tags : Machine Learning, Modern AI Stack, Open Source LLMs (Transformers), Infrastructure, Modal Labs Serverless GPU
Benchmarks/Leaderboards
OCR
Embeddings
- https://huggingface.co/spaces/TIGER-Lab/MMEB-Leaderboard
- https://huggingface.co/spaces/vidore/vidore-leaderboard
- https://huggingface.co/spaces/mteb/leaderboard 🌟
STT / ASR
- https://huggingface.co/spaces/hf-audio/open_asr_leaderboard
- https://voicewriter.io/speech-recognition-leaderboard
TTS
Providers
GPU
OSS Model
The pipeline
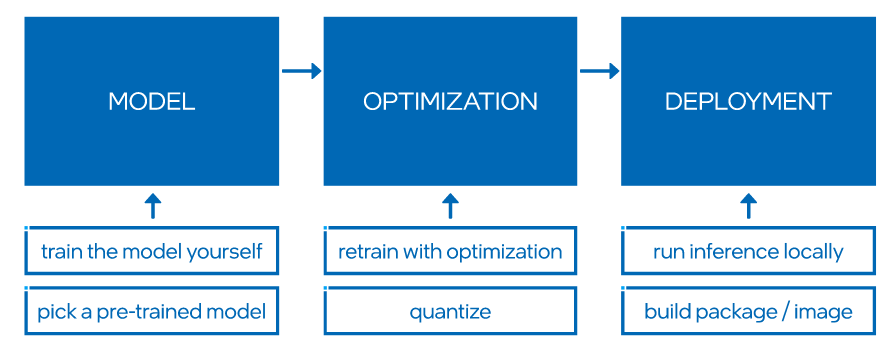
Overall
Problem Definition & Scoping
- Understand the business/research goal.
- Define success metrics (accuracy, latency, cost, fairness, etc.).
- Assess feasibility, data availability, and ethical considerations.
- Determine project scope and constraints.
Data Acquisition & Understanding
- Identify data sources.
- Collect or procure data.
- Exploratory Data Analysis (EDA): Understand distributions, biases, quality issues.
- Data documentation and versioning.
Data Preparation & Feature Engineering
- Data cleaning (handling missing values, outliers).
- Data splitting (train, validation, test sets).
- Feature extraction / selection.
- Feature Transformation (as you detailed: scaling, encoding, specific transforms for model input).
- Data augmentation (if applicable).
Model Selection & Architecture Design
- Choose appropriate model types (e.g., Linear, Tree-based, NN, Transformer).
- Select or design the specific model architecture.
- Consider transfer learning or using pre-trained models.
Model Training
- The real point of using GPUs is often to form minibatches during training.
- Training is doing
forward + backward + applying gradients
- Set up training infrastructure (hardware like GPUs/TPUs, distributed training frameworks like DeepSpeed).
- Define loss function and optimizer.
- Weight Training (as you detailed: forward/backward pass, minibatching, gradient accumulation, hyperparameter tuning).
- Consider Training Laws (e.g., Chinchilla scaling laws for LLMs).
- Potentially use Quantization Aware Training (QAT).
- Experiment tracking and management (MLOps).
Model Evaluation
- Evaluate model performance on the validation set using predefined metrics.
- Error analysis: Understand where the model fails.
- Compare different models/hyperparameters.
- Final evaluation on the hold-out test set.
- Assess fairness, bias, and robustness.
Model Optimization (for Deployment)
- Optimize Weights/Architecture (as you detailed):
- Quantization (Post-Training Quantization - PTQ, various schemes like int8, 4-bit, GPTQ, using tools like OpenVINO, bitsandbytes).
- Pruning.
- Knowledge Distillation.
- Convert to efficient inference formats (e.g., ONNX, TensorFlow Lite, TensorRT).
Serialization & Packaging
- Serialize the model and weights (as you detailed: using formats like SavedModel, .pt/.pth, safetensors, ggml, ONNX; considering security implications).
- Package necessary components (tokenizer, configuration files, dependencies).
Deployment
- Choose deployment strategy (batch inference, real-time API, edge/mobile, web-based like Wasm/WebGPU).
- Set up serving infrastructure (e.g., TensorFlow Serving, Nvidia Triton, custom API, cloud endpoints like AWS Inferentia, serverless).
- Ship the weights/package to the target environment.
- Implement inference pipelines.
Inference
- Run the deployed model on new data (as you detailed: focus on low latency/high throughput, hardware considerations CPU vs GPU).
- Handle input/output processing.
Monitoring & Maintenance
- Monitor model performance in production (accuracy drift, latency, resource usage).
- Monitor data drift and concept drift.
- Set up alerting for issues.
- Log predictions and feedback.
Continuous Learning & Retraining
- Establish retraining triggers and strategies (scheduled, performance-based).
- Incorporate new data and feedback.
- Potentially use Online Learning or Federated Learning techniques.
- Iterate on the entire workflow based on monitoring and new requirements.
More on each step
MLOps/Experiment Tracking is implicitly crucial throughout, especially in steps 4-6 and 11-12.
Serialize the weights
-
Core Concepts
- Combined Saving: Model architecture + weights often saved together (ONNX, TF SavedModel).
- Separate Weights: Weights saved alone (.safetensors, PyTorch state_dict), architecture defined in code.
- PyTorch state_dict: Dictionary of layer parameters (.pt/.pth), needs separate architecture code.
-
Key Components for Sharing
- Weights/Checkpoints: The numerical parameters (.safetensors, .pt, .pb).
- Model Architecture: Layer structure (in file or code).
- Tokenizer: Config/vocab for text models (tokenizer.json, vocab.txt).
-
Common Formats & Use Cases
Format / Extension(s) Underlying Tech / Type Primary Purpose Key Characteristics .pt / .pth (unsafe) Python `pickle` PyTorch saving/loading (`torch.save()`) Easy PyTorch use; avoid untrusted sources. .joblib (unsafe) Pickle variant Scikit-learn object persistence (NumPy efficient) Optimized pickle for NumPy; common in Scikit-learn. .ckpt (unsafe) TF internal / Pickle? Older TF training state save/restore Legacy TF format; `SavedModel` is preferred now. .gguf Custom binary Efficient LLM execution (CPU, quantized) Single file (weights, hyperparams, vocab); arch in loader code (e.g., `llama.cpp`). .safetensors Custom tensor format Safe & fast tensor (weights) storage Preferred for sharing weights; often allows fast zero-copy loading. .onnx Protobuf (Graph+Weights) Framework interoperability, inference optimization Deploy across platforms/engines (ONNX Runtime, TensorRT); contains graph & weights. .pb / saved_model/ dir Protobuf (Graph+Weights) TensorFlow serving/deployment standard Native TF format for production; contains graph & weights. .h5 / .keras HDF5 Keras saving (arch, weights, optimizer) Common in Keras; stores architecture, weights, optimizer state. TorchScript (jit.save) TorchScript (Graph) Deployment in non-Python (e.g., C++) environments Graph-first format (not pickle); independent of Python runtime for inference. .tflite FlatBuffers Mobile/Edge/Embedded TF models (now LiteRT) Optimized for on-device inference; small size, fast loading. .mlmodel / .mlpackage Apple Proprietary Deployment on Apple devices (iOS, macOS) Native Apple format; `.mlpackage` is newer package format. .pmml / .xml XML Traditional ML/Stats model exchange (DMG std) Interoperability for regression, trees, SVMs etc. Less common for NNs. NNEF Khronos Group Standard Interoperability (training <-> inference) Alternative to ONNX, less common adoption.
Deployment & Inference (ML models)
Deployment of LLMs is different, follows the same concepts but the things to consider/tools etc. becomes different and not covered in this section
-
Core Concepts of Inference
- Process: Inference involves feeding new input data into a trained model and executing a forward pass to generate an output (prediction, classification, generation, etc.). It does not involve backpropagation or weight updates like training.
- Primary Goal: Often, the primary goal for inference, especially in online systems, is low latency (quick response time). Throughput (predictions per second) is also critical, particularly for batch processing or high-traffic services.
- Hardware Trade-offs (Brief Mention): Choice between CPU, GPU, or specialized hardware depends on model size, desired speed, and cost. Data transfer overhead exists when using accelerators like GPUs (RAM <-> GPU Memory).
-
Deployment Strategies
Factor Serving Inference (Online Serving) Batch Inference (Offline Inference) Timing Real-time, on-demand Scheduled, periodic Data volume Individual records Large datasets Infrastructure Scalable APIs, microservices Data processing pipelines Optimization Latency, availability Throughput, efficiency Monitoring Response time, availability Job completion, resource usage Example Ray, Metaflow Ray Server, TF Serve, vLLM etc -
-
Online / Real-time Inference
- Description: Models are hosted as continuously running services (often web services/APIs) that process incoming requests individually and return predictions immediately.
- Mechanism: Typically exposed via an HTTP API endpoint (
inference endpoint). A request containing input data is sent, the model processes it, and the prediction is returned in the HTTP response. - Use Cases: Live recommendations, fraud detection, interactive chatbots, image recognition in apps.
- Goal: Minimize latency for a good user experience.
-
-
-
Offline / Batch Inference
- Description: The model processes a large collection (batch) of data points at once. Predictions are generated for the entire dataset and stored for later use. Real-time response is not required.
- Mechanism: Often run as scheduled jobs (e.g., nightly). Reads input data from storage (database, file system), runs inference, writes results back to storage.
- Use Cases: Generating reports, data analysis, pre-calculating features or predictions, processing large logs.
- Goal: Maximize throughput (process as much data as possible in a given time/cost budget).
-
-
-
Edge Inference
- Description: The model runs directly on the end-user’s device (smartphone, IoT device, computer) or local hardware.
- Pros: Very low latency (no network call), functions offline, enhances data privacy (data doesn’t leave the device).
- Cons: Limited by device capabilities, requires model optimization, deployment/update management can be complex.
-
-
-
Browser-Based Inference
- Description: A specific type of edge inference where the model runs directly within the user’s web browser.
- Technologies:
- WebAssembly (Wasm): Compiles code (often C/C++) to run efficiently in the browser, typically using the CPU.
- Examples:
GGMLlibraries (whisper.cpp Wasm) have Wasm targets for running models like Whisper or Llama 2 directly in the browser.
- Examples:
- WebGPU: A modern web API providing access to the device’s GPU capabilities from within the browser, enabling hardware acceleration.
- Examples:
WebLLM/MLC LLM: Uses Apache TVM to compile models for WebGPU execution, combined with Emscripten for the CPU runtime (compiled to Wasm). Enables running LLMs and models like Stable Diffusion in the browser (web-llm, mlc-llm, web-stable-diffusion).WebGPT(Concept/Older): Explored using browser capabilities for QA tasks ([2112.09332] WebGPT: Browser-assisted question-answering with human feedback, code).
- Examples:
- WebAssembly (Wasm): Compiles code (often C/C++) to run efficiently in the browser, typically using the CPU.
-
-
-
Inference Engines & Serving Frameworks
- TensorFlow Serving: High-performance serving system for TensorFlow models. Can also serve other formats via extensions (like ONNX).
- Nvidia Triton Inference Server: Supports models from various frameworks (TensorFlow, PyTorch, TensorRT, ONNX, OpenVINO) on both GPUs and CPUs. Provides features like dynamic batching and model ensembling. (Note: Distinct from OpenAI Triton).
- PyTorch Serve / TorchServe: A PyTorch-specific model serving library developed with AWS.
- ONNX Runtime: Cross-platform inference engine for models in the Open Neural Network Exchange (ONNX) format. Allows training in one framework (e.g., PyTorch) and inferring in another or with TF Serving.
- KServe (formerly KFServing): Provides a Kubernetes Custom Resource Definition for serving ML models on Kubernetes. Standardizes inference protocols.
- Cloud Provider Solutions: AWS SageMaker Endpoints, Google Vertex AI Endpoints, Azure Machine Learning Endpoints offer managed infrastructure for deploying and scaling models.
- Apache TVM: An open-source machine learning compiler framework for CPUs, GPUs, and specialized accelerators. Optimizes models for specific hardware targets, including WebGPU/Wasm for browsers.
Deployment & Inference (LLMs)
See Open Source LLMs (Transformers)
- Online Serving (real-time, low-latency responses like chatbots)
- Batch Offline Processing (asynchronous, high-throughput tasks like data analysis).
-
Core Challenges in LLM Deployment
- The Memory Wall: LLMs require vast amounts of memory (GPU VRAM) for their parameters and intermediate calculations (KV cache). The time spent moving data between the GPU’s main memory (HBM) and its faster caches is often the biggest performance bottleneck, more so than the computation itself.
- Computational Intensity: Operations like matrix multiplication and attention, while suited for GPUs, are very demanding, especially for long inputs or sequences.
- Balancing Latency and Throughput: Interactive applications need fast individual responses (low latency), while backend systems often aim to process many requests efficiently (high throughput). Optimizing for one can negatively impact the other.
-
Key Optimization Strategies
-
What makes LLMs slow?
- Kernels are just functions that run on a GPU
- Flash attention, page attention etc are just better implementation of attention.
LLM operations need to transfer data from slow memory to fast memory caches. This takes the most time.

- Solution
- Smarter cuda kernels(flash attention, paged attention, softmax etc.)
- Smaller data(quantization! etc.)
-
Making LLMs Fast
Category Techniques Low-level optimizations - Kernel fusion - Kernel optimization - CUDA Graphs Run-time optimizations - Continuous batching - KV Caching - Hardware upgrades Tricks - Speculative decoding - Shorter outputs - Shorter inputs -
Model Compression: Quantization
- Goal: Reduce memory usage (model weights, KV cache) and potentially speed up calculations by using data types with lower precision.
- Common Methods:
- Post-Training Quantization (PTQ): Quantizing a pre-trained model without further fine-tuning. Common techniques include:
- GPTQ: Accurate, layer-by-layer quantization.
- AWQ (Activation-aware Weight Quantization): Protects salient weights based on activation magnitudes, often providing a good balance of speed and accuracy. (e.g., mit-han-lab/llm-awq, casper-hansen/AutoAWQ).
- GGUF (used by Llama.cpp): A flexible format supporting various quantization methods (e.g., 2-bit, 4-bit, 5-bit, 8-bit) and often incorporating techniques like k-quants.
- BitsAndBytes: Library offering 4-bit (NF4, FP4) and 8-bit quantization, often integrated directly into frameworks like HF Transformers.
- Quantization-Aware Training (QAT): Incorporating the quantization process during fine-tuning, which can sometimes yield better accuracy but requires more effort.
- KV Cache Quantization: Applying quantization specifically to the Key-Value cache to reduce its memory footprint, crucial for handling long contexts. (e.g., recent efforts in ollama).
- Post-Training Quantization (PTQ): Quantizing a pre-trained model without further fine-tuning. Common techniques include:
-
Runtime & Low-Level Optimizations
- Optimized GPU Kernels: Custom GPU functions for specific LLM tasks.
- FlashAttention: Reduces memory reads/writes during attention calculation.
- PagedAttention: More efficient KV cache memory management, enabling higher batch sizes.
- Kernel Fusion: Combines multiple GPU operations into one, reducing overhead.
- CUDA Graphs: Optimizes sequences of GPU operations for lower launch latency.
- Efficient Caching:
- KV Caching: Reusing calculated Key/Value states to speed up token generation.
- Smart Batching:
- Continuous Batching: Dynamically adding/removing sequences from a batch to maximize GPU utilization and throughput.
- Optimized GPU Kernels: Custom GPU functions for specific LLM tasks.
-
Advanced Inference Techniques
- Speculative Decoding: Using a small “draft” model to generate candidate tokens quickly, verified by the main model.
- Input/Output Optimization: Using shorter prompts or constraining output length reduces computation.
- Test-Time Compute / Multistep Reasoning: Employing more computation during inference (e.g., search algorithms like Beam Search, Tree Search guided by reward models) to improve reasoning quality, allowing smaller models to tackle complex tasks effectively.
-
-
-
Inference Engines & Frameworks Comparison
Framework Key Strengths / Features Primary Use Case / Best For Hardware Support Quantization Support Notable Limitations / Considerations vLLM PagedAttention, Continuous Batching, High Throughput High-performance serving on NVIDIA GPUs (model fits in VRAM) CUDA Good (AWQ, GPTQ) Primarily NVIDIA CUDA focused. Llama.cpp Excellent CPU & Hybrid CPU/GPU, Flexible Quant (GGUF), Metal Consumer hardware, Limited VRAM, Apple Silicon, CPU inference CPU, CUDA, Metal, OpenCL, ROCm Excellent & Flexible (GGUF: various bits) Batching support is newer/evolving. MLC-LLM Cross-platform (TVM), Fast on diverse HW without CUDA/ROCm IGPs, Mobile, AMD/Intel GPUs, Web deployment (WebGPU) Vulkan, Metal, OpenCL, CUDA, WebGPU Supported Quantization quality/flexibility may vary. exLLAMAv2 State-of-the-art Quantization (EXL2), Fast non-batched speed Fitting large models on VRAM-limited GPUs (accuracy focus) CUDA, ROCm (?) Excellent (EXL2) Primarily optimized for non-batched inference. HF Transformers Standard library, Ease of Use, Research/Development Experimentation, Fine-tuning, Basic deployments CPU, CUDA (via Accelerate/BnB) Basic (BitsAndBytes) Lower performance/efficiency vs. specialized engines. TensorRT-LLM (NVIDIA) Highly optimized kernels, Compiler optimizations, Batching Peak performance production serving on NVIDIA hardware CUDA (NVIDIA GPUs only) Good (INT8, FP8, INT4) NVIDIA ecosystem lock-in, Can be complex. TGI (Hugging Face) Production-ready server, Continuous Batching, Optimized code Scalable self-hosted serving, Backend for HF Endpoints CUDA Good (BitsAndBytes, AWQ, GPTQ, EETQ) Primarily focused on serving via API endpoint.
-
Deployment Styles & Platforms
-
Managed Services
- Pros: Simplified infrastructure, auto-scaling, managed environment.
- Cons: Higher potential cost, less control, vendor-specific implementations.
- Examples: Replicate (uses
Cog), Modal (flexible serverless GPU), Hugging Face Inference Endpoints, AWS SageMaker, Google Vertex AI, Anyscale, Fireworks.ai, Together.ai.
-
Self-Hosted
- Pros: Full control, potentially lower cost, customizable setup.
- Cons: Requires significant MLOps/DevOps effort for setup, scaling, and maintenance.
- Approaches:
- Container Orchestration: Kubernetes (with KServe, etc.) for scalable deployment.
- Distributed Frameworks: Ray Serve (can integrate with vLLM).
- Custom VM/Server Setup: Manually configuring instances, potentially using cloud tools like AWS EC2 Image Builder + Auto Scaling Groups for automation.
- Specialized Tools: Frameworks or guides like
paddlermight offer specific blueprints (refer to their documentation).- https://github.com/marella/ctransformers (ggml python bindings)
-
Observability in AI
TODO Training & Fine-Tuning
Dataset preparation
Training
“The technical parts are less common and specialized, like understanding the hyperparameters and all that, but I don’t think that is the main problem. Most people don’t understand how to build a good dataset or how to evaluate their finetune after training. Some parts of this are solid rules like always use a separate validation set, but the task dependent parts are harder to teach. It’s a different problem every time.” someone on hn
- LLM RL fine tuning for Agents: https://openpipe.ai/
- https://medium.com/pinterest-engineering/last-mile-data-processing-with-ray-629affbf34ff
Ecosystem
Orchestration ML pipeline

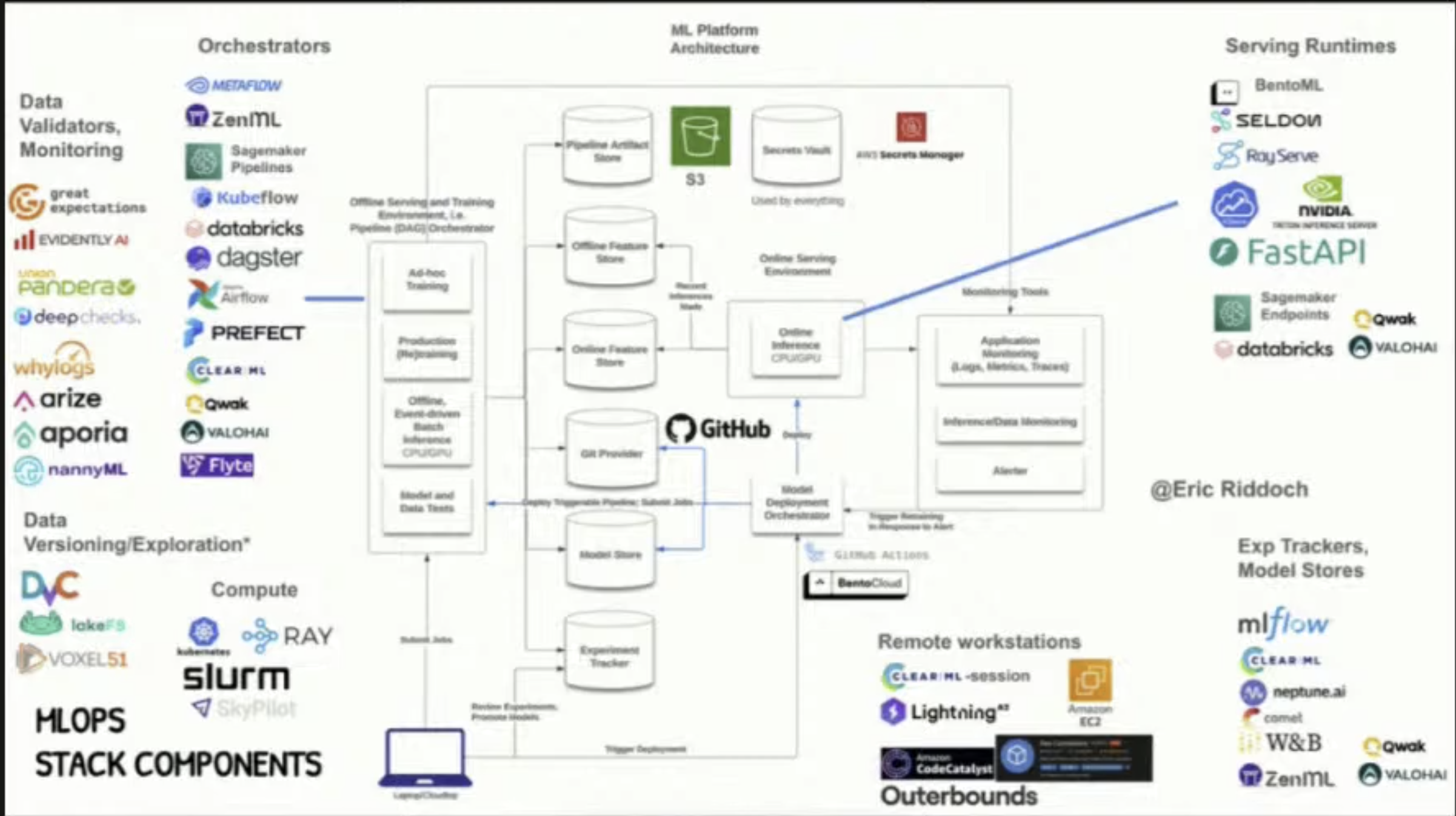
See Orchestrators and Scheduling and Comparing ZenML, Metaflow, and all the other DAG tools - YouTube
Well we have things like Kubernetes and Nomad for workload scheduling. But for ML workloads we still need more specific tooling like perfect/metaflow etc. Dagster, Airflow are more Data Engineering specific, we can use them for Machine Learning stuff but they are not purpose built for those usecases. So we have spcific ML specific workflow orchestrators like flyte and metaflow.
I think we can simply go with dagster
What’s in the market?
Best Machine Learning Workflow and Pipeline Orchestration Tools
Flyte: Created by Lyft, focuses on highly reproducible, scalable ML and data processing workflows. Strong typing system and containerization support.
][flyte vs dagster for ml pipeline]]
Metaflow: Developed by Netflix, emphasizes a simple Python API for data scientists while handling infrastructure complexity behind the scenes.- https://outerbounds.com/: is the hosted version of Metaflow
- WanDB and
Raycan be integrated. See Scaling AI at Autodesk with Ray and Metaflow
Dagster: Asset-oriented orchestrator with strong data observability features and a focus on software engineering practices for data.Prefect: Emphasizes positive engineering experience with a modern Pythonic approach to workflow definition.prefectcan be used to kick offmodal labstraining pipeline
- Sagemaker Pipeline
- Kubeflow
- ClearML
- Airflow
Do I really need to use metaflow / flyte ?
- Well, not really.
metaflow/flyte: Machine Learning DAG tooldagster/prefect/airflow: Data Engineering DAG tool
- ML specific orchstration can help with this:
- Step1 of DAG = Needs 2 GPU because training
- Step2 of DAG = 1 GPU because doing inference here.
- i.e it’s solving for heteregenous compute
- BUT! with something like
Modal Labs, which handles the compute for you, you can totally skip using ML specific DAG tool and use traditional Data Engineering specific DAG tools.
Sometimes you might NOT even need ANY dag tool. Simply something like Modal might solve it.
What about Kubeflow and MLflow?
Totally different tools but have “flow” in the name.
-
MLFlow
MLflow isn’t a workflow orchestrator but rather an ML lifecycle management tool with four main components:
- MLflow Tracking: Experiment tracking, metrics, and artifacts
- MLflow Projects: Packaging format for reproducible runs
- MLflow Models: Model packaging for deployment across platforms
- MLflow Registry: Model versioning and stage transitions
If we use
MetaflowandWanDB(Weights&Biases), it makes less-and-less sense to use something like MLFlow.Alternatives: https://neptune.ai
-
KubeFlow
Kubeflow is different from the others you mentioned as it’s specifically built on top of Kubernetes and provides a complete ML platform, not just workflow orchestration. It includes:
- Pipeline orchestration (Kubeflow Pipelines)
- Notebook environments (Jupyter)
- Model training (TFJob, PyTorch operators)
- Model serving (KFServing)
- Hyperparameter tuning
Kubeflow’s strength is its tight Kubernetes integration,
Experiments & Tracking
Basically to make it reproducible we need 3 things:
- Input data
- Training data
- Hyper parameters
WanDB (Wights & Biases)
MLFlow
Feature Store
Development/Tooling
- https://github.com/simonw/ttok
- CLI for embeddings and text classification/Clustering: https://github.com/taylorai/aiq
- Compression: https://news.ycombinator.com/item?id=42517035
- Prototyping
- emacs integration: gptel: a simple LLM client for Emacs | Hacker News
- ML in Go with a Python sidecar - Eli Bendersky’s website
- Price calculator: https://tools.simonwillison.net/llm-prices
- https://huggingface.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
- https://artefact2.github.io/llm-sampling/
- FE: https://github.com/SillyTavern/SillyTavern
- Benchmarks