VLM (Vision Language Model) is a broad term for any model that processes information from both visual and linguistic modalities.
FAQ
Are CLIP and Moondream/LLaVA both Vision Language Models?
- Yes, just different types.
- VLM (Vision Language Model) is a broad term for any model that processes information from both visual and linguistic modalities.
People say for captioning use CLIP, is it true?
- CLIP can’t generate text
- If you were generating caption you are probably using something different.
- One popular library for this was: https://github.com/pharmapsychotic/clip-interrogator
Types
What language these vision models support depend on the underlying text encoder/decoder used. Eg. someone wanted to try ColPali + VLM pipeline or Turkish language, the issue was ColPali PaliGemma) isn’t trained on it so recommended ColQwen & Qwen2VL and it worked. Eg.
voyage-multimodal-3is also multilingual but how much support obviously differs etc.
Pre-training with Contrastive Objective(image-text) (Eg. CLIP)
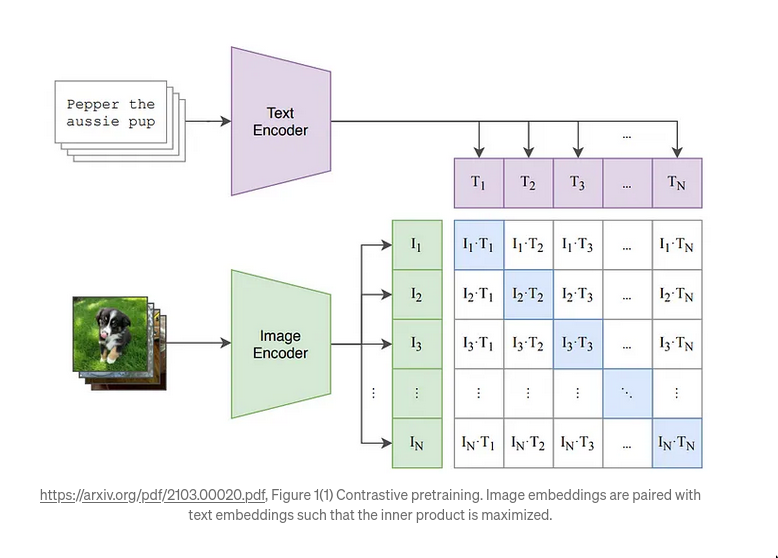
- Main purpose/training objective: Comparison, (putting things in the same latent space)
- https://github.com/mlfoundations/open_clip (maintains both CLIP and SigLIP)
- https://github.com/jina-ai/clip-as-service
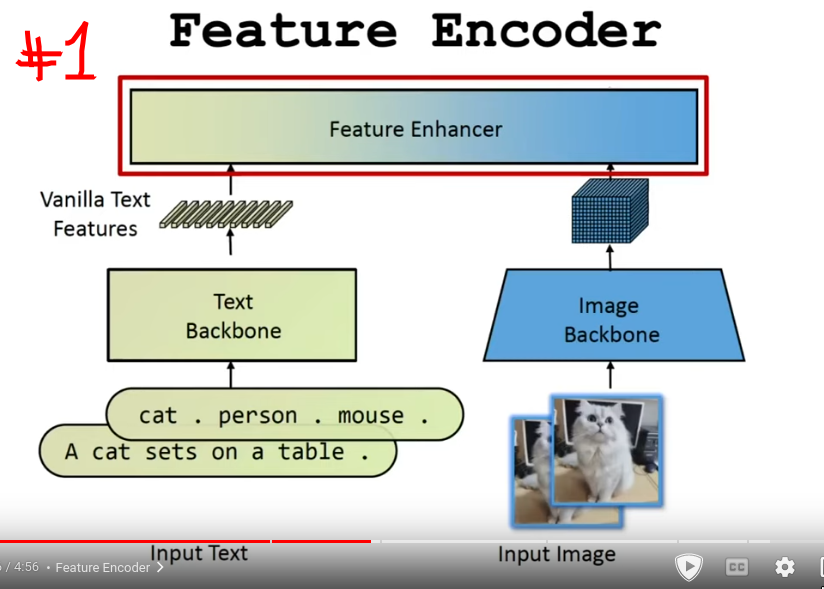
Training CLIP
- Feature encoder: Fuse text and image into one using self attention mechanism
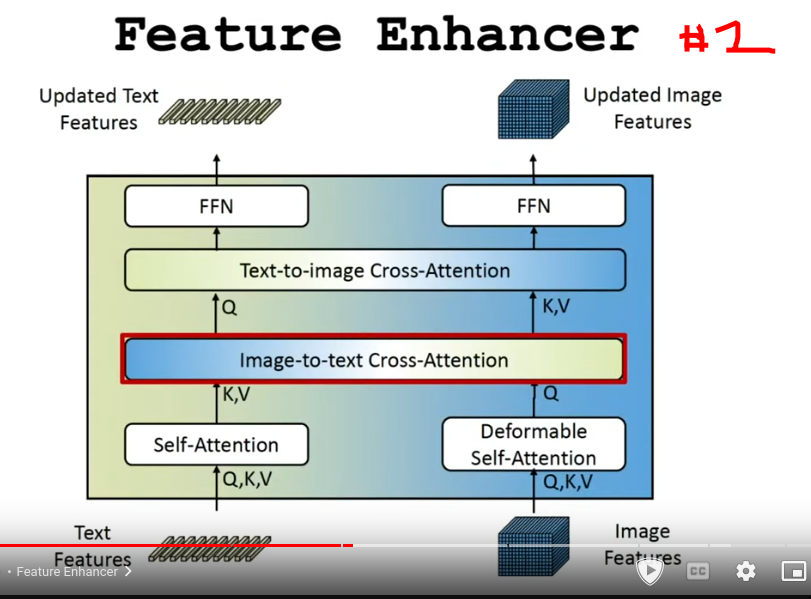
- Enhance encoding: Combines text and image
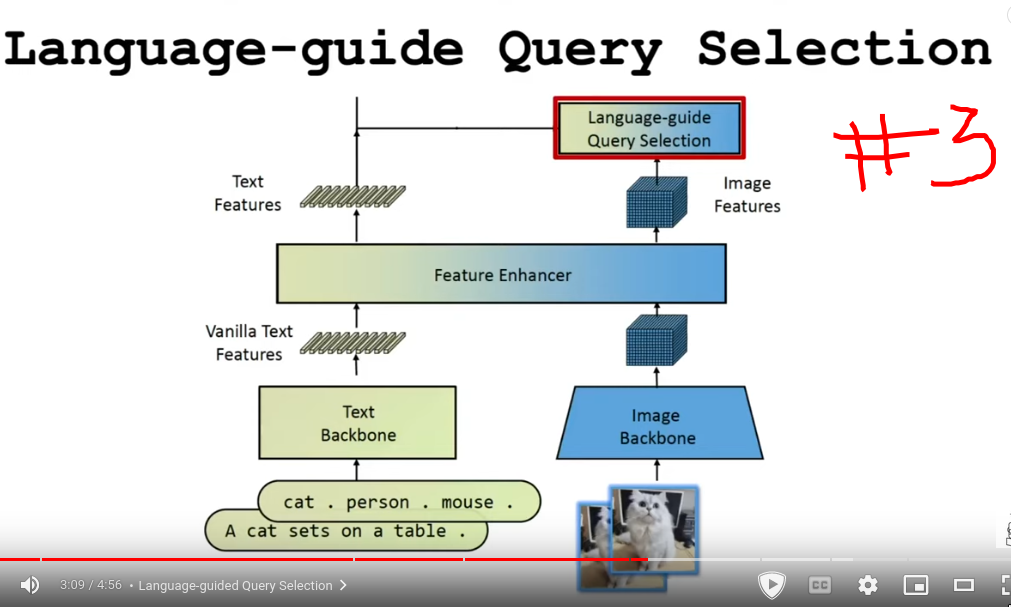
- Language guided selection (Dont understand)
- Cross-Modality Decoder (Dont understand)
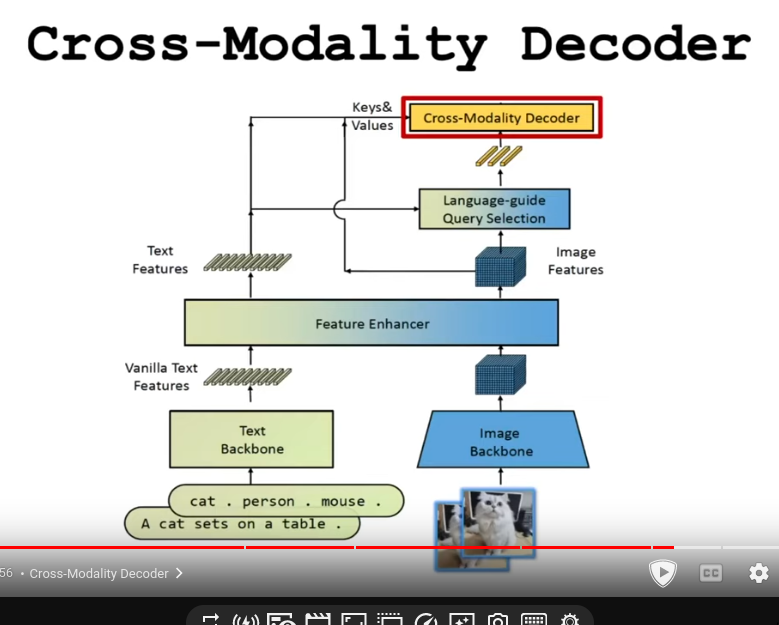
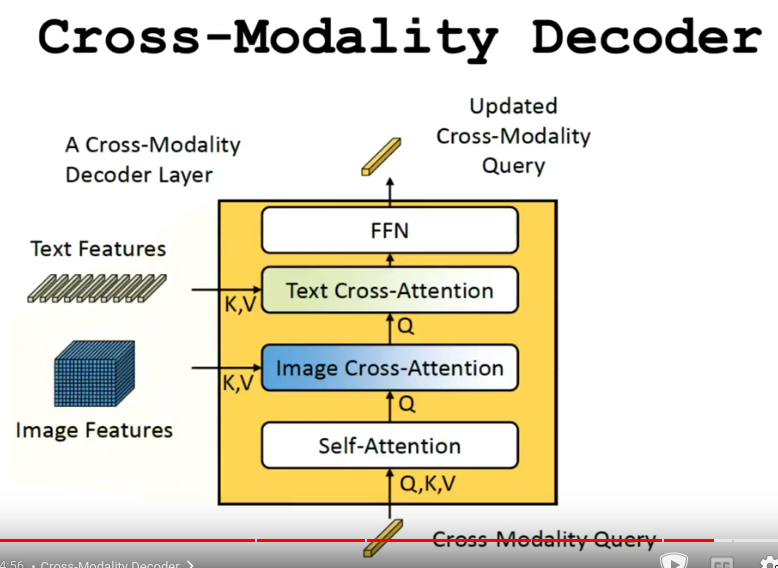
- Calculate loss
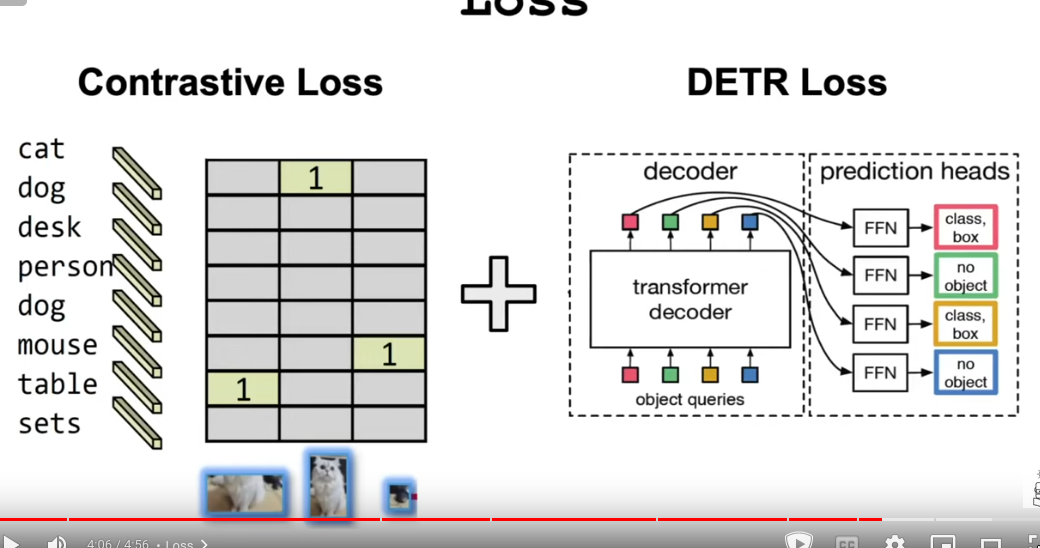
- Contrastive loss: Compare text and visual features
- DETR loss: Bounding box, detect object of interest
- More stuff
CLIP
dual-encoder VLM(image is encoded, text is encoded)- focused on learning joint image-text embeddings.
- 2 parts/components:
text encoder: Some ViTimage encoder
- Use: https://github.com/rom1504/clip-retrieval
SigLIP
Also, as mentioned in the original comment I think using Siglip might be just better than CLIP as laion2b is a pretty messy dataset and to my knowledge Google did a really good job with Siglip. A lot of multimodal models use Siglip as the encoder. Probably just a straightforward improvement in some regards.
Other CLIP variations
- Jina CLIP v2: Multilingual Multimodal Embeddings for Text and Images
- open clip with the Laion2B dataset https://github.com/mlfoundations/open_clip
- long clip (bigger token lengths during training) https://github.com/beichenzbc/Long-CLIP
- meta-clip https://github.com/facebookresearch/metaclip
- google siglip https://huggingface.co/docs/transformers/main/en/model_doc/siglip different loss function
- apple dfn https://huggingface.co/apple/DFN5B-CLIP-ViT-H-14 if I recall the 5b uses a higher image resolution, amongst a number of other innovations (378 ×378 resolution)
- Blip 1 & 2 by salesforce I have worked with also https://huggingface.co/docs/transformers/en/model_doc/blip
Pre-training with Contrastive Objective (image-only) (Eg. DINO)
- If you just want to do image Classification, this is probably better than the other VLM techniques
- Also see Image replacement in Canva designs using reverse image search - Canva Engineering Blog
DINO
- If you don’t need image-text pairs you might even try experimenting with self supervised models like Dinov2.
- In my testing for retrieval of similar off-road driving images, Dino works better than CLIP thanks to visual pre training and CLIP suffers due to language grounding(it gets images which might have been captioned similarly, but have different colors)
DreamSim
- DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data
- It stacks dino and clip embeddings but also finetune’s these models to be a perceptual metric.
- It’s much better at finding similar images rather than images with similar content that look quite different.
Pre-training with Contrastive Objective + Interleaving (image-text) (Eg. ColPali)
Leaderboard: https://huggingface.co/spaces/vidore/vidore-leaderboard
META: Understanding Interleaving and Modality Gap
-
Interleaving (missing info)
This is not a CLIP problem but more of a document processing problem, if you had a document with text & image, you’d parse the text (eg. pdf to markdown) and then embed the images in the document and then also embed the text using CLIP. There’s missing spatial info now. That’s what we call interleaving.
This allows mixing of different types of data (modalities) within a single input sequence or document. This is also sometimes called “interleaving”. Imagine a tutorial page: a paragraph of text, then an image illustrating a step, then more text explaining the image, then another image. This is interleaved data.
-
Modality Gap (skewed representation)
All CLIP-like models perform poorly on mixed-modality search due to a phenomenon known as the modality gap. As illustrated in the figure below, the closest vector to the snippet “I address you, members of the Seventy-Seventh Congress…” is not its screenshot, but other texts. This leads to search results that are skewed towards items of the same modality; in other words, text vectors will be closer to irrelevant texts than relevant images in the embedding space.
 See this blogpost for more details. and also this thread
See this blogpost for more details. and also this thread
ColBERT-like models (ColPali, ColQwen2, ColSmolVLM, ColiVara)
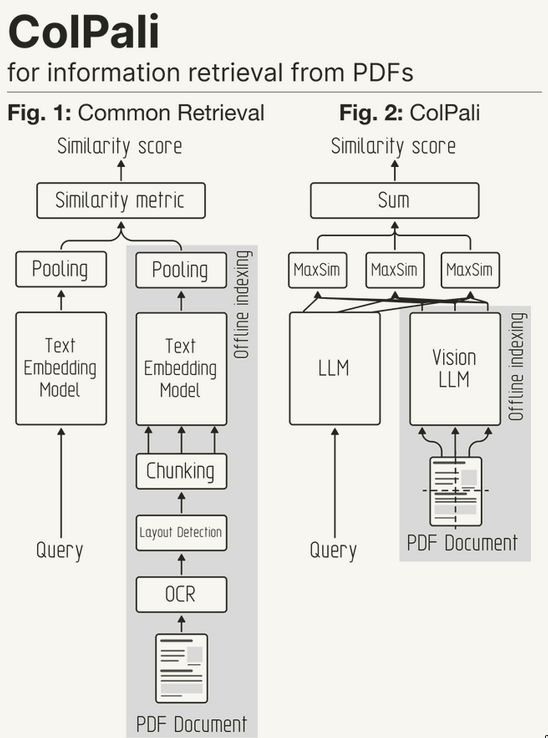
- See ColBERT in NLP (Natural Language Processing)
- Used for PDF extraction, also works for images
- ColPali is enabled by the latest advances in Vision Language Models & LLMs
Col: Leverages multi-vector retrieval through late interaction mechanisms as proposed in ColBERT by Omar Khattab(author of DSPy).Pali: The PaliGemma model from the Google Zürich team (See Computer Vision)
-
More info
- It’s not an extraction(ocr) replacement (I wondered the same thing). It’s retrieval that can bypass extraction.
- I’d misunderstood it as a vision LLM that could extract information from PDFs, it looks like it’s more of an embedding model that can represent a page from a PDF as a set of vectors, which means “will it just refuse to run” isn’t actually a concern (unlike Claude 3 Vision etc)
- In essence; ColPali is just an adapter on PaliGemma for retrieval task, while PaliGemma itself can be used for many others tasks. As the authors point out, you can remove or not use the adapter and also have it use the general capabilities to read the page.
- During indexing, the complex PDF parsing steps are replaced by using “screenshots” of the PDF pages directly.
- These screenshots are then embedded with the VLM. At inference time, the query is embedded and matched with a late interaction mechanism to retrieve the most similar document pages.
-
Resources
- pdf retrieval with ColQwen2 vlm Vespa cloud - Vespa python API
- https://www.analyticsvidhya.com/blog/2024/10/multimodal-retrieval-with-colqwen-vespa/ 🌟
- https://huggingface.co/blog/manu/colpali
- https://blog.vespa.ai/retrieval-with-vision-language-models-colpali/ 🌟
- Your connected workspace for wiki, docs & projects | Notion
- https://github.com/merveenoyan/smol-vision/blob/main/ColPali_%2B_Qwen2_VL.ipynb
Voyage-Multimodal-3
- This is like the hosted version of ColPali
- In contrast to CLIP, this uses a
unified encoder(uses the same encoder for text&image) - The architecture is similar to how LLaVa works(post projection), but in usecase/objective of comparision.
Document Screenshot Embedding (DSE, MCDSE)
See [2406.11251] Unifying Multimodal Retrieval via Document Screenshot Embedding
Pre-training with Generative Objective (Eg. Moondream/LLaVa/Gemini/OAI Multimodal)
- Turns an existing LLM into a vision assistant
- https://github.com/jiayev/GPT4V-Image-Captioner
LLaVA/Moondream
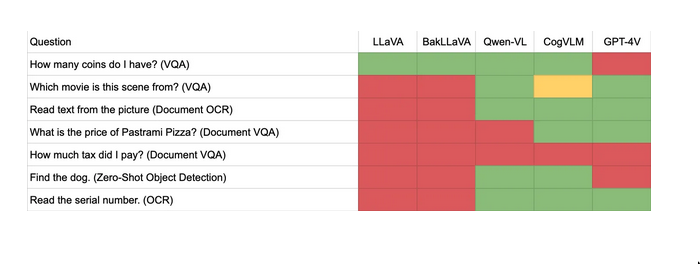
encoder-decoder VLM(where the vision & text encoders feeds into an LLM decoder).- visual instruction-following model
- eg. moondream depends on Phi1.5(LLM) and SigLIP(visual encoder like CLIP) etc.
- 4 parts/components:
image encoder: ViT (usually from CLIP, SigLIP etc, skipping the )projection layer:- The projection layer in VLMs like LLaVA acts as a learned translator, adapting visual features from a vision encoder into a format (dimensionally compatible embeddings) that a Large Language Model (LLM) can understand.
- It’s trained, often with the LLM frozen initially, to map these visual features into the LLM’s input space using image-text datasets.
- This enables the LLM to process and reason over both visual and textual information for tasks like visual Q&A.
text encoder: LLM embeddingtext decoder: LLM
Understanding how LLaVA/Mooderam etc. is different from CLIP/ColPali
“Because LLMs such as Gemini — and other causal language models more broadly — are trained on next token prediction, the vectors that you get from pooling the output token embeddings aren’t that useful for RAG or semantic search compared to what you get from actual embedding models.”
llm( projector(ViT(image.png)) + embed(text prompt) ) = text output- Here both of the arguments sent to llm are in dimensionally compatible embedding after
projection.
- Imagine the
projection layer’s output (visual pseudo-tokens) as a report about the image written in a very specific technical shorthand that the “Committee Pre-processor” understands. - Imagine the LLM’s initial text embeddings for your prompt as your question, also translated into that same technical shorthand by the “Committee Pre-processor.”
- Usecase
Generative(GOOD)- You just send these 2 embeddings into the LLM and you should get a nice text output
Comparison/Similarity(BAD/DONT DO)- See Embeddings FAQ for understanding that
embedding != similarity - Here we’re trying to use a something which it models like LLaVA are not built for.
- We CAN probably take the embedding generated by
projection layerand the embedding of thetext promptand try running cosine similarity in it right as the embedding dimensionality match? That’ll be same as CLIP right? - Well, NO.
- This most probably won’t work as expected, because there’s no direct training pressure in LLaVA to make these two specific sets of initial embeddings (projected visual vs. prompt text) align in a way that globally maximizes their cosine similarity for matching pairs.
- Coming back to our example, these shorthand reports are just the starting point for the main Committee (LLM layers). The Committee’s job is to take both, discuss them deeply, cross-reference, infer, and then produce a final considered statement.
- i.e for any further understanding of this embedding pari(image&text), we must pass it though the LLM. This is unlike CLIP, where the embedding themselves carry intrinsic meaning about where it belongs in a space.
- See Embeddings FAQ for understanding that
Pre-training with Unified Understanding Objective (Eg. BLIP)
This does both embedding and captioning. Sort of like a middle child.
- Example: BLIP, BLIP-2
- [2205.01917] CoCa: Contrastive Captioners are Image-Text Foundation Models
Pre-training with No text, only Visual Thinking
- This is very new(May’25)
- See: [2505.11409] Visual Planning: Let’s Think Only with Images
Video Embeddings?
TODO Finetuning and Augumenting VLMs
Finetuning diffusion model(Image generation models) is different, see StableDiffusion for that.
- Vision Language Models Explained 🌟
- Paper page - mmE5: Improving Multimodal Multilingual Embeddings via High-quality Synthetic Data
- Google Colab
- FastVLM: Dramatically Faster Vision Language Model from Apple | Hacker News
- Trying out QvQ – Qwen’s new visual reasoning model | Hacker News
- PaliGemma 2: Powerful Vision-Language Models, Simple Fine-Tuning | Hacker News
- Fine-tune SmolVLM on Visual Question Answering using Consumer GPU with QLoRA