tags : Machine Learning, Data Engineering, Open Source LLMs, Information Retrieval, Knowledge
NLP Tasks
| Task | Description |
|---|---|
| Document classification | Supervised learning, Assigns documents to known categories |
| Clustering | Unsupervised learning, Groups similar documents together based on patterns, Discovers natural groupings in data |
| Sentiment Analysis |
More on document classification vs clustering
| Clustering | Document Classification | |
|---|---|---|
| Usecase | organize articles, customer segmentation on feedback | spam detection, sentiment analysis, |
| themes in social media | topic categorization, language identification | |
| Evaluation | Silhouette score, Davies-Bouldin index | Accuracy, Precision, Recall, F1-score, Confusion matrix |
| Inertia, Inter/intra cluster distance | ||
| Algorithms | K-means, Hierarchical clustering, DBSCAN, Mean-shift | Naive Bayes, Support Vector Machines, Random Forest, Neural Networks |
Flow
- Clustering:
- Raw Documents → Feature Extraction → Clustering Algorithm → Document Groups (K-means, hierarchical)
- Classification:
- Training: Labeled Documents → Feature Extraction → Train Classifier → Model
- Testing: New Document → Feature Extraction → Trained Model → Predicted Label
Sentiment Analysis
Averaging out sentiments may be erroneous. The important aspect is to look at totality of sentiments, degree of sentiments and also mixed sentiment. Here are two examples -
eg1. Your product is bad (moderate degree)
Your product is very bad (higher degree of bad)
Your product is terrible (highest degree of bad)
eg2. Your product is great but support is terrible.
another one
> (sentiment analysis) on news articles, should I do it sentence by sentence?
No.
Sentiment in one sentence often depends much on the context from the other sentences.
I think you’d be better off breaking it up into overlapping chunks. Perhaps for each sentence include both the preceding two sentences and the following sentence.
> news articles
That makes it even harder.
Often news articles have the patterns
- Things were going wonderfully well, until they turned out horribly bad. Or
- Things were going badly, but then they ended up mostly OK (which is happy considering the circumstances, but would otherwise be sad).
The approach of averaging sentences will miss the main idea in both of those scenarios.
Instead of averaging them, you might be better off looking for trends of which direction the sentiment was heading from beginning to end.
Consider a news article with sentences like
- “She was a straight A student in high school.” [positive sentiment]
- ”…[a couple more background paragraphs]…”
- “Her kidnappers tortured her for 6 months.” [whoa - very negative]
- ”…[a couple more recent paragraphs]…”
- “She took his gun and shot him and fled.” [tough for BERT to guess unless it has context]
Unless BERT knows to value the life of the victim more than the suspect, and has the context of who was who, it’ll do extremely poorly.
History of NLP

- We did have attention when we were using DNN
- But with the 2017 paper, we suggested that “attention is all you need”, aka Transformers.
- AllenNLP - Demo
General ideas in NLP
Tokenization
Byte Latent Transformer: Patches Scale Better Than Tokens | Hacker News (possible future of tokenization)
What?
Tokenization is string manipulation. It is basically a for loop over a string with a bunch of if-else conditions and dictionary lookups. There is no way this could speed up using a GPU. Basically, the only thing a GPU can do is tensor multiplication and addition. Only problems that can be formulated using tensor operations can be accelerated using a GPU.
The default tokenizers in Huggingface Transformers are implemented in Python. There is a faster version that is implemented in Rust.
Sub word
- See GitHub - google/sentencepiece
- You could have designed state of the art positional encoding | Hacker News
- Uses
byte-pair encoding(BPE)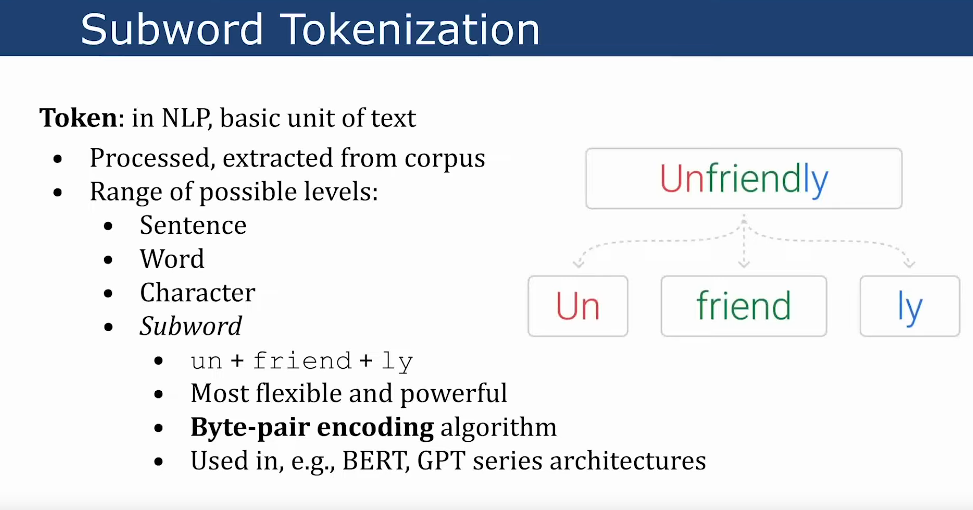
Token count
- Large language models such as GPT-3/4, LLaMA and PaLM work in terms of tokens.
- 32k tokens ~ 25k words ~ 100 single spaced pages
- See Understanding GPT tokenizers
Embeddings vs Tokens
- See Embeddings
- The Illustrated Word2vec - A Gentle Intro to Word Embeddings in Machine Learning - YouTube
- Tokens
- These are inputs
- The basic units of text that the language model operates on
- “I love cats” would be tokens: [“I”, “love”, “cats”] if using word level tokenization.
- Embeddings
- Embeddings are learned as part of the model training process.
- Refer to the vector representations of tokens in a continuous vector space.
- The model maps token to an embedding vector, representing semantic properties.
- As a result, two tokens with similar embeddings have similar meaning.
- Any deep learning model that uses tokens as input at some point is an embedding model.
TODO LIMA style training?
Old Age
New Age (post 2018 tech)

- Autoencoder LLMs are efficient for encoding (“understanding”) NL
- Autoregressive LLMs can encode and generate NL, but may be slower
Meta Ideas
encoder-only, encoder-decoder, decoder-only
There are mainly 3 overarching paradigms of model architectures in the past couple of years.
- encoder-only models (e.g., BERT)
- encoder-decoder models (e.g., T5)
- decoder-only models (e.g., GPT series).
- See What happened to BERT & T5? On Transformer Encoders, PrefixLM and Denoising Objectives — Yi Tay
unidirectional and bidirectional
LLMs like GPT4, Sonnet and RNNs etc. are usually unidirectional, bi-directional(Eg. BERT, MPNet) is useful for understanding vs generative.
-
Unidirectional (left-to-right) example
- Sentence: “The cat chased the mouse.”
- Word representation for “cat”
- Only considers the preceding context: “The”
-
Unidirectional (right-to-left) example
- Sentence: “The cat chased the mouse.”
- Word representation for “cat”
- Only considers the following context: “chased the mouse”
-
Bidirectional (BERT) example
- Sentence: “The cat chased the mouse.”
- Word representation for “cat”
- Considers the full context: “The cat chased the mouse”
-
Cross encoders
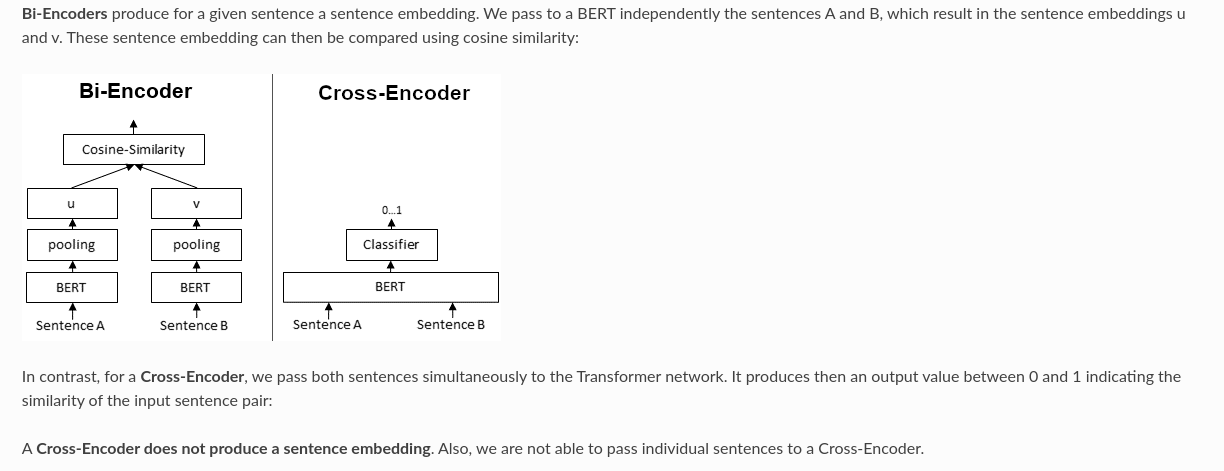
- Both bidirectional and cross encoders work with
sentence pairs - https://www.sbert.net/examples/applications/cross-encoder/README.html
- https://www.pinecone.io/learn/series/nlp/data-augmentation/
- Usecase
- Cross-Encoder achieve higher performance than Bi-Encoders, however, they do not scale well for large datasets.
- It can make sense to combine Cross- and Bi-Encoders
- Eg. Information Retrieval / Semantic Search scenarios
- First, you use an efficient Bi-Encoder to retrieve e.g. the top-100 most similar sentences for a query.
- Then, you use a Cross-Encoder to re-rank these 100 hits by computing the score for every (query, hit) combination.
- Both bidirectional and cross encoders work with
PLM (Permuted Language Model (PLM))
Key Characteristics of PLM:
- Considers multiple possible permutations of the input sequence during training
- Can see all unmasked tokens regardless of their positions
- Combines advantages of both:
- Masked Language Modeling (like BERT)
- Autoregressive Language Modeling (like GPT)
Eg.
Original Sequence: "The cat sat on the mat"
Possible Permutations:
[The] [cat] [sat] [on] [the] [mat]
[cat] [The] [on] [mat] [sat] [the]
[mat] [sat] [The] [cat] [on] [the]
... (other permutations)Used by MPNet
Semantic Search & Embeddings
- closest text or texts to a target sentence
- For Embeddings, we could use OpenAI embeddings but we could also use sentence-transformers. We can start with the following and move to OpenAI embeddings if not work.
- multi-qa-dot mpnet
- gtr-t5-large
- all-mpnet-base V2
- paraphrase-multilingual-mpnet-base V2
- “Your baseline for RAG apps should NOT be OpenAI embeddings. It should be ColBERT.” (
single vectorvsmulti-vector)
Massive Text Embedding Benchmark (MTEB) Leaderboard
- The MTEB leaderboard is also very helpful if you know how to use it. The basic way to look at it is : for all the datasets mentioned there in the benchmark, which one is the closest to the type of data you’re working with? Sort in order of performance of models for that dataset.
- https://huggingface.co/spaces/mteb/leaderboard
AutoEncoders (Understanding)
Usecase: semantic textual similarity (STS), Classification Also see Embeddings
Base Models
-
BERT (improves upon
transformers)- Original paper follows an encoder-decoder architecture.
- Source (by google team)
- https://www.cs.cmu.edu/~leili/course/dl23w/14-pretrained_langauge_models.pdf
- https://paperswithcode.com/method/bert
- https://huggingface.co/google-bert/bert-base-multilingual-cased
- https://pub.towardsai.net/understanding-bert-b69ce7ad03c1
- Multilang: https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages
-
Steps (2)
-
Step1: Pre-Training
The model learns an inner representation of the languages in the training set that can then be used to extract features useful for downstream tasks. This is trained on a large corpus of
unlabeled text data.This has 2 objectives
- MLM (Masked language model): taking a sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict the masked words
- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to predict if the two sentences were following each other or not.
- This helps the model learn the relationships between sentences, which is important for tasks like question answering and natural language inference.
-
Step2: Fine Tuning
- the BERT model is then fine-tuned on labeled data from specific downstream tasks. The pre-trained parameters are used as the starting point, and the model’s parameters are further adjusted to perform well on the target task.
- For different tasks, we’ll finetune separately.
-
-
Other notes
- Models like BERT have a data dependency on future time steps also, and this means you cannot Auto-Regress them.
- https://www.reddit.com/r/MachineLearning/comments/e71vyr/d_why_does_the_bert_paper_say_that_standard/
- BERT has a token capacity limit of 512 tokens. If you have longer than 512 you can break it up into chunks.
- variants
-
Learning resources
- Discussion on encoder-decoder: A BERT for laptops, from scratch | Hacker News
-
SBERT (sentence transformers)
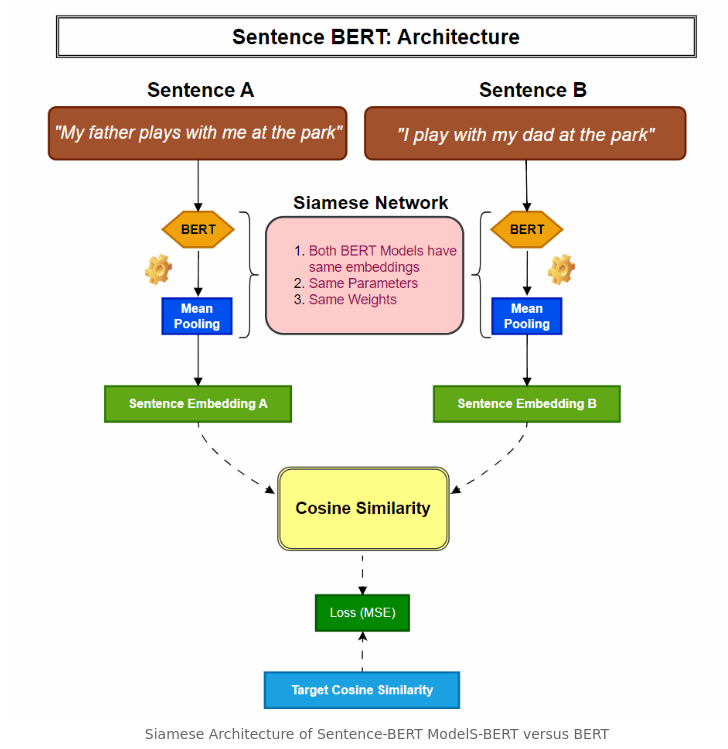
- Built on top of BERT or RoBERTa (Adds a pooling layer on top of BERT). i.e gives sentence level embeddings.
- in vanilla BERT, finding the most similar pair in a collection of 10,000 sentences requires about 50 million inference computations (~65 hours) with BERT.
- This improves BERT with
- siamese
- triplet network structures
- derive semantically meaningful sentence embeddings that can be compared using
cosine-similarity.
- This reduces the effort for finding the most similar pair from 65 hours with BERT / RoBERTa to about 5 seconds with SBERT,
- https://github.com/UKPLab/sentence-transformers
- https://huggingface.co/sentence-transformers
- https://www.sbert.net/docs/sentence_transformer/pretrained_models.html
- https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2 (commonly used)
- Sentence Transformers: Meanings in Disguise | Pinecone
-
MPNet
- https://paperswithcode.com/method/mpnet
- https://huggingface.co/docs/transformers/en/model_doc/mpnet
- combines MLM and permuted language modeling (PLM) in one view.
- Has
position-aware attentionmechanism
-
ColBERT(Contextualized Late Interaction over BERT)
It is reasonable to think of ColBERT as combining the best of semantic vector search with traditional keyword search a la BM25, but without having to tune the weighting of hybrid search or dealing with corner cases where the vector and keyword sides play poorly together.
- Uses late interaction mechanisms
- Colbert generates embedding vectors for every token in a text, rather than 1 vector for the whole doc
- Its architecture captures cross sequence (query and doc) interaction better than a traditional bi-encoder due to the token level embeddings
- Also faster than a cross-encoder since the document (tokens) embeddings can be pre-computed and retrieved independent of the query.
- Resources
-
How it differs from other embedding models
- Exploring ColBERT with RAGatouille | Simon Willison’s TILs
- In traditional models(normal BERT), we boil down the nuances of ~256 tokens (2/3rds of a page) into a single vector. This is pretty wild.
- Single vector retrieval models are relied upon to take passages of text and compress them to a single “concept”.
- Instead, ColBERT’s approach is to allocate a small, efficient representation to each token within the passage.
-
BGE-M3 models
BGE-M3 - The Mother of all embedding models — pyvespa documentation So M3 trains 3 different representations
- A sparse vector
- A dense vector
- A multi-vector dense (colbert)
Usecases:
- Retrieve: use the dense representation
- re-ranking (for that little extra precision): use the sparse and multi-vectors in
-
SAE
-
ModernBERT
- https://x.com/antoine_chaffin/status/1869847734930550922
- A Replacement for BERT | Hacker News
- https://x.com/jeremyphoward/status/1869786023963832509
- Using modernbert for embedding
- Not Multilingual yet
FAQ
-
Differences between SBERT and MPNet
Aspect SBERT MPNet Training Objective Siamese network, Triplet loss, Paired-sentences, Similarity focus Permuted modeling, Masked prediction, Full token visibility, Position-aware Performance Fast inference, High similarity accuracy, Short text optimal, Production-ready Better benchmarks, Long dependencies, Compute heavy, Long text optimal Use Cases Search, Clustering, Retrieval, Paraphrasing Classification, Long text, Research
-
Differences between BERT and SBERT
SBERT models do contrastive learning on top of a pretrained BERT model.
- BERT outputs a vector per token (????)
- SBERT outputs a single vector embedding. (????)
-
Usecase of “classification”
- To use BERT as a classifier, you need to reduce the dimension either by selecting the CLS token or using a pooling strategy. (so some cross-encoder type thing is needed)
- Typically you would not freeze all the layers when you train a classifier on top of BERT, because the pretraining / pooling will adapt better if they aren’t frozen.
- Embedding models like SBERT regularize the vector space better from their pretraining methods and are better suited toward direct classification. They may not perform better than training on an unfrozen BERT model, however.
-
BGE-M3 vs ModernBERT
- BGE-M3 is a fine-tuned embedding models. This means that they’ve taken a base language model, which was trained for just language modeling, then applied further fine-tuning to make it useful for a given application, in this case, retrieval.
- ModernBERT is one step back earlier in the pipeline: it’s the language model that application-specific models such as M3 build on.
-
What does context length have to do in an embedding/encoder model?
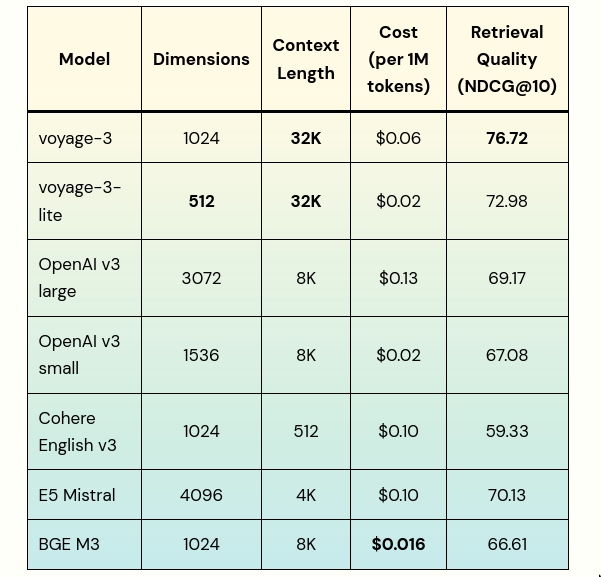
- This is based on how we plan to query: The
denser the contentthesmaller the chunksize. - So if we have dense content, smaller chunk sizes are better right, and we don’t need bigger chunk sizes! hmm, but not entirely true.
- Bigger context sizes can be useful:
- We don’t have to reduce a long context to a single embedding vector.
- We make use of multi-vectors and pooling.
- We compute the token embeddings of a long context and then pool those into sentence embeddings.
- The benefit is:
- Each sentence’s embedding is informed by all of the other sentences in the context.
- So when a sentence refers to “The company” for example, the sentence embedding will have captured which company that is based on the other sentences in the context. (This is called late chunking, coming from late interaction)
- This is based on how we plan to query: The
-
What does “pooling” mean?
“Pooling” is just aggregation methods. It could mean taking max or average values, or more exotic methods like attention pooling. It’s meant to reduce the one-per-token dimensionality to one per passage or document.
-
How does “semantic chunking” relate to “late chunking”?
See RAG You want to partition the document into chunks. Late chunking pairs really well with semantic chunking because it can use late chunking’s improved sentence embeddings to find semantically more cohesive chunks. In fact, you can cast this as a binary integer programming problem and find the ‘best’ chunks this way. See RAGLite [1] for an implementation of both techniques including the formulation of semantic chunking as an optimization problem.
Finally, you have a sequence of document chunks, each represented as a multi-vector sequence of sentence embeddings. You could choose to pool these sentence embeddings into a single embedding vector per chunk. Or, you could leave the multi-vector chunk embeddings as-is and apply a more advanced querying technique like ColBERT’s MaxSim [2].
-
What does “late chunking” really mean? does it actually chunk?
See RAG The name ‘late chunking’ is indeed somewhat of a misnomer in the sense that the technique does not partition documents into document chunks. What it actually does is to pool token embeddings (of a large context) into say sentence embeddings. The result is that your document is now represented as a sequence of sentence embeddings, each of which is informed by the other sentences in the document.
-
Finetuning in embeddings?
See Beating Proprietary Models with a Quick Fine-Tune | Modal Blog
-
What is xlang-ai/instructor-embedding ?
- It’s a way to adapt embedding models (independently of if they have multiple representations like M3) to specific domains.
- To use M3+instructor embedding, you then need to re-train and include the instruction prefixes of instructor into M3
- intfloat/multilingual-e5-large-instruct · Hugging Face (Other instructir embedding models)
AutoRegressive (Generative)
Usecase: Generation
LLM
- Language Models w > 100m parameters
- They don’t have to use Transformers, but many do
- They take text, convert it into tokens (integers), then predict which tokens should come next.
- Pre-trained

-
LLM Implementations/Architectures


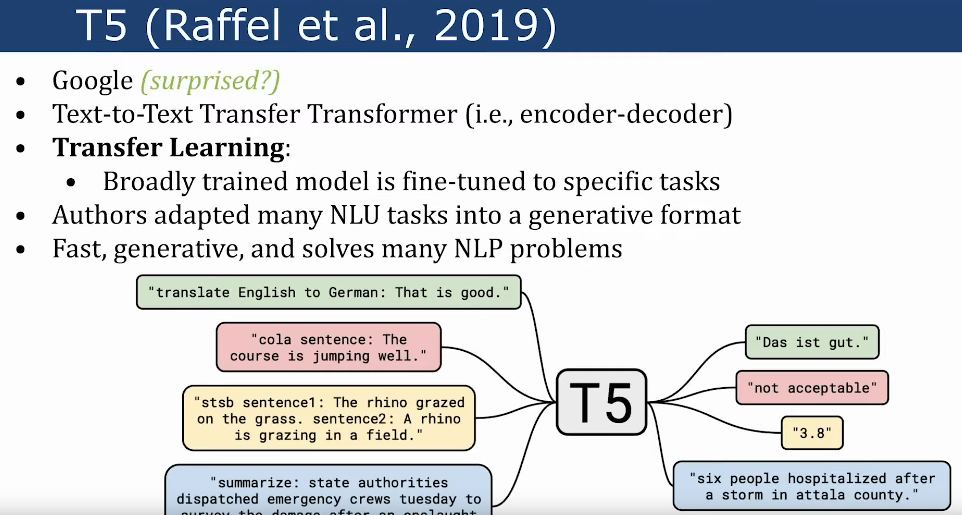
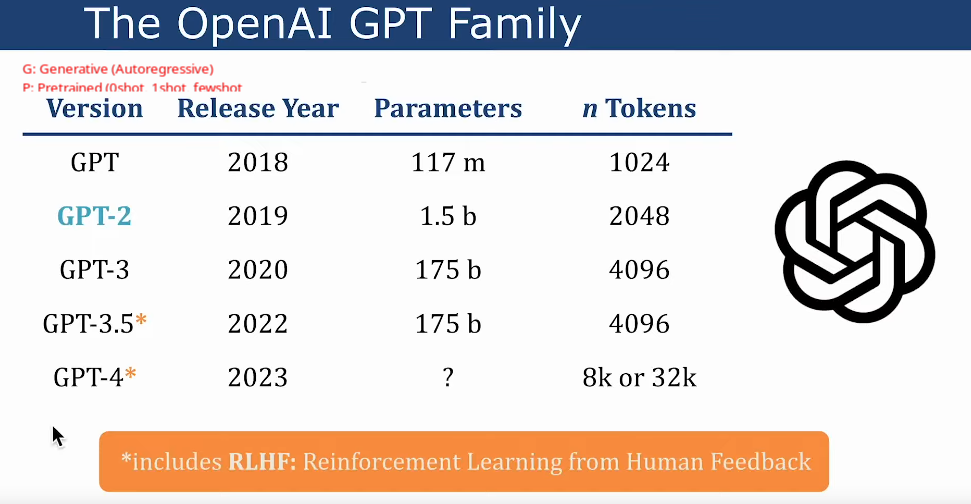

-
LLM Training
Generally LLMs are trained on 1 eval (epoch)
-
Gradient Accumulation

-
Gradient Checkpointing

-
Mixed-Precision

-
Dynamic Padding & Uniform-Length Batching
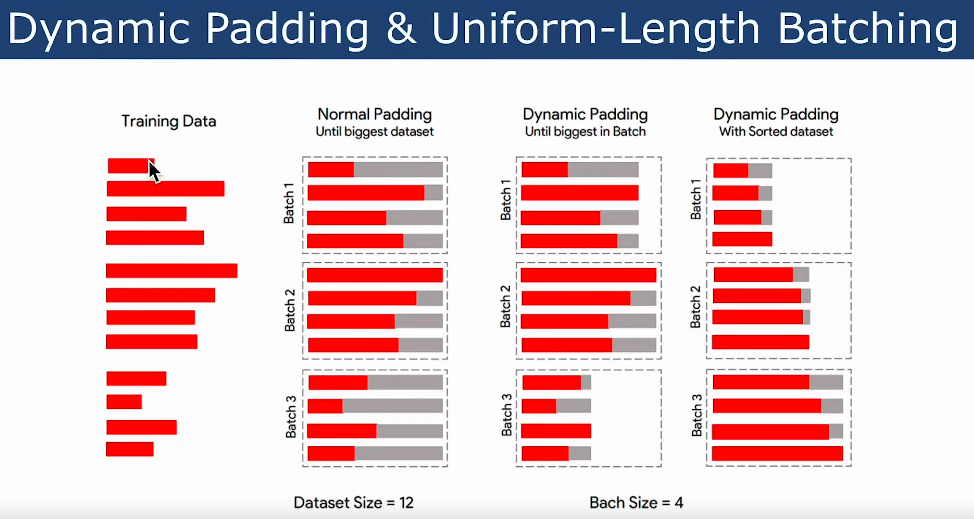
- PEFT with Low-Rank Adaptation
-
RLHF
- This is the secret sauce in all new LLMs
- Reinforcement Learning from human feedback
GPT in production
See Deploying ML applications (applied ML)
Embedding search + vectorDB
-
Basic idea
- Embed internal data using the LLM tokenizer(create chunks), load it into a vectorDB
- Then query the vector DB for the most relevant information
- Add into the context window.
-
When documents/corpus are too big to fit into prompt. Eg. Because of token limits.
- Obtain relevant chunks by similarity search on query from vector DB
- Find top k most similar chunk embeddings.
- Stuff as many top k chunks as you can into the prompt and run the query
-
Example
- Imagine you have an LLM with a token limit of 8k tokens.
- Split the original document or corpus into 4k token chunks.
- Leaf nodes of a “chunk tree” are set to these 4k chunks.
- Run your query by summarizing these nodes, pair-wise (two at a time)
- Generate parent nodes of the leaf nodes.
- You now have a layer above the leaf nodes.
- Repeat until you reach a single root node.
- That node is the result of tree-summarizing your document using LLMs.
-
Tools
- llmaindex and langchain allow us to do this stuff.
- OpenAI cookbook suggests this approach, see gpt4langchain
- pinecode embedded search
- GPT 4: Superpower results with search - YouTube
Prompt tuning
- Idea is similar to embedding search thing but here, you are allowed to insert the embeddings of the prompt into the LLM.
- This is not currently possible with OpenAI’s API
- This claims to better perform prompt search
Finetune
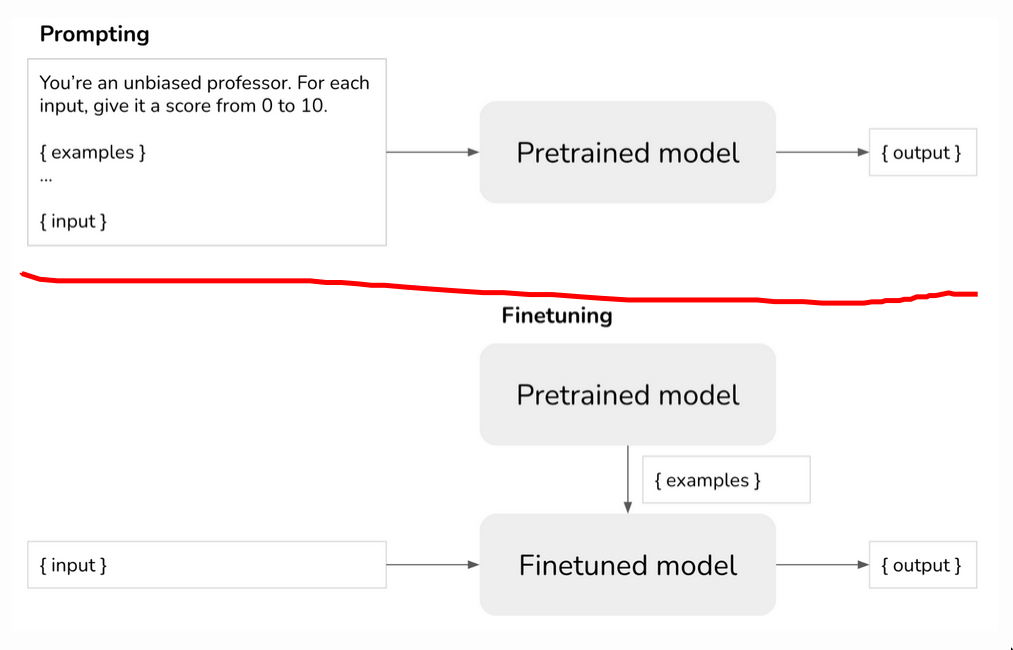 Train a model on how to respond, so you don’t have to specify that in your prompt.
Train a model on how to respond, so you don’t have to specify that in your prompt.
LLMOps
- The cost of LLMOps is in inference.
- Input tokens can be processed in parallel, output is sequential