tags : Infrastructure
FAQ
Resources
- Glossary | Kubernetes
- A Guide to the Kubernetes Networking Model | Kevin Sookocheff
- Operating a Kubernetes network
Liveness vs Readiness / Healthchecks
- Liveness probes are used to tell kubernetes to restart a container. If the liveness probe fails, the application will restart. This can be used to catch issues such as a deadlock and make your application more available. My colleagues at Cloudflare have written about how we use this to restart “stuck” kafka consumers here.
- Readiness probes are only used for http based applications and are used to signal that a container is ready to start receiving traffic. A pod is considered ready to receive traffic when all containers are ready. If any container in a pod fails its readiness probe, it is removed from the service load balancer and will not receive any HTTP requests. Failing a readiness probe does not cause your pod to restart like failing a liveness probe does.
- From Distributed Systems Horror Stories: Kubernetes Deep Health Checks – Encore Blog
- lorentz app
Setting it up from scratch
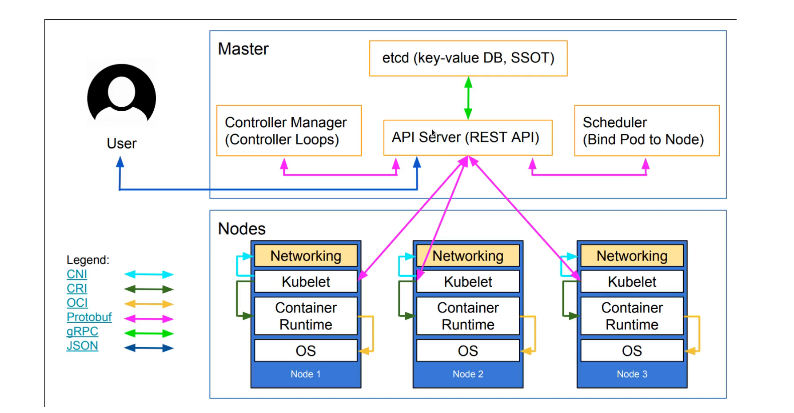
- Much like the Linux kernel needs to be combined with additional software to make a complete operating system
- Kubernetes is only an orchestrator and needs to be combined with additional software to make a complete cluster.
- CRI: It needs a container engine to run containers (See OCI Ecosystem, Containers)
- CNI: It needs network plugins to do networking
- PersistentVolume subsystem: It needs storage to be managed
K8s YAML management best practices?
Package management?
- HELM uses charts. It’s “the” package manager for k8s
- Helm charts are comparable to Ansible roles.
What’s KNative?
- Just another abstraction over Kubernetes objects with some unique features.
- Its autoscaling is more advanced than native HorizontalPodAutoscaler (HPA) could provide. HPA works with deployments where at least 1 pod exists, because it checks pod metrics - no pod, no metrics. KNative on the other side is focused on HTTP services and could scale them to zero.
- Tools like knative are largely solving organizational problems, not technical ones. (easier k8s to say)
- Google Cloud Run is essentially a managed version of Knative.
Components
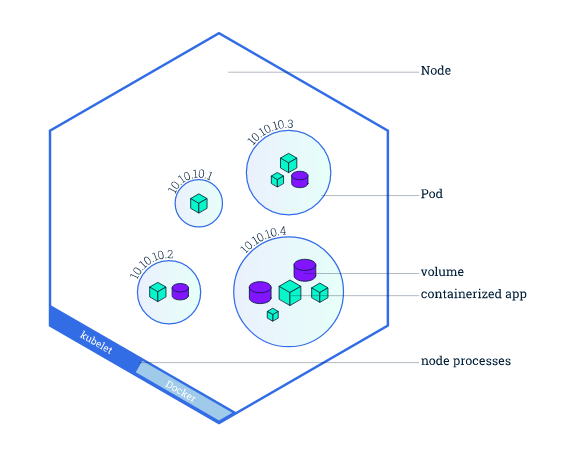
- Node can run pods, pods can run containers, often discouraged to run more than one container in a pod unless its a sidecar.
Pods
Poddefines nothing about when/how/where to run, so k8s will not know if it needs to restart it etc. For these we needDeploymentobject. (A persistent object)
DaemonSet
- Specifies stuff that is supposed to run on each
nodeas apodby default. - It’s started on node creation and stopped on node deletion.
- It runs what it specifies as a
podinside thenode - Similar to an init(think systemd) process but for the
node
Networking
Overlay network
- Our cluster(nodes, pods) is one big flat IP network, no NAT etc in between, namespaces are not a security feature.
- By default everything can reach everything, we can add network policies to address this.
- Responsibilities
- Make sure your pods can send network requests outside your cluster
- Keep a stable mapping of nodes to subnets and keep every node in your cluster updated with that mapping. Do the right thing when nodes are added & removed.
Pod networking
Inside Pod
- containers running in the same pod share the same network namespace, i.e can talk over loopback. i.e sidecar can use loopback to talk to main container.
Pod to Pod in same Node
- Different pods can talk to each other without using NAT
- The IP that a Pod sees itself as is the same IP that others see it as.
- This is essentially communicating across network namespaces which can be done via
veth pair. See Containers.
Pod to Pod in different nodes
- Every Node in the cluster is assigned a CIDR block, IPs for a node can be used by pods running on that Node.
- Each Node knows how to deliver packets to Pods that are running within it.
- How do we know which node to send the traffic to?
- This is network specific, basically needs a router.
- This is now basically node-node networking
- All Nodes can communicate with all Pods without NAT. Just routing.
- This is where CNI comes in.
- AWS Example
- In AWS, a Kubernetes cluster runs within a VPC
- AWS has a CNI plugin that manages this based on AWS VPC,IAM, Security Groups, ENI etc.
- ENIs are accessible to other ENIs across the VPC.
- Each
Node(EC2 instance) creates ENIs and allocates IPs to them creatig a pool. (Forming CIDR block) - CNI plugins usually setup a
Daemonset(per node) which picks IP from the pool and provide adds newly created pods to its network
More on CNI
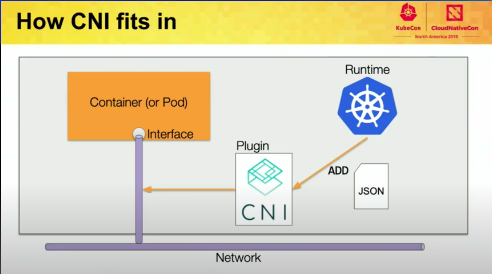
- Provides a common API for connecting containers to the outside network.
- Well defined spec for writing K8s network plugins, it is not tied to k8s and was created as an interface that could talk to any runtime and any network
- The plugins are simple executables that take simple commands like ADD, DEL etc.
- It’s responsible for setting up the network interface for the pods, configuring routes, allocating ips etc.
- K8s does not mandate any particular implementations, currently lists about 15 different implementations.
- The plugin can it-turn use a DHCP server to get the IPs if needed etc.
- Options: Calico w tigara operator, Cilium, Fannel, waeve
Egress and Ingress
Egress (out of k8s)
- pod tries to connect to the internet using a
pod ip/cluster ip(when usingservice) assource ip - Problem: VPC gateway in cloud providers are not container aware. They are aware of the
node(ec2) ip address but have no idea aboutpod iporcluster ip. So NATing this is weird. - Solution: Using iptables
- SNAT w
manglethepod iptonode ipbefore packet leaves thenode - Another SNAT of VPC VM(node) IP to public IP by the cloud-provider gateway
- SNAT w
Ingress (in to k8s)
- This is more involved than egress and requires a dedicated k8s controller.
- It needs
- L3: A
Servicew a typeLoadBalancer(LoadBalanceris provided by cloud provider)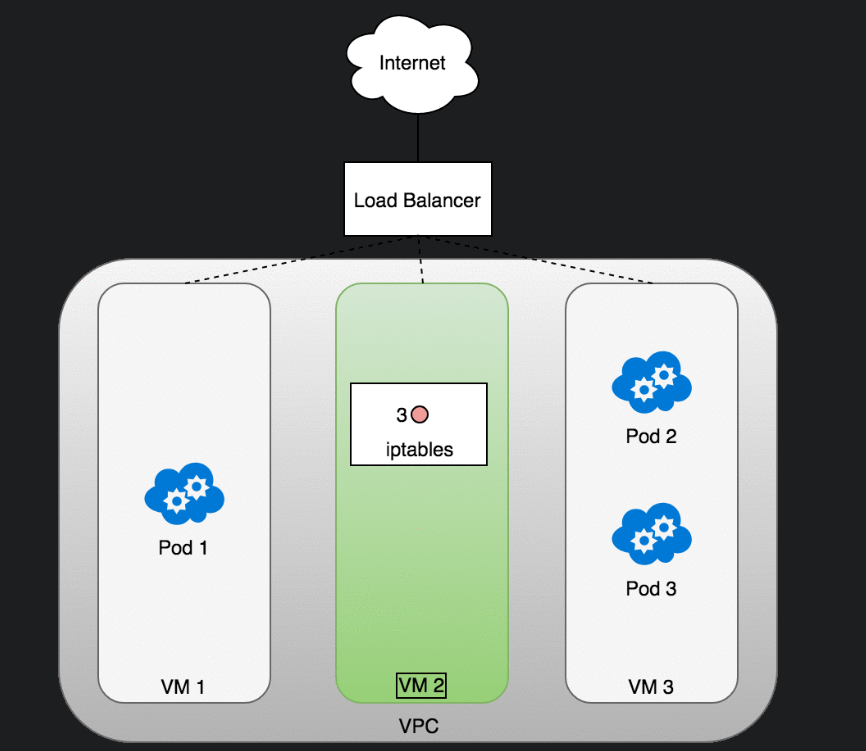
- L7: An
Ingresscontroller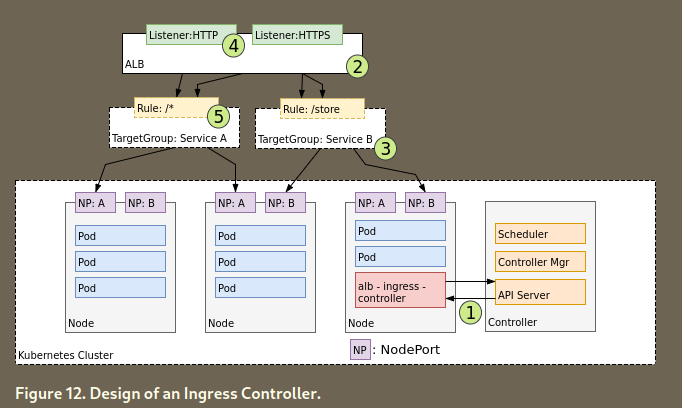
- Uses http, built on top of
Service - Needs service w
NodePort - Maps HTTP requests to Kubernetes Services
- Uses http, built on top of
- L3: A
Persistent network IPs & Load balancing
Servicesare stored inetcdas k8s REST object, controllers can watch for changes via theapi-server.Serviceis an abstraction to help youexpose groups of Podsover a network. Because Pod IP assigned by CNI are ephemeral.service(L4) assigns a single stable virtual IP for group ofpods(L3).- This
virtual IPis also known ascluster IP - You can do L2 networks in K8s but many cloud providers don’t allow it.
- Since Services itself is more of L4 concept, L4 load balancer are better fit.
- When declaring a
Service, you can specify whether to useiptablesorIPVS. - The Load balancing we talk about here is not the same as a service with the
LoadBalancertype. That one is provided by the cloud-provider and not container aware.
Load Balancing w iptables (L3)
- Any traffic coming to the cluster IP is load balanced by k8s
- It uses netfilter(backend to iptables) for doing the load balancing
More on kube-proxy
- Certain CNI plugins make it possible to use the cluster without
kube-proxy(Eg. cilium, uses ebpf instead of iptables) - It runs on
each node - A huge part of the k8s ecosystem currently relies on iptables (kube-proxy).
- Standard kube-proxy is just a lot of chains in the nat(
iptables -t nat -L -v) and filter(iptables -L -v) tables and maybe some on the mangle table. - (old info):
kube-proxyuses iptables and-j DNATrules to provide load-balancing for services.- Multiple iptables rules for each backend a service is serving to.
- Each service added, the list of iptables rules to traverse grows exponentially.
- iptables lack of incremental updates. The entire list of rules has to be replaced each time a new rule is added. Eg. 5 hours to install the 160K iptables rules representing 20K k8s services.
Load Balancing w IPVS (L4)
- IPVS (IP Virtual Server) built on top of netfilter
- Implements transport-layer(
L4)(TCP/UDP) load balancing as part of the Linux kernel.
DNS in K8s
- Optionally we can do dns.
- Can be used to DNS:
cluster IP,IP of a podw/o aservice - Involves configuring to
kubeletson eachnodeto do the falicitate this - K8s DNS pod itself runs behind as a
servicein the cluster w a staticcluster IP
Operator Pattern
- CRDs + Controllers
- Thinking of kubernetes as just a collection of operators where some of them are maintained by the project (“in tree”) and some are maintained by others (“out of tree”) is an interesting thought experiment
Practical notes
- Signal handling is important because say if your program does not handle signals properly then the container will
killthe program based on the timeout you set. If the timeout is set of1minand100machines need rolling update. It’ll take100minsif done sequentially, if signals were handled properly container will shutdown as soon as it gets the signal to shut after doing any cleanup assigned. - Blue/Green Deployment, you have two production environments, as identical as possible, as you prepare a new release of your software you do your final stage of testing in the green environment. Once the software is working in the green environment, you switch the router so that all incoming requests go to the green environment - the blue one is now idle.
- Out of many ways, two ways to be highly available: make individual components HA, another idea is to do something in a bigger scale, eg. switch entire VM if something is not working in one vm.
TODO Usage Snippets
- Move these to cheats later
# show all the spec of the running k8s version for Node
$ kubectl explain node.spec
# show all the spec of the running k8s version for Node
# helpful when you can't lookup the online doc.
$ kubectl explain node --recursive
# getting pods
$ kubectl get pods --all-namespaces
$ kubectl get pods --namespace=<name>
# execing into a pod
$ kubectl exec -it <pod-name> -- /bin/bash