tags : Modern AI Stack , Machine Learning, StableDiffusion, Deploying ML applications (applied ML)
FAQ
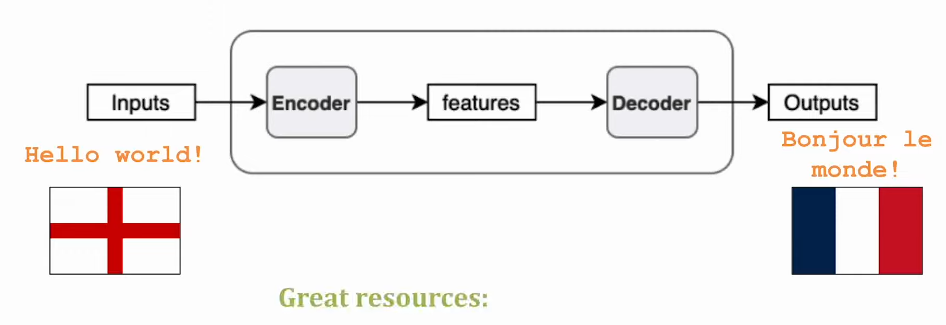
What attention?
- In each layer of the network
- Encoders taking words from an input sentence, converting them into a representation
- Each decoder takes all the encoders’ representation of words and transforms them into words in another language.
- Decoders getting all the encoders’ output provides a wider context and enables Attention.
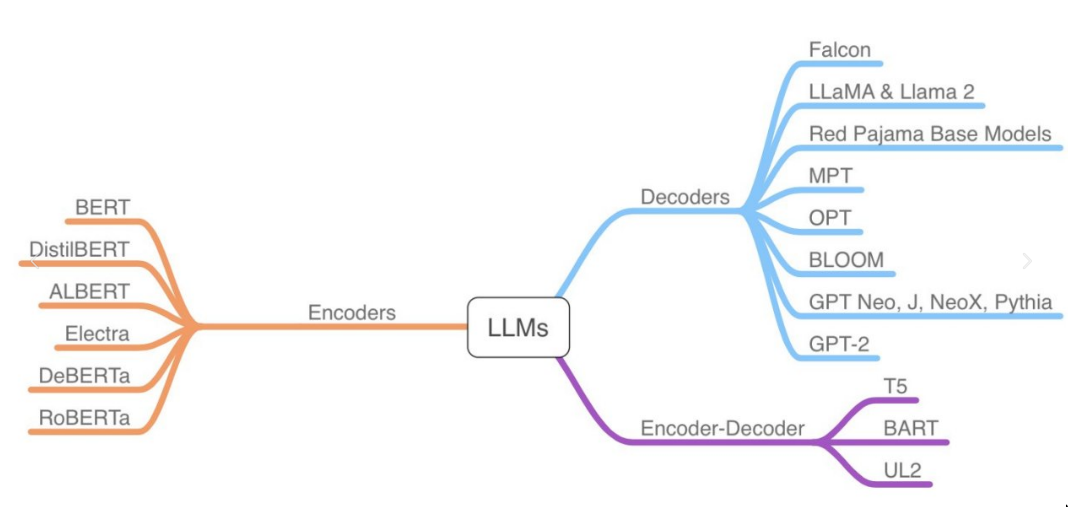
History/Lineage of LLMs?

Security
Concepts
Fundamentals
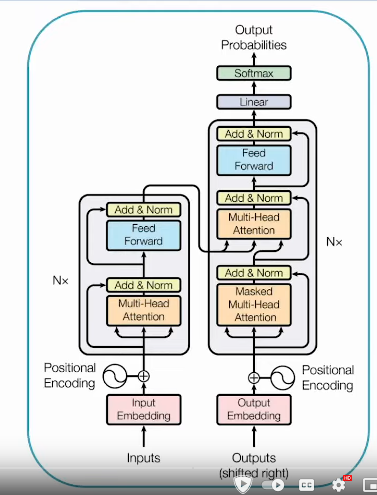
What are Large Language Models (LLMs)?
- Brief Overview: Transformers architecture, scale, emergent abilities
- How they work (predicting next token)
Key Concepts
- Tokens: The basic units of text processing
- Context Window: The amount of text the model can consider
- Temperature: Controls randomness/creativity in output
- Top-p / Top-k Sampling: Alternative methods for controlling output diversity
- Embeddings: Numerical representations of text for semantic understanding (brief intro)
Interaction Patterns
Message Types
- messages are just conventions, but these conventions matter from provider to provider and hence, there’s no universal API yet. and probably wont be in immediate future. So we’ll have to settle with a finite set of “model types”. Also providers have provider specific options which needs individual catering
- Messages are sometimes multiple parts (items in a list)
system: sets behavior or context (“You are a helpful assistant.”)user: input from the humanassistant: previous responses from the model (helps the model maintain context) (tool calling(aka function calling) instructions can go here)tool:- List of tools (description, parameters etc.)
- Different LLM providers provide tool calling differently.
tool_result: This either goes as user message or via a different param based on what the LLM provider expects.
Prompting
-
Basics
-
zero-shot/one-zero/few-shot learning?
-
Full Training
- What it is: Training the entire model on the complete dataset.
- Context: Standard machine learning approach, not specific to prompting pre-trained models. Baseline for comparison.
- Not “Shot” Learning: This term doesn’t apply; “shot” refers to providing examples at inference time to a pre-trained model.
-
Zero-Shot Learning (Using Pre-trained Models)
- What it is: Asking the model to perform a task using only instructions, without any concrete examples in the prompt.
- Mechanism: Relies entirely on the model’s pre-trained knowledge and its ability to understand/follow natural language instructions (often learned during instruction fine-tuning).
- Example:
Classify the sentiment of the following review: 'This movie was fantastic!'
-
One-Shot Learning (Using Pre-trained Models)
- What it is: Providing the model with exactly one example of the task within the prompt.
- Ambiguity: The way the example is provided matters (see distinction below).
-
Few-Shot Learning (Using Pre-trained Models)
- What it is: Providing the model with multiple (typically 2 or more) examples of the task within the prompt.
- Ambiguity: Similar to one-shot, the method of providing examples is key (see distinction below).
-
The Nuance: One-Shot vs. Few-Shot (Based on Example Presentation)
-
Examples Embedded in Instructions
(Often Labeled “One-Shot” or simple “Instruction Following” in this view)
- Description: Examples are written directly into the natural language instructions.
- Example:
Help me perform sentiment analysis on some reviews. Here are a few examples: "This movie rocks!" - Positive "This movie sucks!" - Negative "The movie was meh" - Neutral Now classify this review: 'I loved the acting.' - Mechanism Relied Upon: Primarily leverages the model’s ability to follow instructions, learned during fine-tuning (instruction tuning). It tries to extract the pattern from the text description.
- Potential Weakness (according to this view): May not strongly engage the model’s core pattern-matching (in-context learning) ability; effectiveness depends heavily on fine-tuning quality for parsing examples from instructions. The user notes suggest not calling this “few-shot” in the strict sense.
-
Structured Input/Output Patterns
(Considered “True” Few-Shot in this view)
- Description: Examples are provided as distinct input/output pairs, often mimicking a conversational flow or a structured data format.
- Example (using conversational format):
[ {'role':'system', 'content':'Perform sentiment analysis.'}, // System prompt often optional here {'role':'user', 'content':'This movie rocks!'}, {'role':'assistant', 'content':'Positive'}, {'role':'user', 'content':'This movie sucks!'}, {'role':'assistant', 'content':'Negative'}, {'role':'user', 'content':'This movie is meh'}, {'role':'assistant', 'content':'Neutral'}, {'role':'user', 'content':'I loved the acting.'} // The actual query ] - Mechanism Relied Upon: Directly targets the model’s in-context learning ability, an emergent property developed during pre-training. The model recognizes and continues the pattern.
- Strength (according to this view): Often more powerful because it taps into a fundamental capability of LLMs. The pattern itself acts as a strong instruction, potentially overriding explicit instructions. Seen as more indicative of the base model’s capabilities.
-
-
-
Foundational Techniques
- Instruction Following: Clearly stating the desired task
- Role Prompting: Assigning a persona (e.g., “You are a helpful assistant…“)
-
-
Techniques
-
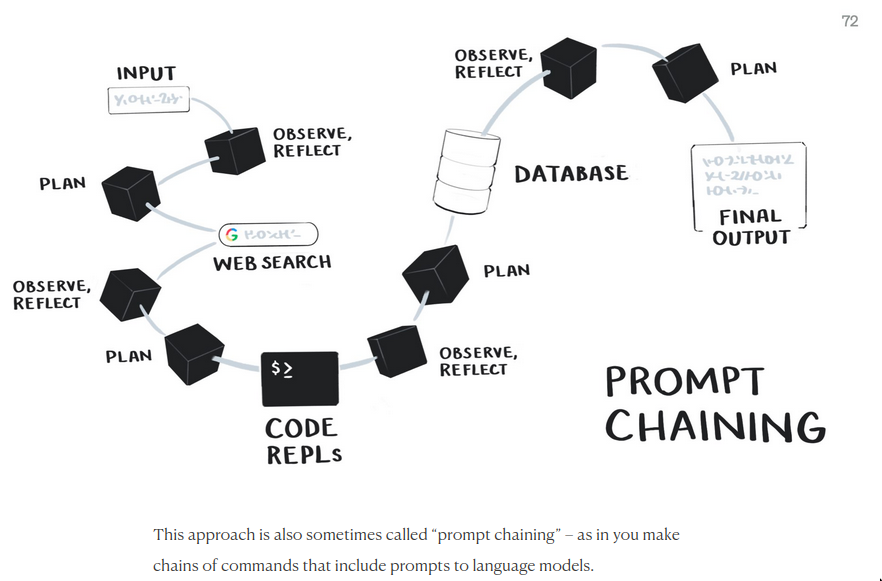
Prompt chaining / Decomposition
Breaking complex tasks into smaller, sequential prompts
- Making language models compositional and treating them as tiny reasoning engines, rather than sources of truth.
- Combines language models with other tools like web search, traditional programming functions, and pulling information from databases. This helps make up for the weaknesses of the language model.
- Source: Squish Meets Structure: Designing with Language Models

-
Chain of thoughts
Encouraging step-by-step reasoning (e.g., “Let’s think step by step”)
Chain of Thought prompting is exceptionally powerful if you need a structured response. I can give 2 examples from my own use.
- I was trying to summarize, for fun, the entire story of Final Fantasy XIV into json documents that I could then have a small program RAG against. That was going to get tiring really fast, so I did two CoT examples and then gave it a big chunk of story. I produced the JSON perfectly. That was Nous-Capybara-34b
- Im working on a project where I need a 1 word answer to something. I give it a block of text, I get 1 word back. Of course, models love to NOT do that, and instead talk your ear off. But with CoT, you can give 3 or 4 examples of giving it text and then getting 1 word back, and boom- you get 1 word back. When you’re writing code dependent on that result, it’s SUPER useful.
-
Self-Consistency
Generating multiple reasoning paths and taking the majority answer
-
Tree-of-Thoughts (ToT) / Graph-of-Thoughts (GoT)
Exploring multiple reasoning paths systematically (more complex/research-oriented)
-
ReAct (Reason + Act)
Combining reasoning with tool use/action-taking steps
-
-
Programmatic Prompting & Optimization Frameworks
-
ell.so
-
DSPy
DSPy is task independent, infact task-adaptive.
-
The idea
- You can do things like: “I want a chain of thought model which has “this” signature”, and then use that in your application code as if it was a function.
- With the DSPy, the focus is on finding the right primitive, the right modules.
-
Analogy w NN
- Suppose you want to solve a problem with NN + BERT, you have these 2 different components.
- But for something very specific, you’d want a specific layer from that NN and not the entire NN
- Analogous to that, modules in DSPy is that layer that can be picked individually. Eg. CoT is a module.
-
How CoT works with DSPy?
DSPy’s Chain of Thought feature automatically teaches language models to break down complex reasoning tasks by:
- Internally generating few-shot examples that demonstrate step-by-step thinking for your specific task
- Using these examples either through few-shot prompting or fine-tuning
- Handling all this automatically within DSPy’s programming model
This differs from simply adding “let’s think step by step” to prompts - instead, it’s a systematic way to teach models how to approach your particular problem through demonstration.
-
Iterative Development
The key concept is that DSpy development is iterative. Here’s how it works:
- Start by building your initial DSpy program and testing it with prompts.
- When you encounter issues (like cost concerns or consistent errors), DSpy gives you clear options to iterate:
- If the program works but is too expensive, you can tune the parameters
- If it’s making consistent mistakes, you can either:
- Add exception handling in your DSpy code for those edge cases
- Switch to a more resilient DSpy module
- Modify your DSpy metrics to catch and optimize away those specific errors
- DSpy’s framework gives you these well-defined paths for improvement, rather than expecting perfect performance on the first attempt.
The power of DSpy is that it provides these structured ways to iterate and improve your language model programs over time, making the development process more systematic and manageable.
-
Fine Tuning
- DSPy also does fine tuning, I am not sure exactly how but it’s a better approach than blindly finetuning according to Omar.
-
Modules
- There are builtin modules(eg. CoT) and new modules can be added easily
- Modules take in
signaturesignature= specification ofinput&outputbehavior.signature= a very simple prompt (5-6 words, not long prompts).- Eg. “input:long document output:summary”, “input:english text output:german translation”
- The types of
input&outputare specified in natural language.
- Once you give the module the
signature, it’ll give back a function that you can call.
-
Optimizer
https://dspy.ai/learn/optimization/optimizers/
- Once DSPy has you I/O, it’ll try to get to the desired result using an optimizer.
- This optimizes the prompt, LM weights etc.
-
Compiling
- Needs
data/promptsfor the various modules & a specificLLM - Eg. The same DSPy program could be a zero-shot prompt to
gpt4and a few-shot prompt to sayllama3. This also has a cost aspect to it, you could possibly achieve the similar results from both the models because you’ve defined input/output/constraints and it’ll try to fit things into it. - Whether you use fine-tuning or prompting when you use DSPy is not usually relevant, because the compiler will try to optimize for the input/output that was described in the
signatureanyway.
- Needs
-
-
Retrieval-Augmented Generation (RAG)
See RAG
TODO Fine-tuning: Adapting LLM Behavior
- When to Fine-tune (vs. Prompting/RAG)
- Need for specific style/tone adaptation
- Teaching complex, novel tasks not easily solved by prompting/RAG
- Improving performance on a narrow domain consistently
- Sometimes for optimizing cost/latency with smaller models
- Types of Fine-tuning
- Full Fine-tuning: Updating all model weights (resource-intensive)
- Parameter-Efficient Fine-Tuning (PEFT): Updating only a small subset of parameters
- LoRA (Low-Rank Adaptation) & QLoRA (Quantized LoRA)
- Process Overview
- Data Preparation: Creating high-quality instruction/response pairs
- Training Process: Running the fine-tuning job
- Evaluation: Assessing performance improvement
TODO Memory
Memory at first seems similar to RAG but it’s nuanced.
- https://mem0.ai/blog/memory-in-agents-what-why-and-how/?s=35
- https://x.com/jeffreyhuber/status/1912536156362928571
- https://arxiv.org/abs/2504.09283?s=35
Controlling and Enhancing Output
Achieving Structured Output
- Prompting for Format: Instructing the LLM to output in a specific structure (can be brittle)
- Model-Specific Features: Built-in modes (e.g., OpenAI JSON Mode, Gemini JSON mode)
- Grammar-Based Sampling / Constrained Decoding: Forcing the LLM’s output to conform to a specific grammar (e.g., JSON schema, regex)
- aka “Constrained Token Sampling”
- Libraries: Guidance, Outlines, LMQL, JSONformer/GBNF
- Structured Outputs by Example
- Every Way To Get Structured Output From LLMs
- The best library for structured LLM output – Paul Simmering
- Schema-Enforcing Libraries: Integrating with type hints or schemas (e.g., instructor)
Guard-rails and LLM Safety
- The Need for Safeguards
- Content Moderation: Preventing harmful, inappropriate, or toxic output
- Preventing Prompt Injection / Jailbreaking
- Enforcing Topic Adherence / Preventing off-topic responses
- Fact-Checking Hooks / Groundedness Enforcement
- Protecting Sensitive Data (Input/Output filtering)
- Approaches
- Rule-Based Filters: Simple Regular Expressions or keyword blocking
- Model-Based Moderation: Using another (often smaller) model to classify input/output
- Input/Output Parsing and Validation: Checking structure or constraints before/after LLM call
- Frameworks: arch-gw, guardrailsai etc.
Function calling & Agents
Defining functions/tools the LLM can choose to call with structured arguments
Agentic Workflows: LLMs as Reasoning Engines
See AI Agents
Standardized Integration Protocols/Function calling/Tool Calling/MCP
Tool Calling (also known as function calling) are programs that you can provide an LLM to extend its built-in functionality. This can be anything from calling an external API to calling functions within your UI.
-
Client tools
- Provide
toolmessages in the message api - Based on
tooldescription LLM will determine if it needs to call a tool - Then it’ll respond with
- function to call
- “values” of the parameters to use (schema, different sdk have different ways to define schema)
- The client program then uses those values to run the code
- Pass the returned values back to the LLM
- There are variants
- Multiple tool
- Parallel tool
- Sequential tool
-
How and Why the LLM will pick a tool?
- This is undeterministic. Some models will do correct tool use, in some models tool use can be improved via better prompting.
- Name and desciption of the tool should be in the model’s prespective
- Provide
-
Server tools
Backend automatically has predefined tooling, just use proper prompting. (eg. Claude Websearch)
-
MCP vs Tool/Func calling
- MCP is very much like function calling, but it’s different in terms of
- “where the functions are defined”
- “where the function is executed”
- fn def/execution location
- Tool calling: In the
client/agentcode directly. You have to define/import fn. - MCP: In a separate arguably re-usable server which the
client/agentconnects to
- Tool calling: In the
- This location of the fn, in-turn alters how the functions are being provided to the LLM.
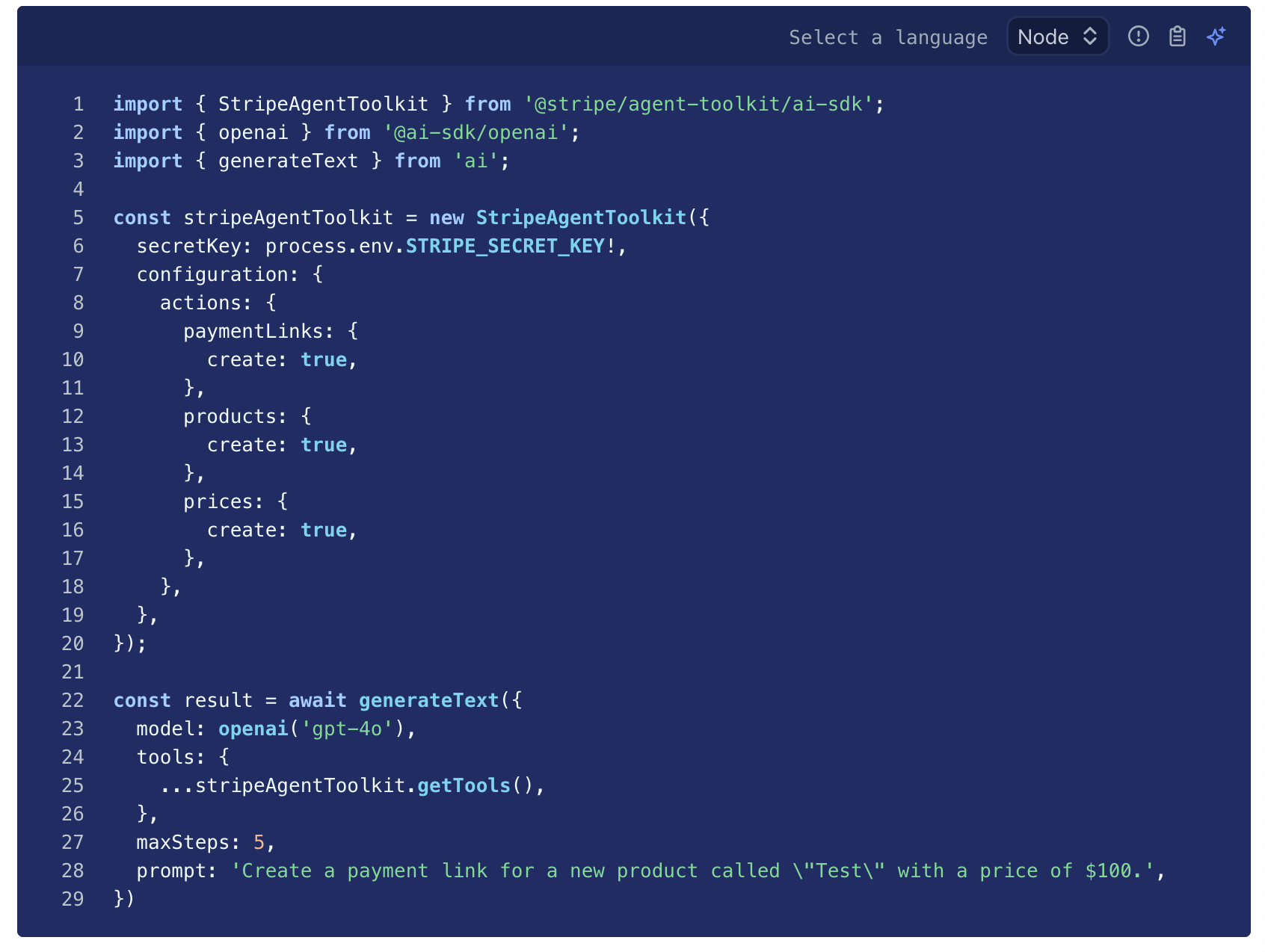 Toolcalling^
Toolcalling^
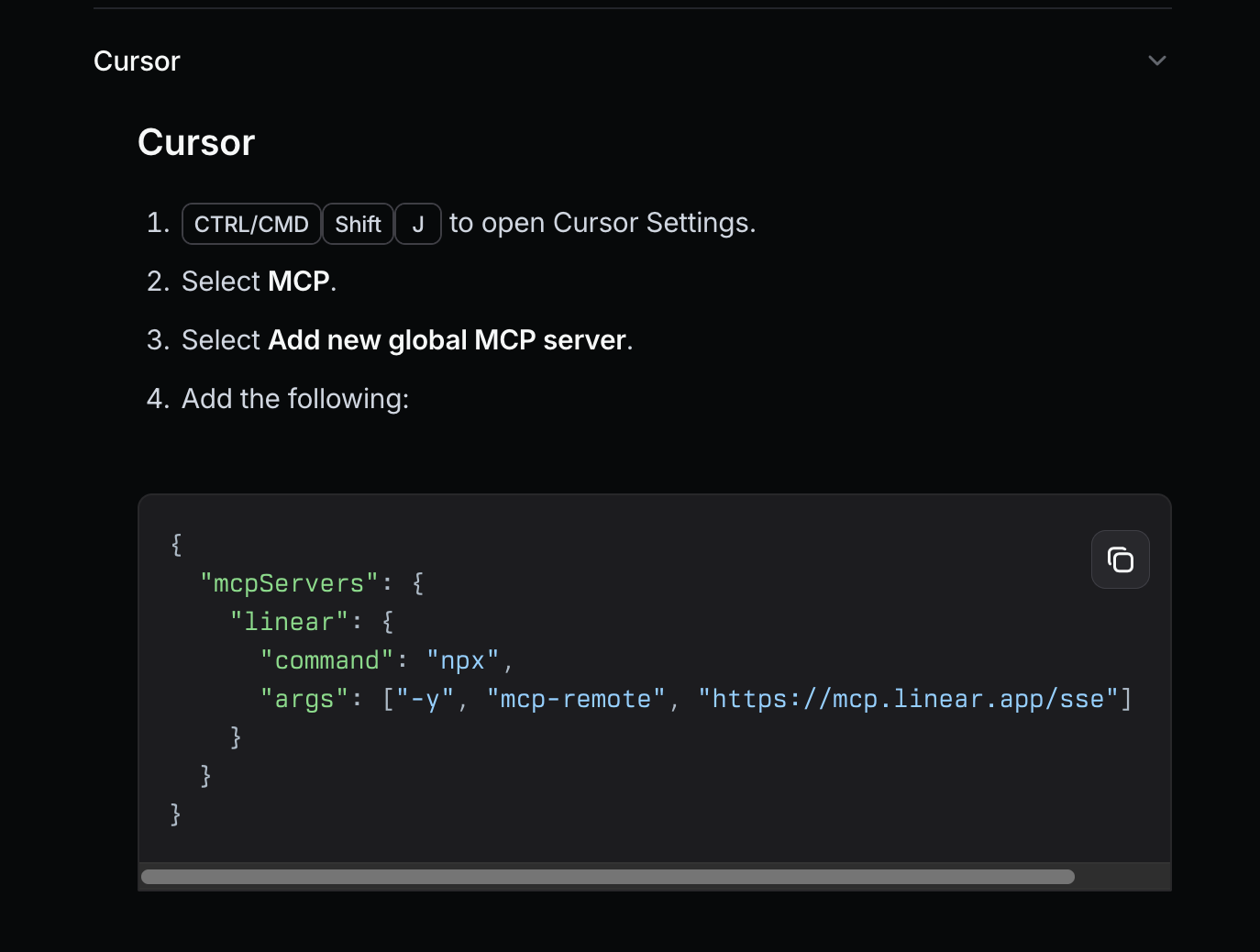 MCP^
MCP^ - MCP is very much like function calling, but it’s different in terms of
-
Tool calling vs Multi-Agent systems
- When doing toolcalling, you can already do multiple tool calls across multiple steps without you explicity specifying the order. This essentially means that’s sort of an agent.
- Multi-Agent systems are systems where we’re using different agents each specific of its usage together. (Eg. o3 agent for coding and then claude for summarizing it)
Building LLM Applications: Frameworks & Orchestration
Gateway
LLM Gateway to provide model access, fallback, retry, spending tracking etc
- https://www.litellm.ai/ (This has openrouter as a provider, it’s like kfc selling mcdonald burger types)
- https://portkey.ai/
- https://openrouter.ai/
Orchestration Frameworks: Simplifying Development
Langchain and friends fall here, but I personally don’t want to use any “dedicated” LLM framework. No silver bullets.
- Purpose: Provide building blocks and abstractions for common patterns
- Common Use Cases: Building RAG pipelines, multi-step chains, agentic systems
TODO Distribution
Evaluation & Monitoring
Why Evaluate LLM Systems?
- Assessing output quality and accuracy
- Comparing different models, prompts, or system configurations
- Regression testing during development
- Ensuring safety and alignment guidelines are met
Key Evaluation Metrics & Techniques
- Task-Specific Metrics: Accuracy, F1, Precision, Recall (for classification, extraction)
- Generation Metrics: BLEU, ROUGE (primarily for summarization/translation - use with caution)
- Semantic Similarity: Using embeddings to compare generated vs. reference answers
- LLM-as-Judge: Using a powerful LLM to evaluate the quality of another LLM’s output based on criteria
- RAG-Specific Metrics:
- Context Relevance/Precision: Are the retrieved chunks relevant to the query?
- Groundedness / Faithfulness / Attributability: Does the answer rely only on the provided context?
- Answer Relevance: Is the final answer relevant to the original query?
- Evaluation Frameworks & Tools: RAGAS, TruLens, DeepEval, LangSmith / LangFuse, PromptTools
Monitoring in Production
- Tracking Key Performance Indicators (KPIs): Latency, token usage, error rates
- Cost Monitoring & Management
- Output Quality Monitoring: Sampling outputs, automated checks, user feedback loops
- Drift Detection: Monitoring changes in model behavior or data distributions over time
Evaluation tools
Emerging Concepts & Future Directions
Multimodality: Beyond Text
- Models processing and generating images, audio, video (e.g., GPT-4V, Gemini)
Architectural Innovations
- Mixture-of-Experts (MoE): Sparsely activating parts of the model (e.g., Mixtral)
- State Space Models (SSMs): Alternative architectures (e.g., Mamba) potentially challenging Transformers
Efficiency & Context Length
- Techniques for handling very long context windows efficiently (e.g., Ring Attention)
- Continued focus on reducing inference cost and latency
Alignment & Safety Research
- Ongoing efforts to make LLMs more helpful, honest, and harmless
- Advanced techniques for controlling behavior and preventing misuse
Hybrid Approaches
- Combining strengths of different models (e.g., router selecting specialized models)
- Integrating LLMs with symbolic reasoning systems or knowledge graphs
Explainability & Interpretability (XAI)
- Challenges and ongoing research in understanding why LLMs generate specific outputs
Others
Documentation/Instructions for AI
TODO LLM Evaluation
Longform QA
If you were building a Q&A feature (or chatbot) based on very long documents (like books), what evals would you focus on?
- Two metrics that come to mind
• Faithfulness: Grounding of answers in document’s content. Not to be confused with correctness—an answer can be correct (based on updated information) but not faithful to the document. Sub-metric: Precision of citations • Helpfulness: Usefulness (directly addresses the question with enough detail and explanation) and completeness (does not omit important details); an answer can be faithful but not helpful if too brief or doesn’t answer the question • Evaluate separately: Faithfulness = binary label -> LLM-evaluator; Helpfulness = pairwise comparisons -> reward model
- How to build robust evals
• Use LLMs to generate questions from the text • Evals should evaluate positional robustness (i.e., have questions at the beginning, middle, and end of text)
- Potential challenges
• Open-ended questions may have no single correct answer, making reference-based evals trickly. For example: What is the theme of this novel? • Questions should be representative of prod traffic, with a mix of factual, inferential, summarization, definitional questions
- Benchmark Datasets:
• NarrativeQA: Questions based on entire movie scripts or novels. Includes reference answers useful for LLM-eval comparisons • NovelQA: Q&A over full novels; includes both MCQ and free-form responses, and includes references • Qasper: Similar to NarrativeQA, but with academic documents that are 5-10k tokens, and includes evaluation of answer spans • LongBench: Average of 6.7k words across fiction and technical docs • LongBench v2: Extension of LongBench, but evals are MCQ only • L-Eval: 20 tasks and >500 long documents (up to 200k tokens), with several QA-oriented tasks • HELMET: Includes reference-based evaluation for long-context QA, and includes measures for positional robustness • MultiDoc2Dial: Modeling dialogues grounded in multiple documents. Evaluates ability to integrate info over multiple docs • Frustratingly Hard Evidence Retrieval for QA Over Books: Reframed NarrativeQA as open-domain task where book text must be retrieved
https://www.amazon.science/blog/new-tool-dataset-help-detect-hallucinations-in-large-language-models https://www.amazon.science/publications/hallumeasure-fine-grained-hallucination-measurement-using-chain-of-thought-reasoning https://github.com/amazon-science/RefChecker
LLM Traning / Fine tuning
Chat bot training
Useful links
-
Existing SAAS
Background
-
Defining problem
- Before starting, make sure that the problem that needs to be solved and the expectations are fully defined. “Teaching the model about xyz” is not a problem, it is a wish. It is hard to solve “wishes”, but we can solve problems. For example: “I want to ask the model about xyz and get accurate answers based on abc data”. This is needed to offer non stop answering chat for customers. We expect customer to ask “example1, 2, 3, .. 10” and we expect the answers to be in this style “example answers with example addressation, formal, informal, etc). We do not want the chat to engage in topics not related to xyz. If customer engage in such topics, politely explain that have no knowledge on that. (with example). This is a better description of the problem.
- It is important to define what is the expected way to interact with the model. Do you want to chat with it? Should it follow instructions? Do you want to provide a context and get output in the provided context? Do you want to complete your writing (like Github Copilot or Starcoder)? Do you want to perform specific tasks (eg grammar checking, translation, classification of something etc)?
-
Dataset preparation
Description Example enriching data with context or system prompts databricks/databricks-dolly-15k can significantly improve the final model’s quality. Open-Orca/OpenOrca chains of multi-step Q&A with solid results. (CoT + few shot) cognitivecomputations/wizard_vicuna_70k_unfiltered Fredithefish/ShareGPT-Unfiltered-RedPajama-Chat-format a dataset for quotes is much simpler, because there will be no actual interaction, the quote is a quote. In this case, we want the bot to answer things like: "Who wrote this quote: [famous quote content]?"Abirate/english_quotes the instruction, input(optional), outputformatyahma/alpaca-cleaned · Datasets at Hugging Face Hugginface format HuggingFaceH4/no_robots - Automated tools can only do so much; manual work is indispensable and in many cases, difficult to outsource. Those who genuinely understand the product/process/business should scrutinize and cleanse the data. Even if the data is top-notch and GPT4 does a flawless job, the training could still fail. For instance, outdated information or contradictory responses can lead to poor results.
- Involve a significant portion of the organization in the process. I develop a simple internal tool allowing individuals to review rows of training data and swiftly edit the output or flag the entire row as invalid.
-
Useful links
- https://platform.openai.com/docs/guides/fine-tuning/preparing-your-dataset#crafting-prompts
- https://distilabel.argilla.io/latest/ (Synthetic Datasets)
- https://github.com/mlabonne/llm-datasets (Catalog of LLM Datasets)
-
fine tuning dataset formats
- Shaping your data in the correct format is usually the most difficult and time-consuming step
- Most models are trained on a particular format, but you can often reformat a dataset to fit another format. This impacts the end user results. See this post by HF for more info. However, community is steering more standardization of the format. (so matching the format used during training is extremely important)
- If training on base model, the format depends on how do you want to use the chatbot (chatbot/instruct bot/completion bot etc). But if you’re doing LoRA also depends what the pre-trained model is trained on. In other words, It’s important to note that a base model could be fine-tuned on different chat templates, but when we’re using an instruct model we need to make sure we’re using the correct chat template that was used to create the instruct model from the base model.
-
Training
-
pre-training
See https://x.com/nrehiew_/status/1872318161883959485 (Deepseek technical report)
Goal: to recognize and follow arbitrary text, rich with meaning, intent, style, and structural features.
- pre-training requires LLMs to generate contextually coherent text completions across diverse documents. This teaches the model basic language proficiency to do it.
- The process involves sophisticated, nuanced pattern recognition at an advanced level.
- The primary pre-training techniques include Masked Language Modeling (MLM), where random words are masked and the model must predict them, and Next Sentence Prediction (NSP), which involves predicting the subsequent sentence in a given context.
- If you have a vast amount of data, i.e., tens of thousands of instructions, it’s best to fine-tune the actual model.
This pre-training can be followed by RLHF, instruction tuning etc.
-
post-training
Goal: Task specific training
Useful for adapting the model for a certain style, get the model more into something etc.
Some fine-tunes are
- full fine tunes which basically aim to replace all the original weights.
- LoRAs
-
Useful links
-
fine tuning tools
Tool Description Other notes HF Autotrain Advanced for finetune HF TLR for rlhf, improve by RL (the same way gpt did it) Uses unsloth, contains SFTTrainerh2oai finetune script ligpt unsloth fasterst axolotl torchtune PyTorch native post-training library, see usage Post-training llama-factory GUI, uses hf/unsloth under the hood instructor-embedding finetuning with embeddings -
More on SFTTrainer
https://gist.github.com/geekodour/989ded9c69e89f6738dc38d21f8057ae (this script is configurable via yaml)
The SFTTrainer is a subclass of the Trainer from the transformers library and supports all the same features, including logging, evaluation, and checkpointing, but adds additiional quality of life features, including:
- Dataset formatting, including conversational and instruction format
- Training on completions only, ignoring prompts
- Packing datasets for more efficient training
- PEFT (parameter-efficient fine-tuning) support including Q-LoRA, or Spectrum
- Preparing the model and tokenizer for conversational fine-tuning (e.g. adding special tokens)
- distributed training with accelerate and FSDP/DeepSpeed
This SFTTrainer scripts works at a lower level than something like axolotl giving more visibility&flexibility, but we could use that aswell.
-
-
It’s experimental
fine-tuned model’s performance isn’t necessarily indicative of the base model’s capabilities” (but fewshot is indicative!)
Getting a good LoRA is a trial and error process
Sometimes less is more
- In the case of 70b fine-tunes who can take a small suggestion of instruction-following and “wing it” impressively due to their superior ability to recognize fine details of the context.
- Also you can be very clever about reinforcing specific behaviors, such as “step by step thinking,” and get a very proficient chatbot who eventually falters on moderately complex instructions, like Mistral 7b.
-
Tuning hyperparameters
- Tuning hyperparameters is pretty overrated once you have a solid baseline. once you find hyperparams that perform well you don’t need to adjust much and many can be left as default, just do a quick sweep of learning rate + num epochs and you can basically use that forever unless metrics really start to drop off.
- When we do quantaization, we’d also want to do evals. So that quality is maintained.
-
Hardware
- fine tune a 12b model using LoRA for 10 epochs within 20 mins on 8 x A100 with h2o scipt, the but with HF’s SFT it takes almost a day.
- Lora and 8bit quantisation for all the training (3 epoch), batchsize, seq_length
- Based on the the way you tune, the final model may take different vram etc. eg. unsloth is more optimized than hf
- LoRA or qLoRA : When working w a smaller dataset
- Can happen on a cloud A6000 with 48GB VRAM, which costs about 80 cents per hour.
- Anything larger than a 13B model, whether it’s LoRA or full fine-tuning, I’d recommend using A100.
- A100 is OK, H100 is better but the hassle of adapting the tools can be overwhelming
- fine tune a 12b model using LoRA for 10 epochs within 20 mins on 8 x A100 with h2o scipt, the but with HF’s SFT it takes almost a day.
-
-
Retrieval
See RAG
-
Prompting
-
one-shot vs few-shot
It’s somewhat vague what is called one-shot and what is called few-shot. OpenAI pushed the terminology to say “few-shot” when you provide “examples in instructions”, as it’s not taking advantage of in-context task learning, it’s relying on facets of the fine-tuned task. If we want our llm to follow examples, we want to go with few shot learning.
-
one shot
Help me perform sentiment analysis on some reviews. Here are a few examples: "This movie rocks!" - Positive "This movie sucks!" - Negative "The movie was meh" - NeutralThis relies on the instruct training, and assumes the fine-tuning taught it well how to fish examples out of instructions. It may leverage some of the in-context learning ability to some extent, while also working against it.
This example should NOT be called few-shots. This is just following instructions, which might not be strong. The llm might not know how to follow your instruction with examples.
-
few shot
[ {'role':'system', 'content':'Help me perform sentiment analysis on some reviews'}, {'role':'user', 'content':'This movie rocks!'}, {'role':'assistant', 'content':'Positive'}, {'role':'user', 'content':'This movie sucks!'}, {'role':'assistant', 'content':'Negative'}, {'role':'user', 'content':'This movie is meh'}, {'role':'assistant', 'content':'Neutral'} ]This is few-shot, it follows a pattern, and targets
in-context learningwhich is something LLMs learn inpre-training.- In this example, we have a system instruction prompt, we don’t even need that. We will find that we can remove that instruction. Because rest of the prompt are actual instructions and it follows a pattern. It is strong. So strong that there’s really no point in putting instructions (like your system prompt) as the strong pattern-following will just overpower them.
- One can frame nearly arbitrary problems as documents that follow a simple pattern of input/output pairs. That’s the basis of “few-shot” prompting.
- Good thing about few-shots is that it’s indicative of the base model’s capabilities.
-
-
Our process
- Fine Tuning: For style
- Fine Tuning + prompt : For QA
- Fine Tuning + Few Shots + prompt: For
- Fine Tuning + Few Shots + RAG : For retrieval
Font Loading / Index Building
method for data augmentation / index building
- Instead of running slow and expensive LLMs at query time, you run them at index time.
- See https://github.com/xlang-ai/instructor-embedding for it does something very similar
- Basically, you use LLMs to add context to chunks that doesn’t exist on either
- the word level (searchable by BM25)
- the semantic level (searchable by embeddings)
- Basically, you know your usecase and access patterns in advance and then you add the “handle” using natural language. This “handle” can be time frames, objects, styles, emotions whatever.
- Sometimes this is all you need and not some complicated GraphRAG framework.
- Usually these GraphRAG framework would add garbage which later affects the search instead of helping.
- These graphRAG systems are built to cover a broad range of applications and are not adapted at all to your problem domain.
How to go about it?
Prefer working backwards
- What kinds of queries do I need to handle?
- What does the prompt to my query time LLM need to look like?
- What context will the LLM need?
- How can I have this context for each of my chunks, and be able to search by match air similarity?
- How can I make an LLM return exactly that kind of context, with as few hallucinations and as little filler as possible, for each of my chunks?
This gives you a very lean, very efficient index that can do everything you want.
More on LoRA
Basics
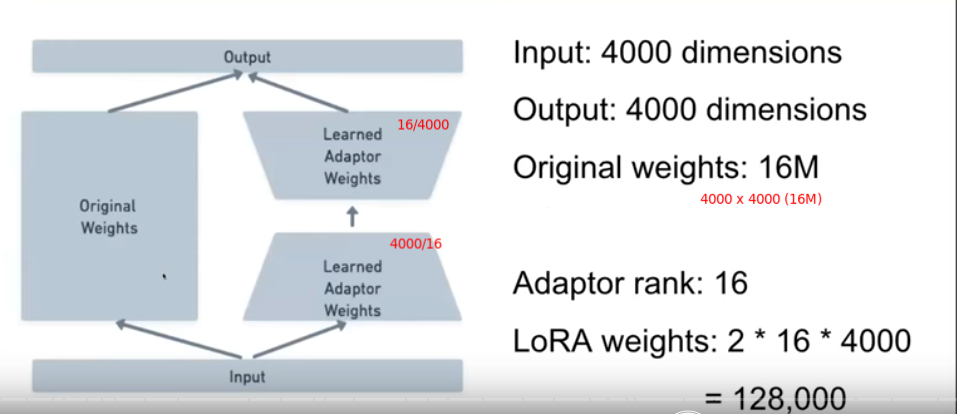
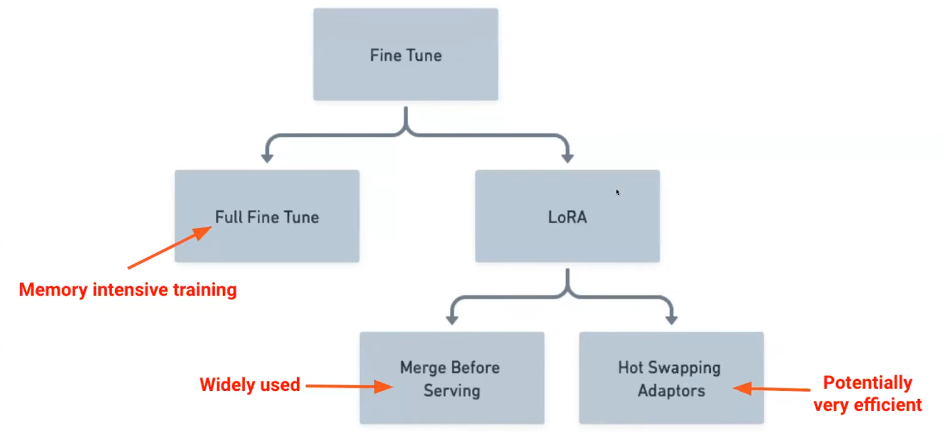
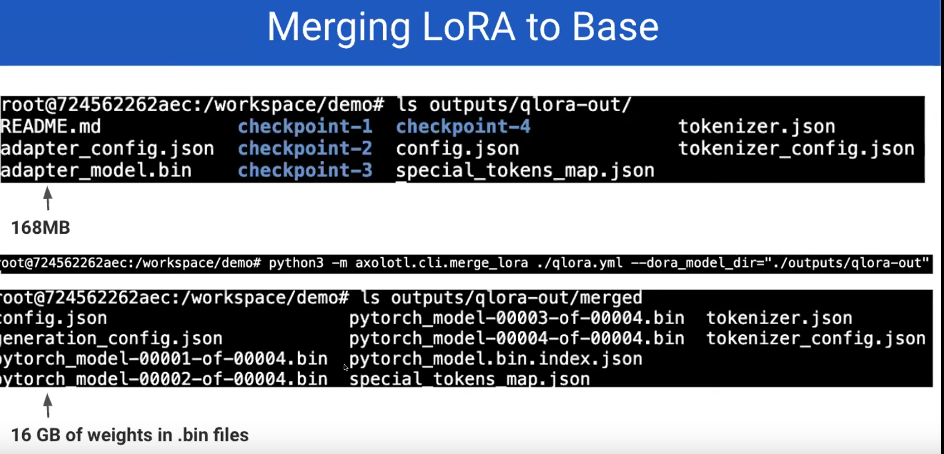
Cost tradeoff

- Sometimes loading the model into GPU itself takes a while, but you’ll be charged for that so in that case is scale to 0 worth it? these kind of tradeoffs.
TODO Ecosystem Tooling
OSS Model Comparison
These are mostly obsolete now. Better consult SOTA benchmarks.
- Airtable link: MLModels Airtable
- All links: https://github.com/imaurer/awesome-decentralized-llm
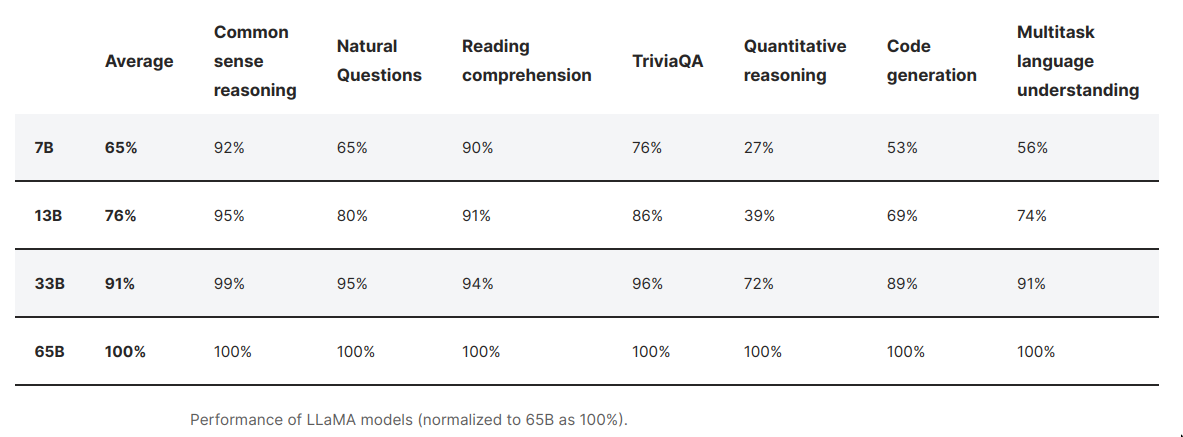
LLaMA
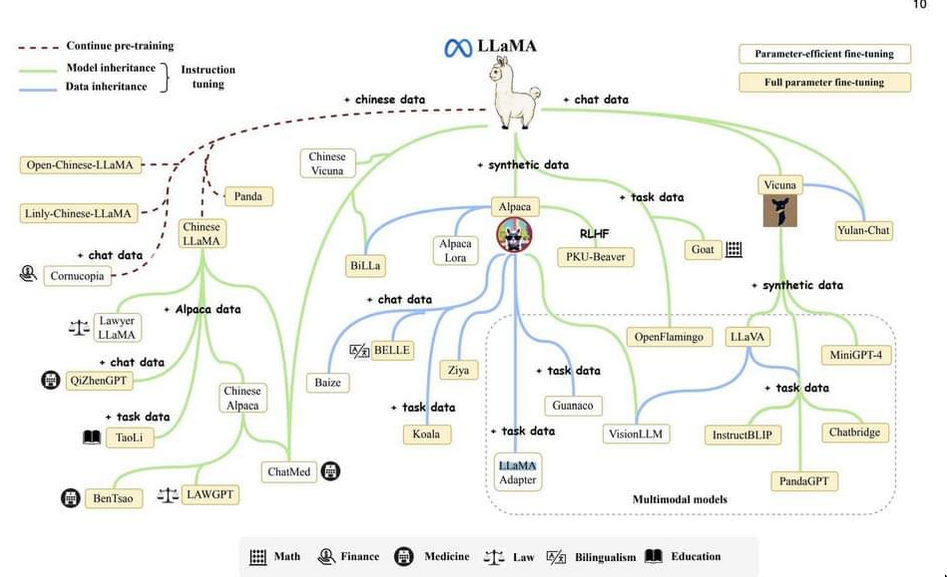
- LLaMA is not tuned for instruction following like ChatGPT
- llma.cpp story : What is the meaning of hacked? · Issue #33 · ggerganov/llama.cpp · GitHub
Alpaca
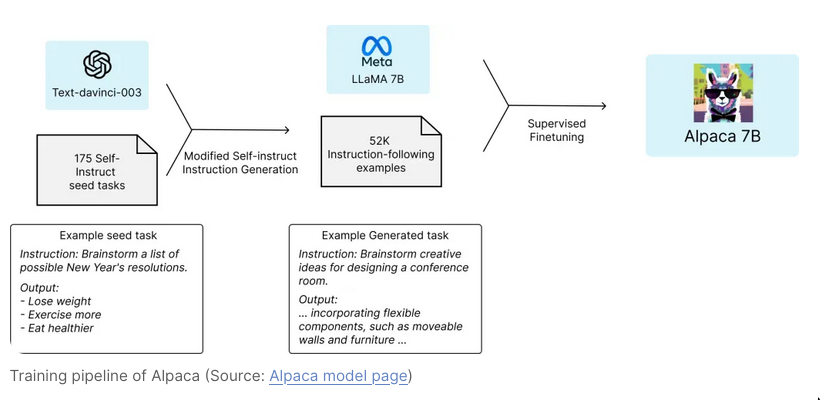
- What’s Alpaca-LoRA ? Technique used to finetune llama using lora
Guanaco 7B (llma.cpp)
- CPU
- 1 Thread, CPU: 0.17-0.26 tokens/s
- 11 Threads, 12vCPU: ~1token/s
- 21 Threads, 12vCPU: ~0.3token/s
- 10 Threads, 12vCPU: ~0.3token/s
- 1 Thread, CPU, cuBALS: 0.17-0.26 tokens/s
- 9 Thread, CPU, cuBALS: 5 tokens/s
- GPTQ (GPU)
- ~25token/s