tags : Database, Distributed Systems, System Design
- Scaling vertically means something totally diff. compared to sharding vertically. Something to keep in mind.
| Sharding | Partitioning | Scaling | |
|---|---|---|---|
| Horizontal | One that uses row-partitioning(more talked about) | row-partitioning | Scale out(shard) |
| Vertical | One that uses column-partitioning(usually application specific) | column-partitioning, similar to normalization | Scale up(beef up) |
- Eg. Figma had to pick between horizontal sharding vs vertical partitioning
Scaling
Things to consider before you scale
Notes
- Indexes and replications make lookup/reads easier but can cause difficulties with writes
- Query logs, slow queries, optimize?
- Schema change? Poor design?
- What kind of load are we dealing w, read or write?
- Indexes? Indexes speed up reads, but slow down writes
- Do we need additional caching before DB layer?
- Batch writing?
- If data is not immediately needed, can we queue it?
- If load is read heavy, will replication help? (be aware of complicated writes)
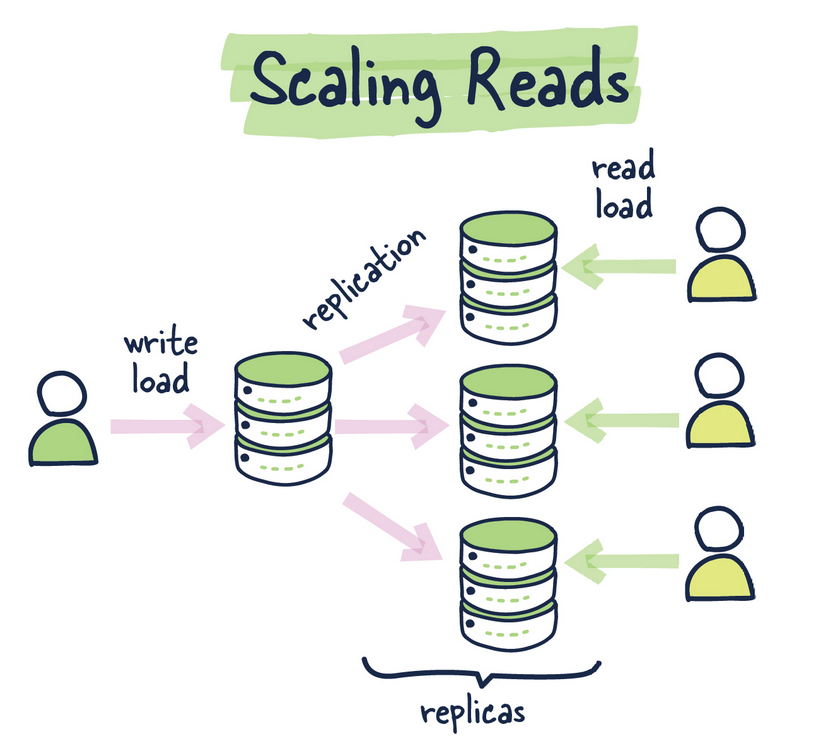
- Basically try all the performance optimizations you can do
You are sure that you need to scale things.
You’ve tried all performance optimizations, nothing seems to meet your needs. It’s time to scale up/out.
Scale up (Vertical)
- Increasing capacity of server
- It’s easier to scale up than scale out.
Scale out (Horizontal)
- This is basically sharding ( sharding is the last resort )
- Sharding is an example of horizontal scaling
- Because RDBMS are designed to run on a single machine, sharding takes some effort and it’s not something to do casually.
- It changes the kind of queries you can run. In an existing project, sharding would very likely break things.
Sharding
- Read
- It’s a concept related to distributed systems(different machines) and uses the ideas of database partitioning in dist sys setting.
- Because this results in smaller tables it’ll most likely improve performance etc(at the db layer atleast).
- Vitess(MySQL) and Citus(PostgreSQL) can help you shard v/s sharding manually.
- You also have databases and services that do sharding for you (Eg.cockroachDB, planetscale, dynamo, cassandra, yugabytedb, spanner etc.)
What it involves?
Decide on a sharding scheme
- What data gets split up, and how? How is it organized?
- Considering which tables are stored together because JOINs across systems is costly.
Organize your target infrastructure
- How many servers are you sharding to? How much data will be on each one?
- You would want to optimize for flexibility
Create a routing layer
- How does your application know where to store new data, and query existing data?
- This usually is implemented in the application layer, can be relatively simple and stored in a JSON blob, config file, kv store etc.
Planning and executing the migration
- How do you migrate from a single database to many with minimal downtime?
- Migration strategy can be business specific but a rough idea can be something like
- Double-write: Incoming writes get applied to both the old and new databases.
- Backfill: Once double-writing has begun, migrate the old data to the new database.
- Verification: Ensure the integrity of data in the new database.
- Switch-over: Actually switch to the new database. This can be done incrementally, e.g. double-reads, then migrate all reads.
Partition strategies
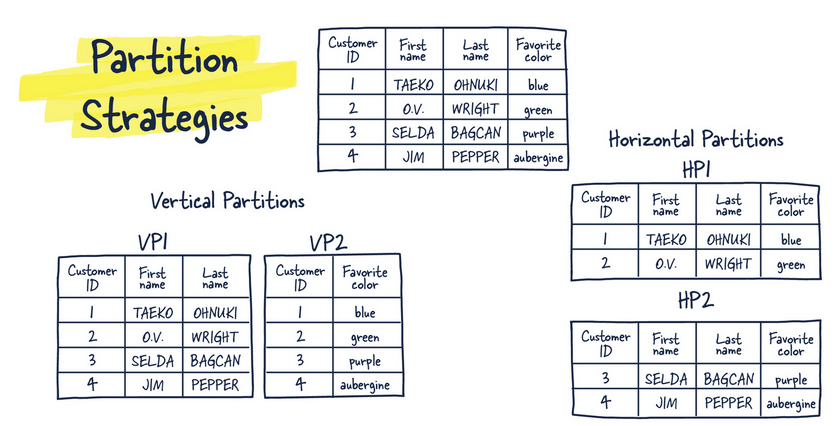
Horizontal/Row partitioning
- Split things at the row level based on certain attributes of the content of the row(See schemes).
Vertical/Column partitioning
- Split things at the schema/table/column level.
Shard key and shards
- Shard Key is a piece of the primary key that tells how the data should be distributed.
- The same node houses entries that have the same shard key.
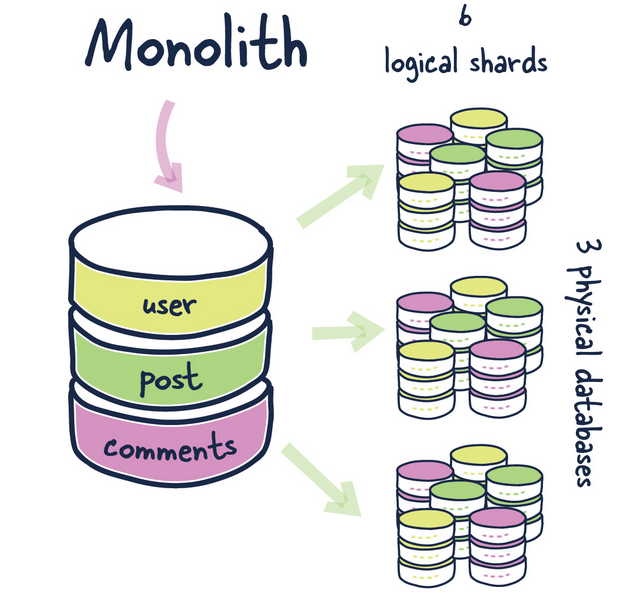
Physical shard
- The database node is also called the physical shard
- Multiple logical shards are included in a database node, also known as a physical shard.
Logical shard
- Each small table is called a logical shard.
- A logical shard can only span one node because it is an atomic unit of storage.
Sharding Scheme
- The outcome of a scheme is that it gives you a
shard keywhich you can use to do database operations on. - The strategy can be very specific to the organization/business
- There are some popular thinking frameworks like hash, range, directory based etc. (These are mostly
vertically-partitioned-sharding-schemes)
Hash based/Key based
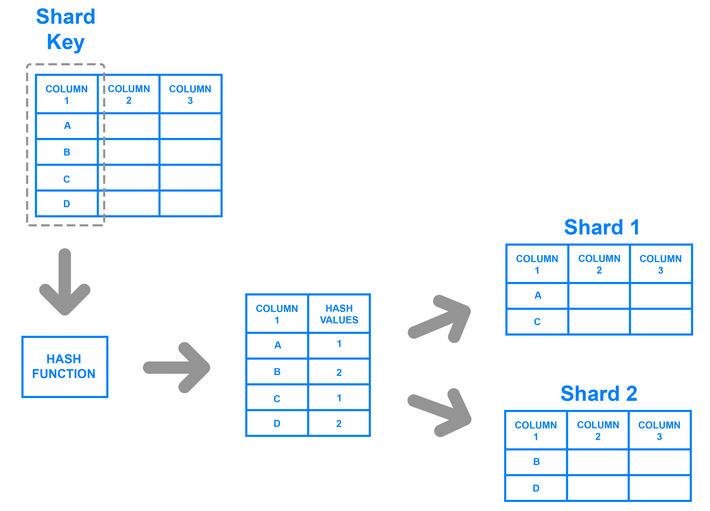
- Eg. Normal hash-table like strategy to distribute the load
Range based
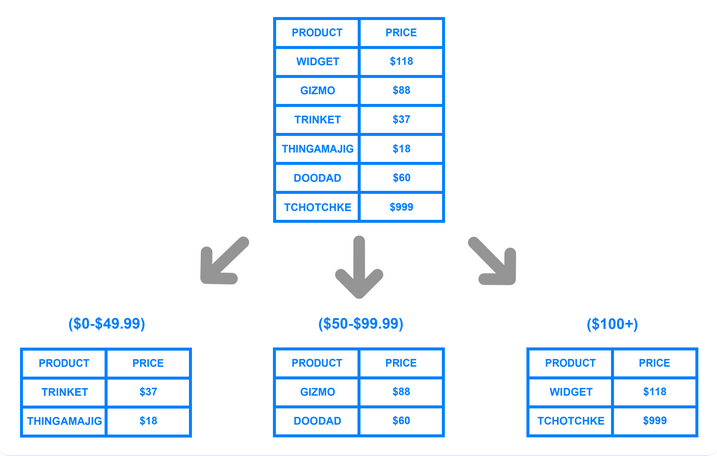
- Divides the data into rows based on a determined key or range of values.
- Eg. How notion sharded based on teamID
Directory based
- Eg. Sharding based on organization, like how Clarisights would do it.
Cross-shard/Global transactions
- Usually you want to avoid cross shard stuff by keeping related tables in the same node.
- But you can’t always avoid global transactions. i.e multiple sub-transactions(across shards) need to coordinate and succeed.
- The secret to performant manual sharding is to figure out a way to minimize JOINs across shards
- One solution is 2PC (2 Phase commit)