tags : Database, Systems, Data Structures
FAQ
Are indexes only for performance?
- Not necessarily
- Sometimes they can be used to hold strict constraints like uniqueness constraints etc.
Ordered indexes(eg. B+trees) v/s hash tables?
-
See Why databases use ordered indexes but programming uses hash tables
-
Some day Btrees are better for disk and hash table better for in-memory, but this is NOT fundamental property and is very contextual
-
Persistent data has different needs than in-memory data.
-
In databases, we tend to use ordered indexes because they’re more general hence can support large variety of operations.
-
Hash Table(See Data Structures) v/s Trees
Lookup Ordering Range Ops( topk/starts_with)Spatial Locality Hash Table (avg, can get worse) Unordered Need to scan entire table No spatial locality Trees Shit’s ordered Ez, can do, cuz ordered Can prefetch!
How are tables stored? and how are indexes stored?
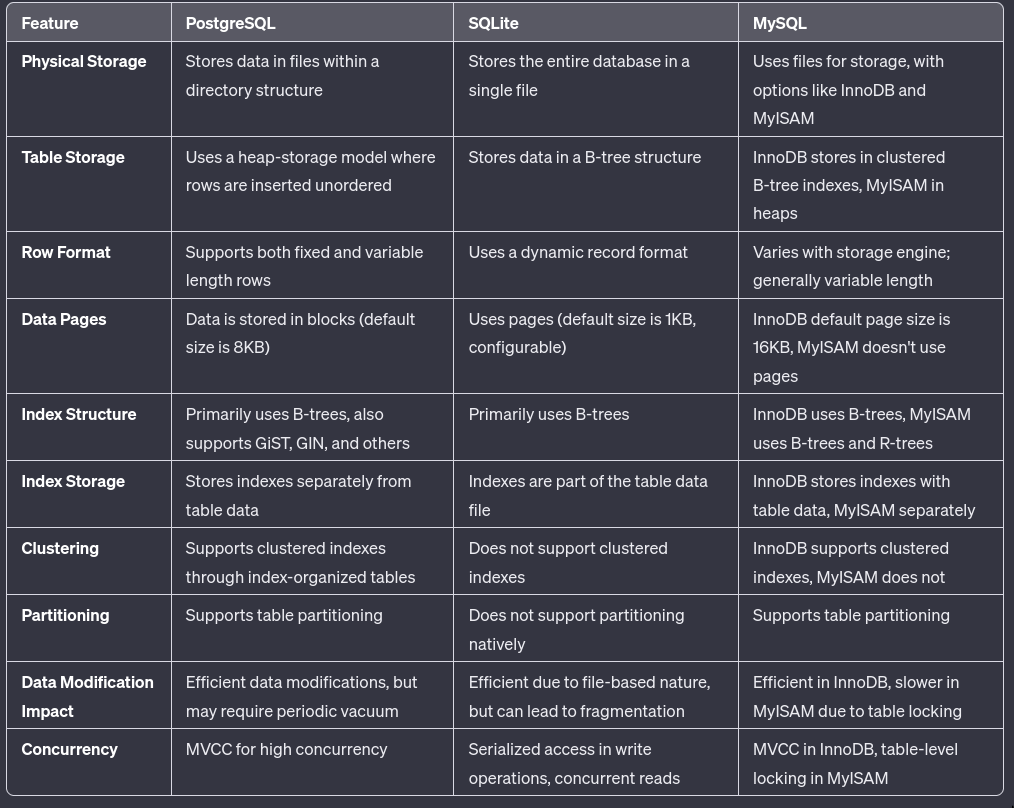
- Table generated by GPT4^
- InnoDB is similar to SQLite all tables are clustered indexes
- If you don’t have suitable primary key it creates a hidden one similar to
rowidin SQLite.
- If you don’t have suitable primary key it creates a hidden one similar to
- PG only has unordered heaps, indexes are always secondary data structures. PG could really use true clustered indexes as an option.
- MS-SQL and Oracle give you a choice for table storage to either have unordered heaps or ordered b-trees, depending on whether a clustered index is defined.
Query planner, selectivity, statistics and index
- Assume we need to answer, Which index to use when doing query if we have index on
nameandaddresscolumn? This needs context. The querry planner tries its best to answer this, else we(hoomans) chime in. - Sometimes even after having an index, it query planner might just choose not to use the index if the performance would be same as a sequential scan
On uuid v4 and Indexes
uuidv4 is random and should not be used for indexes because
- they’re random and indexes are meant to be ordered based on the specific implementation
- If we’re adding new items to the index and they’re random, we’d need to balance/re-order the index on each insert to the index
- this causes thrashing which is bad for performance
Indexes and Foreign keys
- In PostgreSQL, indexes are not created on FK(s) on the referencing(child) side, but it’s suggested to do so.
- See DB Data Modeling
Best practices for Tuning
- Performing index tuning must be done on production, or on a staging environment that is as close to production as possible. Doing index tuning locally might not even use index depending what the query planner thinks etc.
- Ordinary
CREATE INDEXcommands require a lock that blockswritesbut notreads. Prefer usingCONCURRENTLYwhich can take longer but will not lock. - When using
REINDEX, One strategy to achieve the same result on a live site is to build an index concurrently on the same table and columns but with a different name, and then drop the original index and rename the new one. This procedure, while much longer, doesn’t require any long running locks on the live tables. (From Heroku)
Types
Based on structure
Clustered Indexes
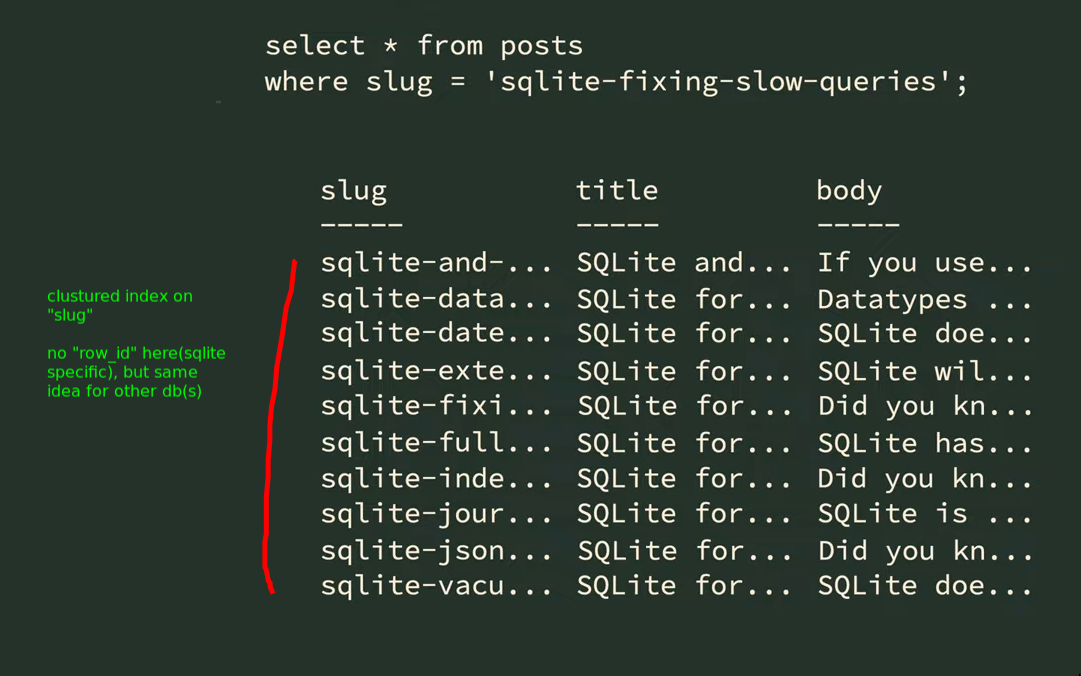
- A table can only have one clustered index.
- This physically changes the storage of the data in long term memory
- The column you index with becomes sort of the primary key
- Different databases have their own ways. sqlite has
WITHOUT ROWID, PostgreSQL usesCLUSTERcommand etc.
Non-Clustered/Standard/Regular Indexes
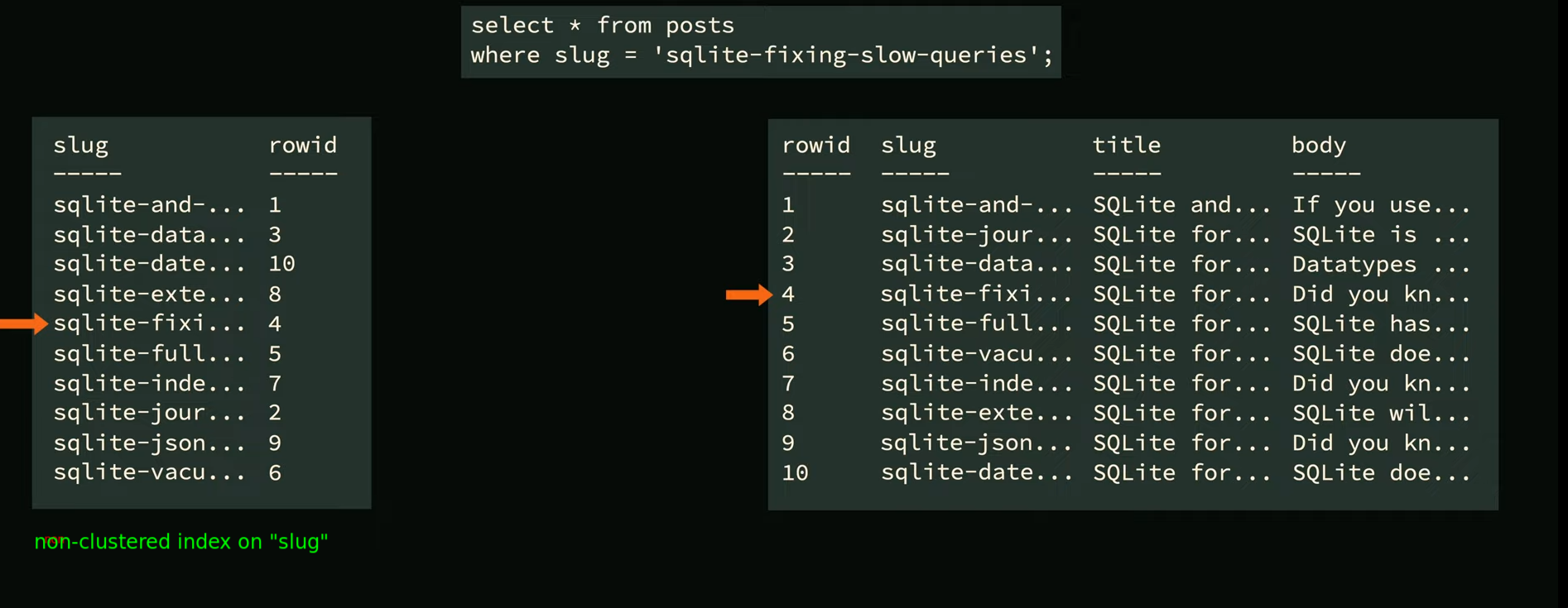
- A non-clustered index is a separate/secondary index that references back to the original data(primary key at the leaf)
- In some DBs the secondary index is part of the table instead of begin a separate entity, but this is implementation detail.
Based on number of columns/indexes
Based on usecase, we might need to create both.
Multi-Column Indexes (AND)
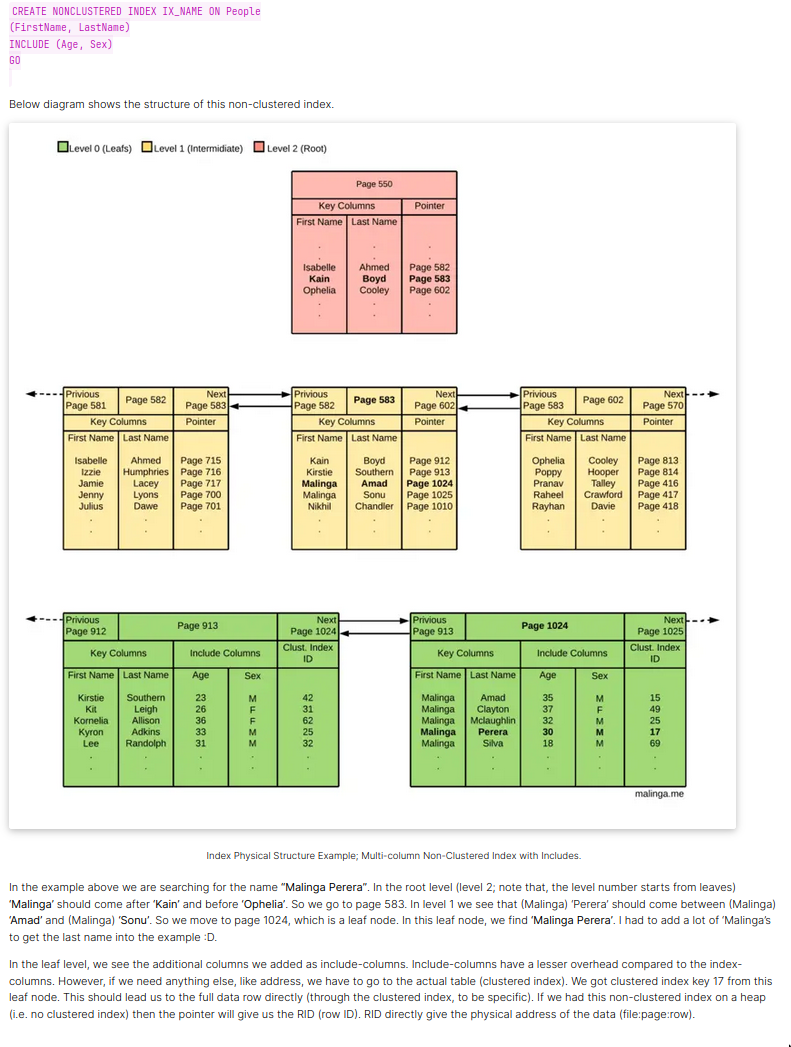
- This uses multiple columns but results in a single index.
- Index gets used when you have
ANDin the query. - An example
- Index on a table defined as
(col1, col2, col3) - A query filtering on
col1can efficiently use this index. - A query filtering on
col1andcol2(in that order) can also use it effectively. - However, a query filtering just on
col2or oncol2andcol3cannot fully utilize this index, as thecol1is not used in the query.
- Index on a table defined as
- Most efficient when there are constraints on the leading (leftmost) columns.
- In PostgreSQL, only the B-tree, GiST, GIN, and BRIN index types support multiple-key-column indexes. Upto 32 columns but can be altered.
- When writing query the order of the columns
AND‘ed don’t matter (NEED TO CONFIRM)
-
Composite/Compound Indexes
- Eg.
INDEX(last_name, first_name)
- Eg.
-
Covering Indexes
- These are not necessarily multi-column indexes, you can make covering indexes with single columns also but it’s mostly multicolumn in its usecase.
- Multicolumn example:
INDEX(last_name, first_name, address) - The query must reference only columns stored in the index.
- Not all indexing methods support covering indexes, Btrees do.
- In PostgreSQL it also has to do something with MVCC. i.e significant fraction of the table’s heap pages have to have their all-visible map bits set for this to be useful.
- In PostgreSQL, you use
INCLUDEfor this. BeforeINCLUDEpeople just tried to hack their way to introduce an extra playload using multicolumn indexes. - Unique index on covering index
-- uniqueness condition applies to just column x -- not to the combination of x and y CREATE UNIQUE INDEX tab_x_y ON tab(x) INCLUDE (y);
Multiple indexes (OR/AND)
- This is not really a index type, just a situation where you have multiple standard indexes.
INDEX(first_name), INDEX(last_name)
Based on constraints
Unique Indexes
- Can be combined with: [
Multi-column indexes,Partial indexes] - Only B-tree indexes can be declared unique.
- Any attempt to insert a duplicate value results in an error. If creating on exiting column it should throw error if there exists duplicates.
- PostgreSQL has
UNIQIEconstraint also creates a unique index on it automatically - See NULL in SQL
Based on conditions
Partial Indexes
- Index on a subset of a table. using the
WHEREclause. - The subset is defined by a condition(
predicateof the partial index) - Because it’s only on a subset of the table, it’s usually smaller and overall results in faster updates
- Basically helps in not making an index on values of a table that we’re probably not going to query that much anyway
- Such partial indexes are best used for data distributions that do not change.
- Matching takes place at query planning time(compile time), not at run time. NO PARAMETERIZED
- As a result, parameterized query clauses do not work with a partial index.
- As replacement in parameterized query happen at run/execution time. (See SQL)
- NOT AN SUBSTITUTE FOR PARTITION (See 16: 11.8. Partial Indexes)
- Can also be used to override the system’s query plan choices
-
Example/Usecase of partial index
- Exclude common/uninteresting values: Table has public and private IPs, but you only query public IPs. So you can have an index only on those which are public IPs.
- Querying on a different column but indexing on another
CREATE INDEX orders_unbilled_index ON orders (order_nr) WHERE billed is not true; -- index is used fully SELECT * FROM orders WHERE billed is not true AND order_nr < 10000; -- in the following even if index is not in amount, the index will help -- partially. i.e does a full scan for "amount" SELECT * FROM orders WHERE billed is not true AND amount > 5000.00; -- index does not get used -- query planner doesn't know if result is even in the index because no WHERE clause -- so it skips using the index SELECT * FROM orders WHERE order_nr = 3501; Unique indexover a subset of a table- Enforces uniqueness among the rows that satisfy the index predicate
- Setting up a partial index indicates that you know at least as much as the query planner knows
partial+unique+multicolumnindex can also be made
Index on expression
SELECT * FROM test1 WHERE lower(col1) = 'value';
CREATE INDEX test1_lower_col1_idx ON test1 (lower(col1));- Index column can be a function or scalar expression computed from one or more columns of the table.
- Fast access to tables based on the results of computations.
- Unique index also can be set on this, will enforce the uniqueness of the computation
COALESCEIndex- This is just an example of using expression index
- Eg.
CREATE INDEX idx_test ON testtable(COALESCE(col1, col2));
Index Access methods
See PostgreSQL: Documentation: 16: 11.2. Index Types
B+tree
- See Trees
- Fetching ‘consecutive’ (according to the index) items from a BTree is very efficient because they are stored consecutively.
- A BTree lookup is quite fast and efficient. For a million-row table there might be 3 levels of BTree, and the top two levels are probably cached.
- B-tree indexes can be used for equality and range queries efficiently.
- B-tree indexes are optimized for when a row has a single key value.
GiST
Hash
BRIN
- BRIN index might need a bit of a stronger disclaimer, as far as I understand you really want to use that only for ordered data, and in those cases it is exceptionally good at its job. But it is a lot worse if that condition is not met.
- BRIN is generally useful for datasets that have high local correlation.
Bloom
- A traditional btree index is faster than a bloom index, but it can require many btree indexes to support all possible queries where one needs only a single bloom index.
- Note however that bloom indexes only support equality queries, whereas btree indexes can also perform inequality and range searches.
Scan Types
Full table scan
- Scan that happens when there’s no index
Single index scan
- Regular index scans
- Each row retrieval requires fetching data from both the index(btree) and the heap(table).
Index only scan
- Using
Covering Indexes
Multi index scan
- This is related to
Multiple indexes - This also using the same index multiple times if needed
- Eg. A query like
WHERE x = 42 OR x = 47 OR x = 53 OR x = 99could be broken down into four separate scans of an index onx - To combine multiple indexes
- System scans each index and prepares a bitmap in memory
- Bitmap contains locations of table rows that are match index’s conditions.
- The bitmaps are then
ANDedandORedtogether as needed by the query.