tags : Cryptography, Security, Database, PostgreSQL
FAQ
short uuid?
- These are basically encodings. Eg. You could base62 encode a random number.
- Under the hood, it’s uuid data only referring to the 4122RFC.
- But the string representation is independent can be base32/64 whatever.
- Short uuids and similar are nothing but different string representations.
- Eg. nanoid, squid etc.
millisecond?
- It’s better not to store the exact millisecond an ID was generated, but instead fuzz the nearest second and add a counter.
Types
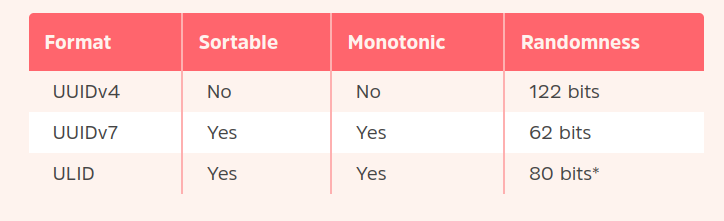
timestamp based id
- ids generated at the same time are close to each other when sorted
- Eg. UUIDv7, ULID, ksuid, xid
sequential Ids
- Incremental IDs etc.
random ids
- UUIDv4
non-coordinated unique ids
- These are useful in Distributed Systems
UUID
What
- Generated via random or time-based means
- 128-bit label value (expressed as 32 hex-characters)
5 sectionscontaining 32b, 16b, 16b, 16b, and 48b93f9a654-7467-46de-9964-f30a66104dd9
Variants
Original RFC
See RFC 4122
-
v1: computer’s MAC
-
v2: guaranteed to be unique if at most one is generated per computer about every 7 minutes
-
v3: deterministic based on the supplied input
-
v5: deterministic based on the supplied input
-
v4: non-deterministic UUIDs. (this is usually what ppl refer to)
- version and variant is fixed. variant can only be
8 (1000), 9 (1001), a (1010), or b (1011) - These are great when we want to split on random keys, but not great for btree performances like clustered indexes etc.

- version and variant is fixed. variant can only be
Draft
See draft-peabody-dispatch-new-uuid-format-04. These use time bits + random bits. With these, you get the same sortability as a sequential ID with the flexibility of distributed generation. (sorting at creation time!)
- v6: time bit is set by something else
- v7: time bit is set by unix epoch
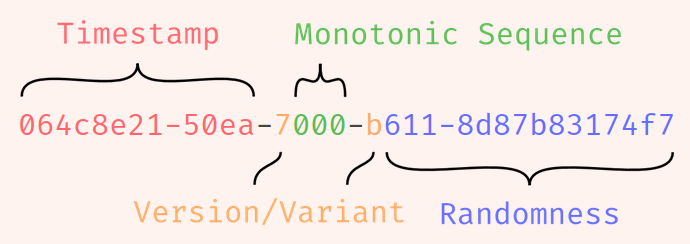
- If you can configure how precise you get.
More precision => Less random bits - UUIDv7 generated now is always going to be larger than a UUIDv7 generated a millisecond ago.
- The
timestamp+monotonic seq. counteris only relevant for UUIDs generated on the same machine within thesame millisecond- it will not ensure ordering if they’re generated in diff machines in the
same millisecond 061ff8d8-e24b-7000-8092-ca1e5440d491and061ff8d8-e24b-7001-b653-1c41e471cd78are 2 uuids generated in thesame millisecondso we have the change in the monotonic seq. counter.
- it will not ensure ordering if they’re generated in diff machines in the
- If you can configure how precise you get.
- v8: time bit is set by something else
ULID
What
 Unique Lexicographically Sortable Identifier
Unique Lexicographically Sortable Identifier
- Not an RFC but spec can be found here
- A ULID is a 128-bit label, just like a UUID.
- Instead of hexadecimal in UUID, ULID uses Crockford’s Base 32 encoded string.
- Eg.
017eb31e-1440-b69e-d82f-5f0937f823c8(hex) ->0GWWXY2G84DFMRVWQNJ1SRYCMC(crockford)
- No special characters (URL safe)
- ULIDs are monotonically increasing like
UUIDv7but there’s no defined monotonic counter. They have seq random sections.- Eg.
017ece40-2a1e-63ac-a58d-e336f30c1d76and017ece40-2a1e-63ac-a58d-e336f30c1d77, 2 ULIDs generated in same millisecond.
- Eg.
Concerns
- Guarantees ordering up to millisecond precision.
- Most implementation additionally guarantee ordering of the 80 random bits for absolute ordering but only IN PROCESS.
- If you have many clients concurrently producing data and generating ULIDs you can run into out-of-order rows.
- One use case of ULIDs is as event IDs in distributed systems.
- BUT ULIDs are not meant as a replacement for a lamport timestamp or something.
- Atleast with PostgreSQL, ULIDs are slower to generate than UUIDs.
Other variants
- https://lu.sagebl.eu/notes/implementing-lock-free-snowflake-id-generator/
- https://en.wikipedia.org/wiki/Base32#z-base-32
- https://code.lag.net/robey/nightcoral/src/branch/main/src/slid.ts
Other schemes
ksuid
- uses 160 bits. A 32-bit timestamp and then 128 bits of random-based payload.
- sortable via its string representation as well.
xid
- iteration on Mongo’s ObjectId
squid
- Sqids (formerly Hashids) · Generate Short IDs from Numbers
- These IDs are short, can be generated from a custom alphabet and are guaranteed to be collision-free.
- Main usecase is purely visual. Can be hashed back.