tags : Kubernetes, Infrastructure
These notes are from when I am trying to run Nomad on hetzner
Intro
- Nomad
serveris just a workload orchestrator. It only is concerned about things like Bin Packing, scheduling decisions. - Nomad doesn’t interfere in your DNS setup, Service Discovery, secrets management mechanisms and pretty much anything else
Concepts
Availability of “Platform” v/s Availability of “Application”
- When you’re talking about nomad fault tolerance, we’re talking about “availability of platform/infra”
- Application availability is controlled by the
migratestanza in the configuration
Implications of Raft consensus for nomad server consensus
 See
See - Raft is used between
servers - Nomad, like many other distributed systems, uses the raft consensus algorithm to determine who is the leader of the server cluster.
- In nomad, the IP address is a component of the member ID in the raft data.
- So if the IP address of a
nodechanges, you will either have to do peers.json recovery or wipe your state.
- So if the IP address of a
-
Fault Tolerance
With FT, the state is replicated across servers
- WE WANT TO MAINTAIN ATLEAST 1 QUORUM AT ALL COSTS
- If we loose quorum, then
- You be able to perform read actions
- But you won’t be able to change the state until a quorum is re-established and a new leader is elected.
- Ideally you’d want to run
serverin a different failure domain than theclient(s)
-
2
servers- 2 servers = 2 quorum (i.e we need atleast 2 servers to elect a leader and maintain quorum)
- If you have 2
servers, it’s impossible to elect a leader since none of the servers has a winning vote.- For this reason, there is zero fault tolerance with two servers
- Running two servers only gives you no fault tolerance in the failure of
servers - If one
serverfails, we loose thequorum, hence no leader for the entire cluster.- Without leader, no state writes, no re-schedules, no cluster state changes.
-
3 servers
- 3 servers = 2 quorum (i.e we need atleast 2 servers to elect a leader and maintain quorum)
- In this case, if we loose 1 server agent, quorum will still be maintained and things will keep running as expected.
-
Doubt
- I don’t quite understand the 3/5(odd no) server requirement, I think it should become more clear as I do Data Replication
- Q: What happens if I run with 2 servr nodes, 4 server nodes?
- I don’t quite understand the 3/5(odd no) server requirement, I think it should become more clear as I do Data Replication
FAQ
Sidecar pattern inside a task group
main task: Main tasks are tasks that do not have alifecycleblock.- Sidecar tasks: Init/post/sidecar tasks
sidecarset to true means sidecar, else ephemeral task
- For log shipper pattern, we also want to set
leader:truein themain task- When the
main taskcompletes all other tasks within the group will be gracefully shutdown. - The log shipper should set a high enough
kill_timeoutsuch that it can ship any remaining logs before exiting.
- When the
Allocation and Port collision for static port
- When we use static port we occupy port in host machine/node
- When we set task group count > 1 and be using static port, and our cluster has <2
client, then we don’t have any way to make this happen. We either use dynamic port or go add a new client(node) or something.
service block & network block (can there be multiple?)
| Block Name | Level | What | Multiple |
|---|---|---|---|
| service | task and task group (added later for consul connect support) | How other services will find the task | Yes, multiple network:port and multiple services is good combo, eg. expose metrics and web traffic in different ports |
| network | group | How the tg connects to the host/node | Not yet, but can have multiple ports |
- Note
- If you have multiple services in a
task groupthen you need to explicitly specify the names for all theservices. You can omit the name of atmost one service definition inside aTask block.
- If you have multiple services in a
Hierarchy
-
Control
- Job - Task Group(s) / Allocation(s) - Task(s)Type Control How many Job Controlled externally(job runner/airflow/cicd etc) As many as the business needs are Task Group There’s no nomad specific ordering, they fire parallely but we can wait on things Can be singleton(eg. PostgreSQL), can be multiple TG(independent, web&db), dependent on some other service by waiting Task lifecycleblocks, these are inside the task group and don’t get to control how TG themselves are orderedThis is based on the idea of main task and supporting tasks(init/cleanup/sidecar etc)
-
TODO Placement
- Region - Datacenter - Nodepool - Namespace-
Difference between nodepool and namespace and when to use what
-
-
TODO Communication
- Federation - Gossip - RPC - See the architecture doc
TODO Allocation(task group) single or multiple tasks
- This really depends but stick to the “if these really need to be on the same client”
- If you have a singleton pg suppose then maybe
1TG:1Task(sidecars)would be good - If you have another application in which you run the custom db and web app, these 2 can be different
Terms
Task Group- Group of tasks that need to run on the same
client agent. - Usually a
host/nodewill only run oneclient, so put things in the same task group when we need them to run together. (Eg. shared filesystem, low latency etc)
- Group of tasks that need to run on the same
- Allocation
- It’s a
Task Groupwhen submitted. i.e"count" of a task group=no. of allocations for the task group. It’s like the same thing different forms. ice and water kind. - Allocations is as the space/resources dedicated to a task on each machine.
- Each allocation can be across different machine/hosts/node/clients but, as the promise of the
task group, each individualtask groupwill run on a singlenode/host- Eg. If we do
count=100, there will be 100 allocation across devices
- Eg. If we do
- It’s a
- Deployment
- A deployment is the actual object that represents a change or update to a job.
- As of the moment the concept of deployment only really applies to
service jobs update block- Update strategy for new allocation
- Evaluation
- It’s the submission to the scheduler. Eg. After successful
evaluationof the job, atask groupbecomes anallocation
- It’s the submission to the scheduler. Eg. After successful
Configuration
Setup Config
See https://gist.github.com/thimslugga/f3bbcaf5a173120de007e2d60a2747f7
Nomad
Server agent
Client agent
Workload Config
- Workload configuration is
JobSpec-
This can be managed using Terraform ? (Q: Do we really need TF here?)
-
The
JobSpecitself sometimes need templating- eg. We cannot have a local file on your laptop be directly provided. In these cases we can either use Terraform variables as seen here or we can use HCL2 or maybe something else.
- I am of the opinion that we use terraform only for infra provisioning(the backbone) and not for deployments and stuff, so we’d try to avoid terraform for deployments of services as much as we can unless we don’t have an option.
-
Note about HCL2
filefunction usage in nomadFunctions are evaluated by the CLI during configuration parsing rather than job run time, so this function can only be used with files that are already present on disk on operator host.
-
Application arguments
- This is done via
task>config>args, this also supports “variable interpolation”
application configuration file
- The
templatestanza helps in writing files toNOMAD_TASK_DIR(viadestination) which is isolated for each task and accessible to eachtask - This can later be supplied to the task in various ways
bindmounts fordocker task driver- Directly accessing
local(NOMAD_TASK_DIR) if usingexec task driver
- For docker task driver flow is like
- First get the file into
NOMAD_TASK_DIRusingtemplateor combination oftemplateandartifact - Then bind mount the file from
local(NOMAD_TASK_DIR) to the container
- First get the file into
Env Vars and Secrets Management
-
Environment variables
env stanza- Directly specify, supports interpolation
template stanza- Can be used to generate env vars from files on disk, Consul keys, or secrets from Vault:
-
Nomad variables
- Securely stores encrypted and replicated secrets in Nomad’s state store.
- Nomad Variables is not meant to be a Vault replacement. It stores small amounts of data which also happens to be encrypted and replicated. My advice is to treat Nomad Variables as a stopgap until you are ready to transition to Vault.
- These as of the now can be using using the
templatestanza, writing it into a file in nomad task dir and settingenv=trueintemplatestanza - ALC is preconfigured for certain paths
- Two ways of using nomad variables
- Using explicit mention of path
with nomadVar "nomad/jobs/redis" }}{{ .maxconns }}{{ end
- Using all of nomad variables in the task using
nomadVarList - I prefer explicitly writing the path (1st choice)
- Using explicit mention of path
-
Consul
- Using it with key}} and {{secret if you know the variable path
- Vault
- KV
Nomad x GPU / cuda
- We’ll first need the NVIDIA Container Toolkit installed on the host machine.
- On nixos it’s just:
virtualisation.docker.enableNvidia = true;(also needs 32bit support in graphics for some reason)
- On nixos it’s just:
Auxiliaries
Plugins
Volumes and Persistence
- We have
- Nomad volumes (host volumes, filesystem or mounted network filesystem)
- Container Storage Interface (CSI) plugins
- Docker volumes (Supported but not recommended plus nomad scheduler will not be aware of it)
- So we either want to use Nomad volumes or CSI
- We’ve to specify it in the
client agentand then use that volume in ourjob
- We’ve to specify it in the
-
Docker driver specific
- As mentioned before, better to use nomad volumes instead of docker volumes
- But docker
mountconfig in the nomad docker driver can be useful sometimes. Currently supports:volume,bind, andtmpfstype- usecase could be config loading, but the
atrifactstanza also helps with thattemplatestanza is enough for local files, for remote files, we might want to useartifact
- Eg. The caddy official image takes in mount points, in which can use
mountto mount the data and config file.- CONFIRM: This can be combination of volume(data directory) and bind mount(config file with artifact and template stanza)
- usecase could be config loading, but the
Features
Restarts & Checks
update > healthcheck > check_restart > restart > fail? > reschedulerestart
# example
# if things don't come up based on check_restart
# - attempts: restart the machine 2 times
# - interval: till we reach 5m, with 25s(delay) gaps
# - mode: If sevice doesn't come up declare it fail
restart {
interval = "5m"
attempts = 2
delay = "25s"
mode = "fail"
}- This can be set in the
task groupandtasklevel. Values are inherited and merged. - no. of restart “attempts” should happen within the set “interval” before nomad does what “mode” says
mode:delaymakes sense when re-running the job afterintervalwould possibly make it succeed, otherwise, we would go withfail
check_restart
- When the
restarthappens is controlled by thecheck_restartstanza grace: This is important because we want to wait for the container to come up before we evaluate the healthcheck results
check (Health Checks for Services)
- This is just the health check, this does not trigger any activity
check_restartstanza can be set insidecheckblock to specify what happens when the health check fails- Then the
restartblock in turn later determines how. Then how often and till when rerstart is triggered is controlled by therestartblock properties.
- Then the
Shutdown Delay
- For
service, we haveshutdown_delay- Useful if the application itself doesn’t handle graceful shutdowns based on the
kill_signal - The configured delay will provide a period of time in which the service is no longer registered in the provider
- Thus not receiving additional requests
- Useful if the application itself doesn’t handle graceful shutdowns based on the
Service Discovery
Nomad Service
- They can be at the
task grouportasklevel. I usually like to put them attask grouplevel because it then is next to thenetworkblock and makes things easier to read. - Health checks
- Are set by
check - Can be multiple checks for the same service
- Used provider mandates what kind checks are possible
- Are set by
Providers
-
Native Nomad Service Discovery
- This was added later, prior to 1.3 only consul was there
- It’ll work for simpler usecases, for complex usecases, we might want to adopt consul
- Consul
-
Consul Connect
- lets you use service mesh between nomad services.
- Q: If this does this, what does only Consul do?
- lets you use service mesh between nomad services.
-
Others
- Worth noting that Traefik also supports discovery of Nomad services without Consul since Nomad 1.3.
Webassembly
See WebAssembly, Virtualization Scheduling WebAssembly-backed services with Spin and Nomad
Networking
- See Containers
- For each
task groupwe have have anetworkstanza- In the
taskgroup:networkwe specify theport(s)that we want to use in our tasks. In other words we “allocate” theportsfor the task.
- In the
- But each task-driver which is specified in
taskstanza also can have its own networking configuration.
On network:port
to: Which port in the container it should allocate tostatic: Which port in the host nomad should map the container allocated(to) port to.
Detour of modes
TODO Networking modes
See network Block - Job Specification | Nomad | HashiCorp Developer
- You set these in the
networkstanza- You can use
nonebridge- This is useful w nomad service discovery
- Has a “mapping with a certain interface” via the
portstaza - This uses CNI plugins
- Things would NOT show up in
netstat -tulnp, you’ll have to switch namesapce if you need to check this. - If you have access to the
interface, even if it????????
host- No shared namespace
- Use host machine’s network namesapce
- Things would show up in
netstat -tulnp
cni/<cni network name>- This needs to be configured per client
TODO Service address modes
Docker Task Driver Networking notes
- Nomad uses
bridgednetworking by default, like Docker.- You can configure
bridgemode both innetworkstanza anddocker task driver:networkstanza, both are conflicting. See nomad documentation on this. Ideally, you’d only want to use nomad network bridge.
- You can configure
- The Docker driver configures ports on both the tcp and udp protocols. No way to change it.
- with
task:config:portsthe port name is used to create a dynamic env var. Eg. something likeNOMAD_PORT_<port_name>, whereport_nameare the items inconfig:ports. This can be used inside the container.
Service Discovery and Networking
networkingstanza has different modes,hostis the simplest.bridgemode needs various CNI plugins.- If you’re using
hostnetworking mode and then use SD mechanisms to say populate the configuration file for some job. If you update the upstream job and the upstream job is having an dynamic port, now you configuration file has become stale! (This happened to me with nomad native SD andhostmode for a job which was being used in Caddy reverse proxy)
More on bridge networking
- Once you
- How do you access jobs running on bridge from machine localhost??
- Interestingly, even if the ports don’t show up in
netstat -tulnp, you will be able to access them from your local machine.
- Interestingly, even if the ports don’t show up in
- Inspecting bind traffic
TODO Networking Q
- Does SD really not work in nomad if I have set mode to host?
- same port, same ip address, same interface, different namespaces
- netstat is not showing port
- but i am able to access it from host
- I can listen for something on the same port on my server, curl still follows the old route(???)
Deployment
Production setup
How nomad is supposed to be run
- Hashicorp doc sometimes uses the term
nodeandclientinterchangeably. Which is confusing.
- In docs, A more generic term used to refer to machines running Nomad agents in client mode.
- Here’s what I’ll follow for my understanding
nodeis a bare metal server or a cloud server(eg. hetzner cloud vm(s)), can also be called thehostnomad agent: can be either nomadserverorclientclient:agentthat is responsible for “running”tasksserver:agentthat is responsible for schedulingjobsbased onallocation&groupto certainnodesthat are running aclient agent
Following the above terms, here are the guidelines
- Nomad is supposed to be HA and be quorum-based, i.e you run multiple
agentson differentnodes. (Preferably in different regions) - You’re supposed to run one
agent(server/client)in eachnode - You’re not supposed to run multiple
agenton samenode- Not supposed to run multiple
client agenton samenode - Not supposed to run multiple
server agenton samenode - Not supposed to run
server agentandclient agenton samenode(There’s demand around this)
- Not supposed to run multiple
- For true HA, there are certain recommendation around how many
server agent(s)should you run.
-
More on
client- A single
client agentprocess can handle running manyallocationson a singlenode, andnomad serverwill schedule against it until it runs out of schedulable resources
- A single
-
More on
server- The
serveritself is not managed. i.e If the server runs out of memory it’s not going to get re-scheduled etc.- So need to make sure we run the
serverin an environment where it can easily do what’s needed.
- So need to make sure we run the
- A
serveris light-weight. For a starting cluster, you could likely colocate aserverprocess with another application—clients less so because of the workload aspect. (But it depends on if you need HA)servercan run with other workloads(other selfhosted tools), evenconsul/vaultetc.
- The
Different topologies
-
single node nomad cluster
Run just one
node, it in, run bothclientandserver.On
dev-agentvs single node cluster- Nomad has something called
dev-agent, which is for quickly testing out nomad etc. It runs the server and client both in the same node.- This essentially means running the agent with
-devflag. - It enables a pre-configured dual-role agent (client + server) which is useful for developing or testing Nomad.
- This essentially means running the agent with
- Single Node nomad cluster is essentially the same as dev mode (-dev), but here we specifically specify that in our config and do not use the
-devflag.
-
Ways to do it
- With the -dev flag and a single agent 🚫
- It won’t save your data and it turns off ACLs
- With two agents using different ports. You could do this but additional hassle.
- With a single agent and both the client and server configs in the same config file
- This is the suggested way
- With the -dev flag and a single agent 🚫
-
Warnings & Issues
- It is strongly recommended not to run both
clientandserverin the same node - HA only at application level, not at
nodelevel- If we have 2
allocationof same app, in a single-node setup. If one allocation fails, we get the second up becauseserveris up and running and realizes that happened. But if thenodeitself goes down, then everything goes down.
- If we have 2
- Because we’ll be running just 1
client, drains and rolling upgrades will not work as documented because there is no place to move the active workload to.- TODO/DOUBT: I am not super sure about this one, why not just create another task on the same
node?
- TODO/DOUBT: I am not super sure about this one, why not just create another task on the same
- You can’t run more than one instance of a workload that uses static ports.
- Ideally in a nomad setup, you’d run
serveras non-root, andclientas root as it needs OS isolation mechanisms that require root privilege. But in a single node setup where you’re running client and server from the same agent with combined configuration we’ll run both as root and not provide anyUser/Groupdirective in the systemd file hence.
- It is strongly recommended not to run both
-
Issues
- I am getting this warning as-well: Nomad 1.4 Autopilot with only single server - Nomad - HashiCorp Discuss
- Nomad has something called
-
multi node but 1:1 server:client
- Run 3
nodes, run pair ofsever:clienton each.
- Run 3
-
Recommended topology
- See deployment docs
TODO Don’t understand / Doubts
- When we say 3
nodecluster, do we mean 3servers?- I am confused about if these ppl are talking about running
serverorclient. Given the assumption that we either runserverorclientonly in onenode/host
- I am confused about if these ppl are talking about running
- An even number of server nodes (outside of the case of a temporary failure) can make the raft cluster unhappy.
- If each client is isolated from the others though, then any number is fine :).
- Pro Tip Idea: be sure to specify a different node_class to the client on the nomad server.
- documentation recommends running client as root and server as nomad user?
- Does it mean that minimum nomad cluster requires minimum of 5 instances? 3 server + 2 clients?
Failure Modes
- clients losing their jobs
- servers losing quorum
Backup of nomad data?
https://mrkaran.dev/posts/home-server-nomad/
Other notes
- If you do not run Nomad as root, make sure you add the Nomad user to the Docker group so Nomad can communicate with the Docker daemon.
Single server nomad setup
In single nomad server cluster, state of the raft is the following, the server seems to be in follower state.
λ nomad operator raft list-peers
Node ID Address State Voter RaftProtocol
(unknown) 9ba36f29-1538-eb7e-3a1e-a24dfb805b21 100.124.6.7:4647 follower true unknownUnderstanding bootstrap_expect
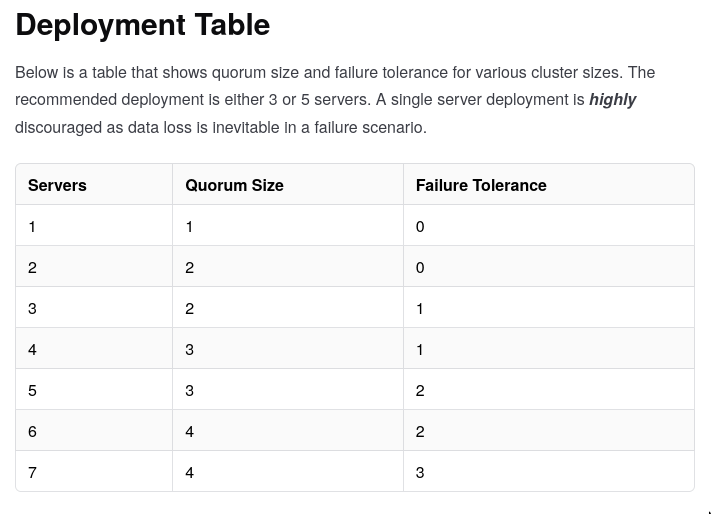
Quorumrequires at least ⌊(n/2)+1⌋ members. Once we haveQuorumwe can do leader election.bootstrap_expectjust makes the servers wait until there arenservers before it starts the leader election between these servers.- The deployment table in the docs is super useful but here’s a simplified summary
bootstrap_expect = 0: Not allowedbootstrap_expect = 1: Single node cluster, (self elect)bootstrap_expect = 2: 2 nomad servers, forms a quorum of 2 but no fault tolerance.- one server agent failing will result in the cluster losing quorum and not being able to elect a leader.
- without a leader,
- cluster cannot make state writes
- cluster cannot make any changes to the cluster state
- cluster cannot rescheduling workload
bootstrap_expect = 3: 3 nomad servers, we have a fault tolerant nomad quorum
- When does it get used
bootstrap_expectis used is when the server starts for the “very first time” and attempts to join a Raft cluster(that has not initialized yet)bootstrap_expectsetting has no effect, even on subsequent restarts of the server.
Understanding server-join
server-joinis both a config and cli param- In config it can be
start-join/retry-joinbased on usecase server-joinis how the nomad agent(server) will find the other nodes to connect to and validate againstbootstrap_expect
Migrating a bootstrap cluster (single node server)
-
v1 [THIS DID NOT WORK]
AFTER SOME EXPERIMENTATION, WE CONCLUDE THAT GOING THIS ROUTE IS NOT SAFE
- Have the existing cluster running with
bootstrap_expect=1 - Create a new host, add the following nomad server config. (It does not really need any client config)
server = { enabled = true; bootstrap_expect = 2; # must be 2, even if the original single node server has set it to 1 server_join = { start_join = ["<dns/ip of original bootstrap server>"]; }; }; - After the new server is up, we’ll see 2 servers in our nomad cluster. (This has quorum of 2 but no fault tolerance but it’s alright for us as we just need this as part of the migration)
- Comment out the
server blockin the “original single node server”- At this point everything should crash, nothing is supposed to work. Both old and new nomad severs will be down with different errors.
- Now change
- Old server
- the
bootstrap_expecton the new server to1.
- the
- New server
- TODO
- Old server
- Things should start working again
- Have the existing cluster running with
-
v2
- Steps
- Cleaup (If you’ve attempted v1)
rm -rf /var/lib/nomadif you messed up on the new server, never do it on the original server.umount -R alloc/*/*/*if needed
- Take the snapshot backup
export NOMAD_ADDR="http://$(ip -br -j a show tailscale0| jq -r '.[].addr_info[] | select(.prefixlen == 32).local'):4646"nomad operator snapshot save nomad_state.backup(old server)
- Run the new server as an individual
bootstrap_expect=1- No need to have any relation with older server yet,
- Restore
nomad operator snapshot restore test_nomad.backup(new server)- Copy over the keyring from the working server/backup to
/var/lib/nomad/server/keystoreaswell to the same location in new server. (You’d now have two keystore files) - Then do:
nomad operator root keyring rotate --fullso that you don’t have to maintain older keys. sudo systemctl restart nomad- You can delete the old keys from the keystore now.
- Make old clients point to new nomad sever (including old nomad server)
- The
serverfield inclientblock takes care of this
- The
- Now everything should be set
- Cleaup (If you’ve attempted v1)
- Steps
Fault Tolerance in Single Cluster Nomad
-
Availability
- An available system will also be recoverable
-
Recoverability
- After a fix, the system has recover making sure correctness is ensured
- Eg. WAL helps with this
Autoscaling Nomad Clients (AWS/others)
- Boot time is the number one factor in your success with auto-scaling. The smaller your boot time, the smaller your prediction window needs to be. Ex. If your boot time is five minutes, you need to predict what your traffic will be in five minutes, but if you can boot in 20 seconds, you only need to predict 20 seconds ahead. By definition your predictions will be more accurate the smaller the window is.
- https://depot.dev/blog/faster-ec2-boot-time
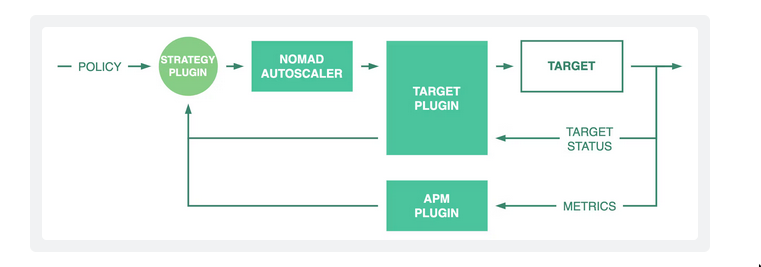
- https://developer.hashicorp.com/nomad/tools/autoscaling/concepts
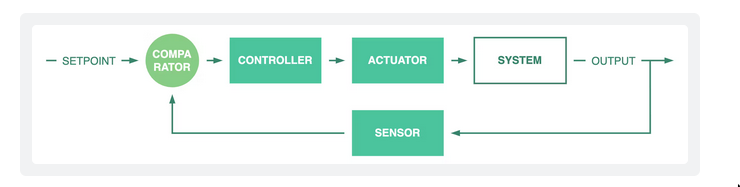
- The Nomad Autoscaler is modeled around the concept of a
closed-loop control system. - Components
autoscaling policy- How users define their desired outcome
- control the Nomad Autoscaler.
Target- What users want to scale.
- Eg. job group/allocations/Nomad clients(eg. EC2)
Strategy plugins- receive current status of the target
- compute what actions need to be taken.
Target plugins- communicate with targets: Read/Write(mutate state, eg. increase ec2 count)
APM plugins- read application performance metrics from external sources.
- Concepts
Node Selector Strategy: mechanism the Nomad Autoscaler uses to identify nodes forterminationwhen performing horizontal cluster scale-in actions.
- Resources
autoscaler config
- config file
- .. other config
- Registering plugins
- Since plugins are of 3 kinds:
apm,strategyandtarget - We have blocks in the top level autoscaler config with the same blocks.
- These plugins can be then used as per need in the different policy files.
- Since plugins are of 3 kinds:
- points to policy file
- policy file
- referred from the config file
- The
scalingblock (see scaling Block)- Can be specified as file pointed by the autoscaler config
- Can also be a block in a normal nomad jobspec!
- But the
scaling:policyblock is parsed by the nomad-autoscaler only even if it’s defined in the jobspec.
- But the
- What goes in the block depends on “what you’re scaling”: application/node(cluster)/ or dynamic thingy
- Two main thing are
checkandtarget:node_selector_strateg. They determine when things scale and when things die respectively.evaluation_intervalis what determines how ofter this policy is evaluated/checked
- A
policycan contain multiplecheckchecksget executed at time ofpolicy evaluation
checkdetermine ascaling suggestion(can be one or more)metric sourcestrategyto apply based onmetric source“outcome”- If multiple outcomes, one is picked based on some rules. Mostly it’s
ScaleOut
outcomeScaleIn: Vertical Scaling,ScaleOut: Horizontal scaling.- See Scaling Databases
target:node_selector_strateg: How things are terminated
Gotchas
-
Application autoscaling vs Cluster autoscaling
- See Getting to know the Nomad Autoscaler - #6 by lgfa29 - Nomad - HashiCorp Discuss
- Application autoscaling will live in the jobspec
- Cluster autoscaling should live in its own file and be linked to the nomad-autoscaler config
Plugins
- https://developer.hashicorp.com/nomad/tools/autoscaling/concepts/plugins
- There are some default plugins for each, otherwise u can custom make stuff
| What? | Description | Context |
|---|---|---|
| APMs | This will query some API for status of the system. Eg. expected state of the system etc. | This becomes the source in the check block |
| Strategies | Implement the logic of scaling strategy. Compares AMP value and Target value and decides. | result is the outcome (ScaleIn/Out/None etc) |
| Targets | Get info about the status of the target and then make changes to the target too | Eg. make changes to aws ASG |
Learning resources/Doubts
Ongoing ref
- https://github.com/mr-karan/homelab/blob/master/docs/SETUP.md
- Caddy
- We’ll need to use static port in network
- To read tutorials
Concepts
Nomad Cluster on Production
- Main prod ref: Nomad deployment guide | Nomad | HashiCorp Developer
- Involves consul, we need to figure if we need consul
- Nomad reference architecture | Nomad | HashiCorp Developer
- Nomad clusters on the cloud | Nomad | HashiCorp Developer
- https://github.com/hashicorp/learn-nomad-cluster-setup
- Think because we’re using nixos, lot of tf boilerplate that this repo has is things we don’t need
- But we do have to think about ACL and consul tough
- https://github.com/hashicorp/learn-nomad-cluster-setup
- How We Develop and Operate Pirsch - Pirsch Analytics
- Deploying Nomad on NixOs | Heitor’s log
- My NixOS + Nomad Dev Environment
ACL
What are the different tokens?
Service Discovery
- Task Dependencies | Nomad | HashiCorp Developer
- https://developer.hashicorp.com/nomad/docs/integrations/consul
- Do we need consul? or native service discovery enough?
- When is the native service discover not enough?
- Examples
- Nomad 1.3 Adds Native Service Discovery and Edge Workload Support