tags : Distributed Systems, Database Locks, Concurrency
What?
- MVCC is not a Concurrency control method, It’s a technique to achieve Reader/Writer non-locking behavior, we operate on multiple versions of the same record
- MVCC itself is an umbrella term for its variants (types). MVCC can be combined with concurrency control mechanisms which can be implemented.
- The DBMS maintains multiple physical versions of a single logical object in the database:
- If a DB decides to use MVCC, then it’ll dictate how the DB handles transactions
- Can support time-travel queries
Main Idea of MVCC
- Readers don’t block Writers
- Writers don’t block Readers
- When a txn writes to an object, the DBMS creates a new version of that object.
- When a txn reads an object, it reads the newest version that existed when the txn started.
- If 2 txns update the same object/row, then first writer wins. Other rollsback.
History
- First proposed in 1978 MIT PhD dissertation.
- First implementation was InterBase (Firebird).
- Used in almost every new DBMS in last 10 years.
Types of MVCC
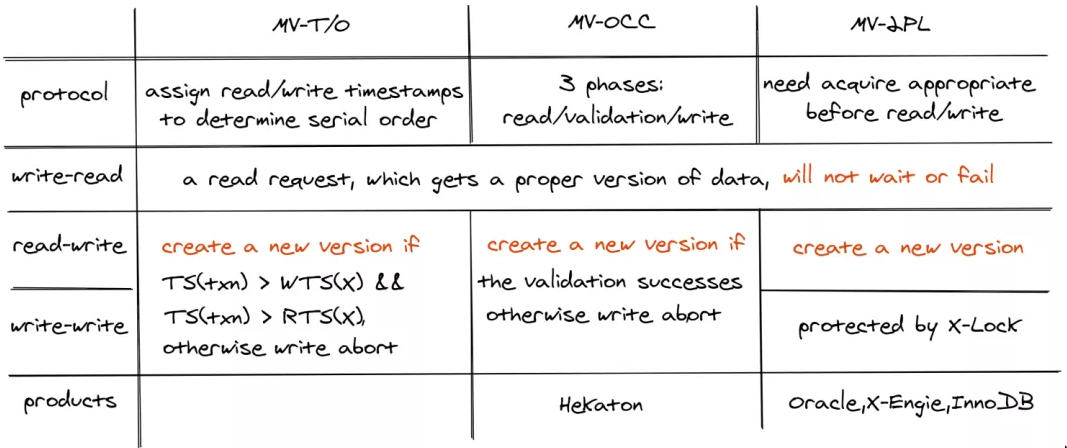
Timestamp Ordering (TO / MVTO)
- Assign txns timestamps that determine serial order.
- Considered to be original MVCC protocol
- This is what PostgreSQL uses
Optimistic Concurrency Control (OCC / MVOCC)
- See Database Locks
Two Phase Locking (2PL / MV2PL)
Version Storage
Append-Only Storage
New versions are appended to the same table space. (What PostgreSQL uses)
-
Version Chain Order
Basically a singly linked-list.
- Oldest-to-Newest
(O2N)- Just append new version to end of the chain.
- Have to traverse chain on look-ups.
- PostgreSQL uses
O2N - See The part of PostgreSQL we hate the most | OtterTune
- Newest-to-Oldest
(N2O)- Have to update index pointers for every new version.
- Don’t have to traverse chain on look ups.
- Oldest-to-Newest
Time-Travel Storage
Old versions are copied to separate table space.
Delta Storage
- The original values of the modified attributes are copied into a separate delta record space
- Txns can recreate old versions by applying the delta in reverse order
Indexes
- See Database Indexing
- Now with the version chain order, we can get to the version we need.
- But indexes need to point to the tuple aswell.
- Handling indexes is again involves thinking how MVCC is implemented
Primary key index
- PKey indexes always point to version chain head.
- How often the DBMS has to update the pkey index depends on whether the system creates new versions when a tuple is updated.
- If a txn updates a tuple’s pkey attribute(s), then this is treated as an DELETE followed by an INSERT.
Secondary Indexes
- Logical Pointers
- Use a fixed identifier per tuple that does not change.
- Requires an extra indirection layer.
- Primary Key vs. Tuple Id
- Physical Pointers
- Use the physical address to the version chain head.
Different Implementations
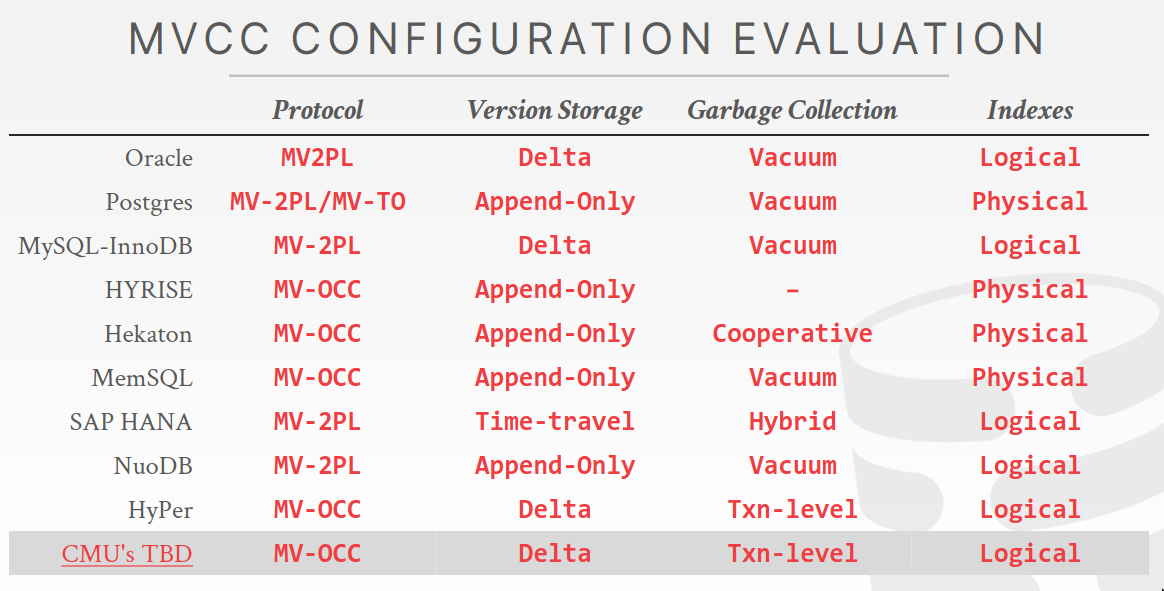 Implementations differ in Types/Storage/Version chain order etc etc.
Implementations differ in Types/Storage/Version chain order etc etc.
- Oracle
- undo log
- maintained separately
- PostgreSQL, Spanner use MVCC to see a snapshot(an older version of the database)
MVCC Implementation in PostgreSQL
- See Database Transactions and MVCC
- In PG due to its MVCC implementation,
UPDATEto one field in the row means updating the whole row. See 16: 73.7. Heap-Only Tuples (HOT) - PG handles transaction isolation by using MVCC to create a concept called
snapshots - One logical row, but can have like multiple physical versions
- Even if a row is
DELETEed, MVCC will store the older version in the same table. Just we won’t be able to see it. Later Vaccum will clean it. - PostgreSQL maintains this guarantee even when providing the strictest level of transaction isolation through the use of an innovative Serializable Snapshot Isolation (SSI) level. (See Concurrency Consistency Models)
Lifecycle
- A query(r/w) starts with a transaction
- Sees snapshot of the current state of the database. (visibility depends on isolation level, following is
read committedlifecycle)- If
readquery- There will be no
txid, onlyvtxid - Sees only data committed before the query began. If data was deleted by another transaction concurrently, it’ll still see that data because
snapshot - Never sees either uncommitted data/changes committed by concurrent transactions
- Does see the effects of previous updates executed within its own transaction (committed/uncommitted)
- There will be no
- If
writequery- Now the transaction is assigned a
txid - Record that’s being deleted/updated is still retained an version
- When trying to write the data it’ll either commit or rollback based on
xmin,xmaxvalues and other hints.
- Now the transaction is assigned a
- If
Visibility
-- think of this implicit WHERE on every row/tuple
-- every row will have xmin
WHERE xmin <= txid_current() AND (xmax = 0 OR txid_current() < xmax)Transactions
| Read-Only | Read-Write | Wrap Around Issue | |
|---|---|---|---|
| vtxid | Present | Present | No |
| xid | NULL | Present | Yes, Needs VACUMM |
Virtual Transaction ID (vtxid / vxid)
- Temporary identifier assigned to each session or backend that starts a transaction.
backendID+localXID:4/1234
- Useful in deadlock detection.
- Does not need vacuum :)
Transaction ID (txid / xid)
- Assigned to a transaction only where there is “write”
- Earlier transactions having smaller txids(so can be compared)
- xid are used as the basis for PostgreSQL’s MVCC concurrency mechanism
-
Circular
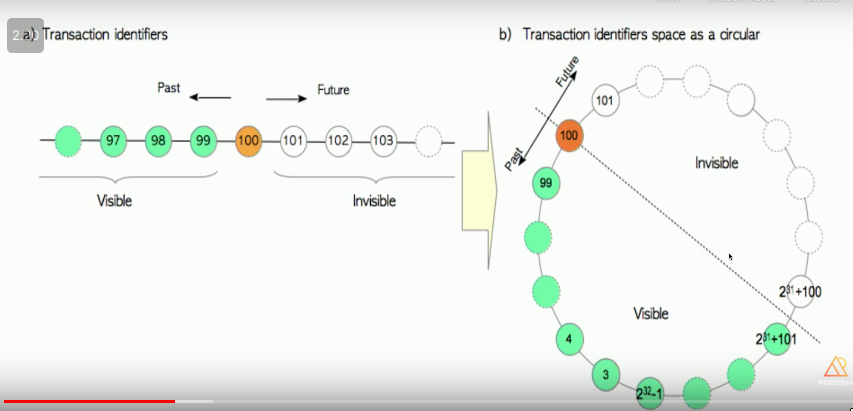
- 32bit: 2^32-1 : ~4.2bn
- 2bn in the past are visible, 2bn in the future are not visible
-
0,1,2 are reserved
- 0: Invalid/Nothing happened
- 1: Initialization of cluster
- 2: Frozen txid
-
System Columns

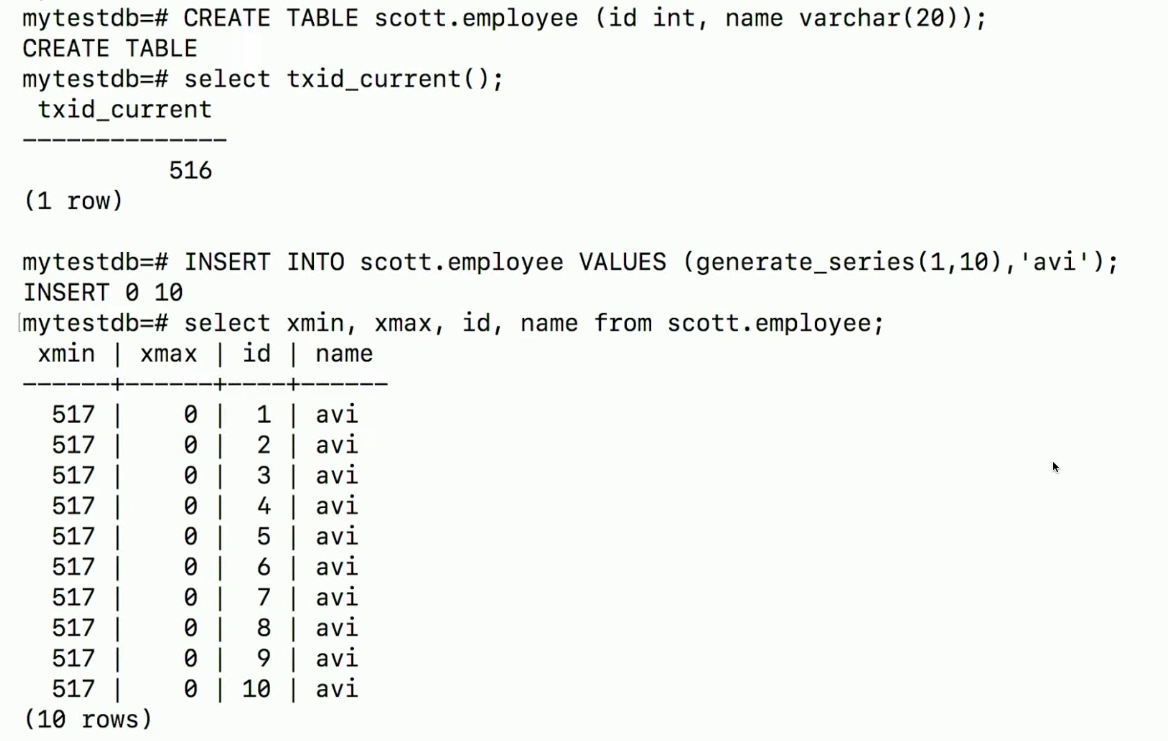
-
xmin
txidthatINSERT‘ed the tuple- In case of
UPDATE(UPDATE=DELETE+INSERT)xminwill be of thetxidthatUPDATED‘ed the tuplexmaxwill be set to 0
-
xmax
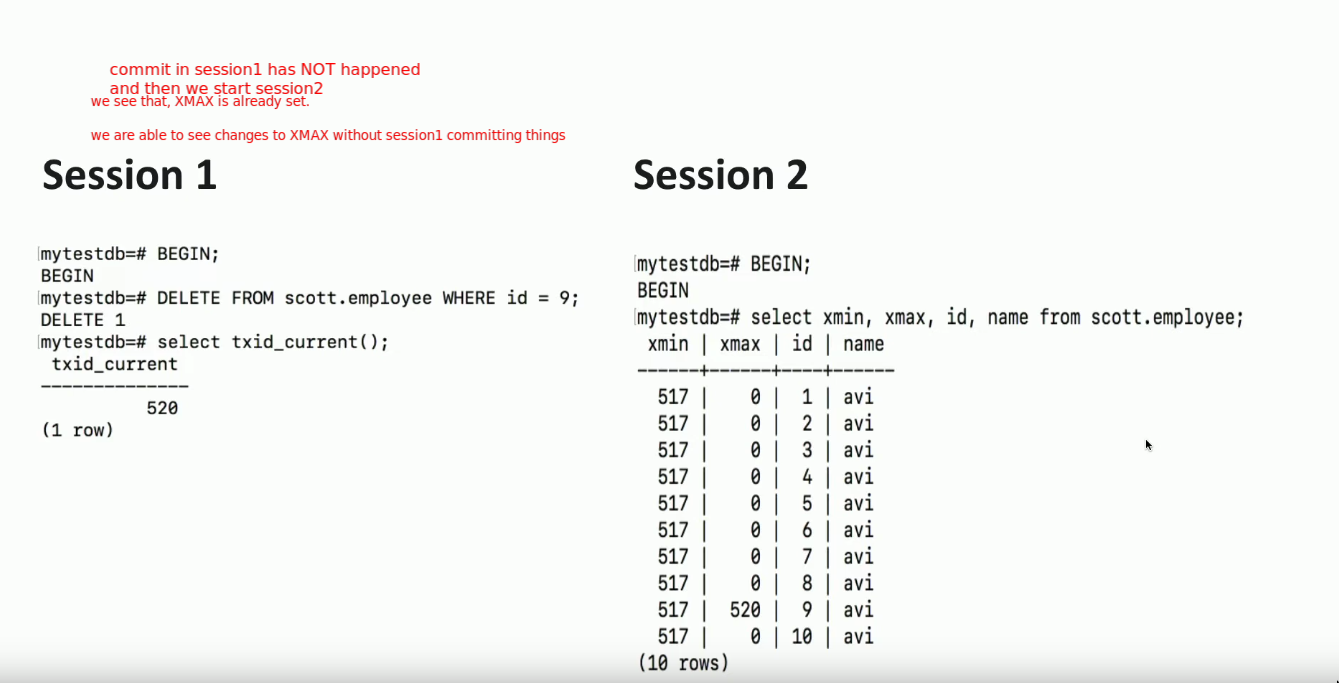

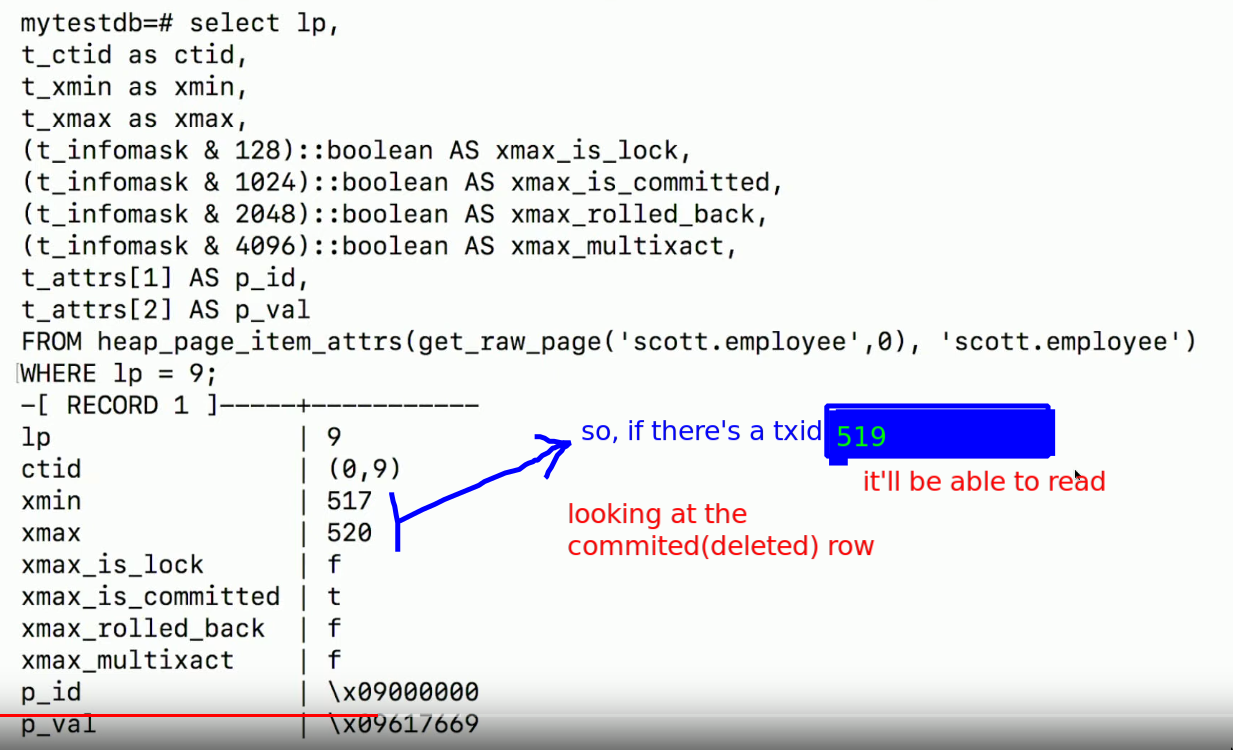
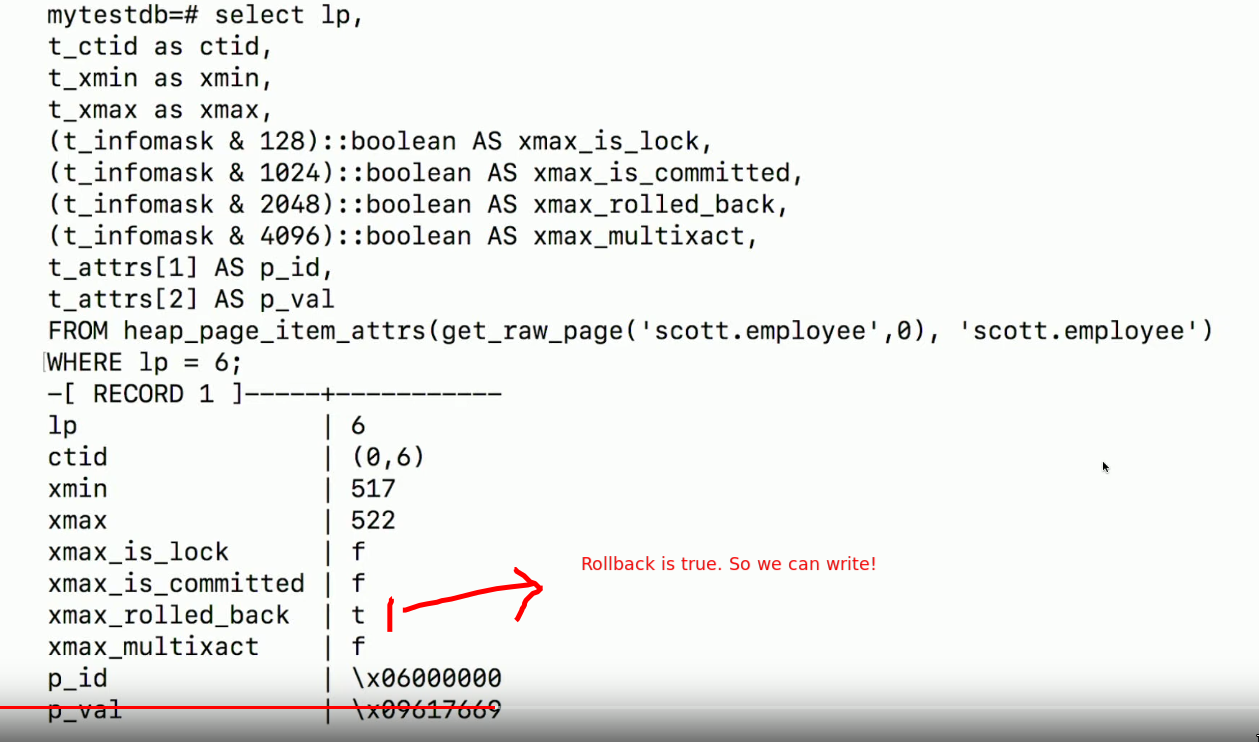
- If we’re trying to
writeand we seexmaxis non-zero: weROLLBACK- i.e in the example, if 519 tries to
writein that row, it’ll have toROLLBACK519, unless we find that the previous version was rolled back. - i.e If 2 txns update the same object/row, then first writer wins. Other rollsback.
- i.e in the example, if 519 tries to
txidthatUPDATE/DETELEtxidthatUPDATE/DETELE+ rollback0if nothing happened
- If we’re trying to
-
GID (Global Transaction Identifiers)
prepared transactionsare also assigned (GID) (See Two Phase commit (2PC))- NOTE:
prepared transactionis different fromprepared query(SQL)