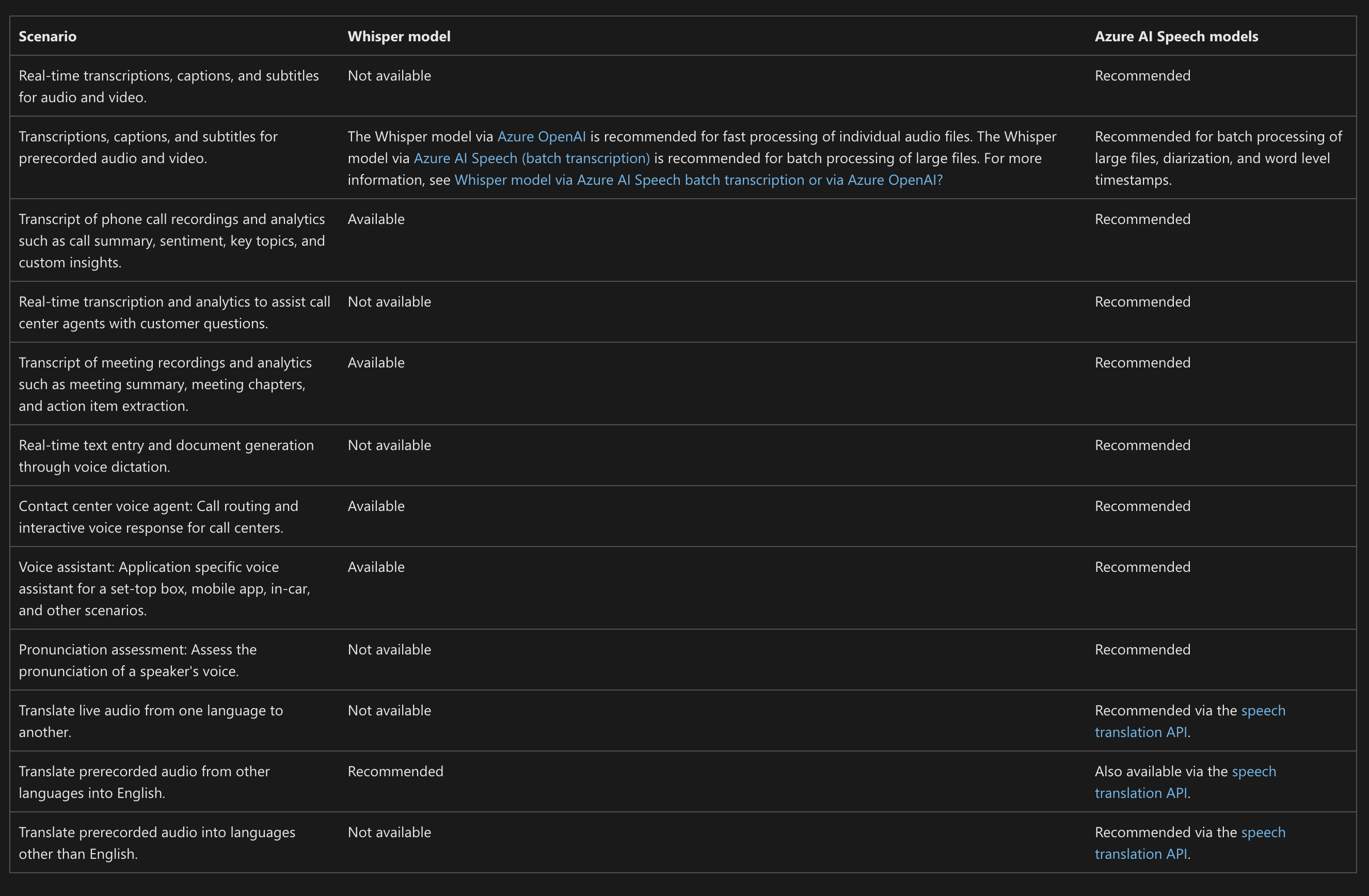
Diarization
- After transcription, further improvements like diarization, spelling correction, and context-based fixes are often needed. You can use an LLM to review and refine the transcript for better accuracy.
- It’s CPU bound
- It’s a separate process after transcription
- If you use WhisperX that’ll do this for you.
pyannote/speaker-diarization-3.1
- Does a decent job.
- You can finetune pyannotate for your specific language aswell
Speaker embedding trick using speechbrain/spkrec-ecapa-voxceleb
For cleaning up diarization accuracy I now use: https://huggingface.co/speechbrain/spkrec-ecapa-voxceleb
The approach I’ve found best to cleanup the diarization (or replace pyannote entirely) is to generate speaker embeddings for each segment whisper generates, then group by matching the speaker embeddings.
For segment in segments: Generate speaker embedding For known speakers: If match, add to array of segments for that speaker. Else create a new entry for a new speaker.
I have found that to massively reduce the number of speakers found in an audio recording. Though if someone gets emotional or changes their speech significantly it still produces a bonus extra speaker. But far less than before.
This approach might struggle with the overlapping part of the overlapping speakers. But it’ll do a lot better than pyannote and might give you a start in finding the overlaps before using another model to analyse them.
Nvidia Nemo
- https://github.com/NVIDIA/NeMo/blob/stable/tutorials/speaker_tasks/Speaker_Diarization_Inference.ipynb
- Google Colab
Custom vocabulary
- STT models allow prompting, this can help sometimes.
- prompting essentially boost the
log-probsfor certain vocab items,
- prompting essentially boost the
- But prompting(
initial_prompt) is not always the thing that works out, other techniques involve- Supressing tokens: Adding custom vocabularies on Whisper - #5 by andregn - Beginners - Hugging Face Forums
- Finetuning based on what you need, you may or may-not need to fiddle with the
extractor/tokenizer, most probably you would not need to mess with those. The thread above goes into more depth. But messing thetokenizerwould mean re-sizing the embedding layer.
- Related papers
Proper noun recognition/correction
- Instead of fine-tuning the whisper model, etc. which is trying to correct things pre-transcription
- You can have a
master documentwith all your nouns listed, better if this is a structured output like a list - You can then just use an LLM to get:
- Input: Raw transcript + noun list
- Output: Cleaned-up transcript
Punctuation accuracy
Spelling consistency
Formatting for readability
Code-switching/Code-mixing
- Mixing words from multiple languages in a single sentence.
- Switching languages between phrases or sentences.
- Probable fixes
- Use whisper-large or large-v2 for better multilingual and code-switching support.
- Don’t manually set the language unless the entire audio is in one language.
- Use an LLM to clean up grammar, fix transliterations, and improve mixed-language coherence.
Complex usecases
Command and intent recognition– understanding user intent from spoken input (e.g., “delete that”, “no, I meant…”).Context-aware natural language understanding (NLU)– interpreting corrections, references to previous utterances, and implicit meaning.Conversational AI– managing complex dialogue flows where speech is both input and control.
Translation
- Variable Multilingual Performance: Whisper’s accuracy (WER/CER) differs significantly across languages, with better performance generally seen in languages well-represented in its training data.
- Eg. In Whisper currently, Spanish has a better WER than English! this thread has some explanations.
- Transcription in Detected/Specified Language & Basic English Translation: Whisper transcribes audio into the language it identifies or is instructed to use, and it can directly translate multiple non-English languages into English.
- Limited Direct Translation Beyond English: Direct translation to languages other than English is not a primary built-in feature.
BUT IT WORKS, sometimes- “The one and a half hour Russian video has been translated into German.“, see this discussion
- This can be fine-tuned
- Post-Processing for Advanced Needs: Further translations (non-English targets) or transliterations require separate post-processing steps after the initial transcription.
Unsupported Language
- Fine-Tune Whisper For Multilingual ASR with 🤗 Transformers
- Singlish-Whisper: Finetuning ASR for Singapore’s Unique English | Jensen Low (Custom language fine tuning)
Other tunings
- You can tweak decoder generation parameters. Since it is GPT under the hood, you can tweak the sampling parameters to make it spit out fewer repetitive words, and also add text as prompt to make the model understand the context of the transcription.
Models
Whisper & Whisper variants

OpenAI Whisper
current sota: openai/whisper-large-v3-turbo
WhisperX (Diarization)
- (uses faster whisper)
- hallucinates way less because it has VAD pre-processing
- has 2x+ better performance on long-form cuz batching
Whisper-Diarization
- I don’t understand the difference between this and Whisper X yet.
- https://github.com/MahmoudAshraf97/whisper-diarization
- It uses Nvidia Nemo
WhisperLiveKit
https://github.com/QuentinFuxa/WhisperLiveKit
WhisperAT (audio tagger)
https://github.com/YuanGongND/whisper-at
Distil-Whisper
- These are English only model, faster and smaller etc.
- The distil technique can be applied for any other language
- This does NOT improve the accuracy on any certain language. It just makes the model smaller and specific. To improve the actual accuracy you have to fine tune the model either way. So you would usually fine tune the larger model, the teacher model.
WhisperFusion
- WhisperFusion use WhisperLive (same developer). That is really human like speech. WhisperFusion runs on a single RTX 4090. But because I want to use it for my own project I’m more interested on WhisperLive itself. But WhisperFusion shows how quick it could be if you bring all together.
- WhisperFusion: Ultra-low latency conversations with an AI chatbot
WhisperStreaming
WhisperS2T
Nvidia
Nvidia Nemo is putting out few interesting models
- Has
nvidia/parakeet-tdt-0.6b-v2which is nice but unsure about multilingual - Canary
Gemini
- For better diarization, people have run the audio through nvidia nemo and then passed that output to gemini to get accurate output. See this thread for example
- Gemini is pretty good and cheap aswell
- https://github.com/pmmvr/gemini-transcription-service/tree/main
- ~150 hours has been transcribed for a total cost of $4
Meta
- Massively Multilingual Speech (MMS) - Finetuned ASR - ALL
- https://huggingface.co/facebook/mms-1b-all
- Scaling Speech Technology to 1,000+ Languages - Meta Research
Sarvam and AI4Bharat has many interesting models
- They have also listed around how we can train for low resource languages.