tags : Database, PostgreSQL
FAQ
Quote Usage
Double quotes are for names of tables or fields. Sometimes You can omit them. The single quotes are for string constants. This is the SQL standard. In the verbose form, your query looks like this:
select * from "employee" where "employee_name"='elina';Document Data Model (NoSQL)


History?
- Berkeley, for
IngresshadQUELIngressroots PostgreSQL
- IBM, for
System Rfirst came up wSQUARESystem RrootsSystem/38,DB2SQUAREwas complicated, so needed something else.- Came up with
SEQUEL, wordplay onQUEL(sequel toQUEL) - Later renamed
SEQUELtoSQL
Why is COUNT(*) slow?
SELECT COUNT(*) FROM students;- This is same as
SELECT COUNT(1) FROM students; - So we can say “why is
SELECT COUNT(1) FROM students;slow?” COUNT(*)counts rows as long as any one of their columns is non-NULL- In PostgreSQL
- It’s because of MVCC
- Multiple transactions see different states
- PG needs to know which rows are “visible”, and “visibility” depends on the Isolation level and MVCC implementation.
- Eg. If some concurrent write access is happening on some row that will not be visible in certain isolation level. So we need to row by row.
- smol hack: We can instead get the estimate using json output of
EXPLAIN- Faster PostgreSQL Counting
- Another way
SELECT relname AS table_name, to_char(reltuples::bigint, '999,999,999,999') AS estimated_row_count FROM pg_class WHERE relname IN ('table_name1, 'table_name2') ORDER BY relname;
Why is SELECT * slow?
SELECT * from students;- It’s even worse in column store
- A Deep Dive in How Slow SELECT * is - YouTube
SQL and Relational Algebra
- SQL is based on bags (duplicates) not sets (no duplicates).
- So this is where SQL differs from relation algebra
Queries
DML
- Methods to store and retrieve information from a database.
- Procedural
- Query specifies a high-level “How” based on sets.
- This is Relational Algebra
- Non-Procedural (Declarative)
- Query specifies only what data is needed.
- This is Relational Calculus
- Eg.
SELECT, INSERT, UPDATE, DELETE, TRUNCATE
DDL
- Index creation, table creation deletion etc.
- Eg.
CREATE, DROP, ALTER
DCL (Data control language)
- Access control etc.
- Eg.
GRANT, REVOKE
Other modifiers
- Basic:
WHERE, ORDER BY, JOIN - Merge:
DISTINCT- It operates on the entire row(eg. if you SELECT multiple cols)
- Aggregate:
GROUP BY, HAVING - Limit:
LIMIT, OFFSET - Set operations:
UNION, INTERSECT, EXCEPTEXCEPTis thedifferencefrom Set Theory
Transaction control
- Eg.
BEGIN, COMMIT, ROLLBACK, SAVEPOINT, RELEASE SAVEPOINT
Operators

- relational algebra is a logical definition of what a plan should do
Ordering
- Ordering is important, do we want to join 1bnx1bn and then pick columns or do we want to join 1bnx2cols. The latter is better.
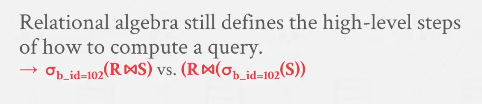
- This translates to execution strategy/query plan
- Modern optimizers can sometime help you do this automatically but sometimes it gets things wrong.
- TIP: Don’t prematurely optimize, write your query normally, see what the optimizer does, if not what you need, change your query/provide hints/provide index etc.
- Also when you write a SQL query, the order that the SQL query is written in, is not the order that it actually happens in. But irl db(s) have other optimizations aswell
Practicality
- SQL has a standard but almost every dbms vendor offends the standard
101 Basics
Query

Parameterized Query
- Query that uses placeholders for parameters instead of embedding the actual values directly in the query string. Replacement happens at
execution/run timeand not at query planning time. - Prevents SQL injection. Makes sure to treat
parametersasdataand not as executable parts of the SQL statements. - Eg.
LIKE:%(any substring),_(one character)
Prepared statement
- Uses
PREPARE, PostgreSQL pre-compiles the SQL query. Improves performance. - Creates a server side object. But only for the DB session.
EXPLAIN EXECUTE name(parameter_values);to see generic or custom plan- Features
- Can use
EXECUTEto execute the statement - You can also specify the types of the parameters
- Useful when a single session is being used to execute a large number of similar statements.
- Refer to parameters by position, using 2, etc.
- Can use
Output
String operations
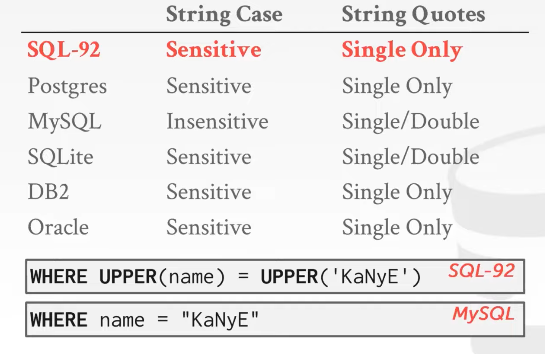
- Operations: Can be used in
outputor inpredicate- Eg.
SUBSTRING,UPPER,||/+/CONCAT, DBMSes add their own shit
- Eg.
Date/Time
- Can be used in
outputor inpredicate
Output redirection


Output control
-
ORDER BY

- The database will store the tuples any way it wants
- No guarantee that it’ll store data in the way you insert them
- Can use the
ORDER BY <column*/offset> [ASC|DSC]clause to re-order the results- Default order is
ASC - We can use
offsetnumber in cases where we run orderby in cases the column doesn’t have a name
- Default order is
- Interesting thing is, I can
ORDER BYsome column even if that column is not mentioned in theSELECTstatement. - We can also
ORDER BYon a column alias created bySELECTusingAS
- The database will store the tuples any way it wants
-
LIMIT
LIMIT <count> [offset]
Views
Regular views
- A non-materialized VIEW is a name for a
SELECTstatement- Query that pretends to be a table
- In PostgreSQL you use
VIEWto name aSELECTstatement - Building views upon other views is not uncommon.
- It directly works with actual data
- Uses
- Abstraction: Diff tables into one
- Security/Privacy: Expose only the shit you want to expose, don’t show too much cock
Materialized views
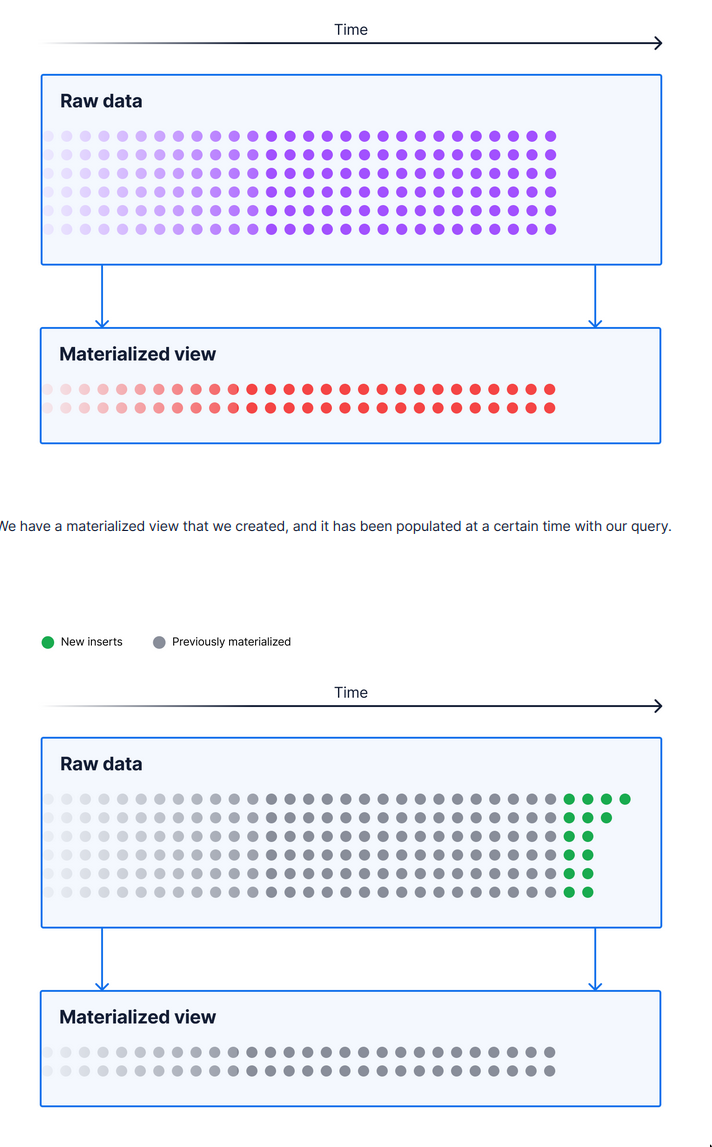
- Work best for expensive views on data that does not change frequently.
- If a view is cheap/fast or changes to the underlying data occur frequently, you probably do not want to materialize it.
- update all rows and set read locks on all affected data during refreshment by default.
- We can materializing a view into a temp table
- The temp table cannot be directly updated, but can be refreshed using
REFRESH MATERIALIZED VIEW <table_name>; - See PostgreSQL: Documentation: 16: 41.3. Materialized Views
- The temp table cannot be directly updated, but can be refreshed using
- See How PostgreSQL Views and Materialized Views Work and How They Influenced TimescaleDB Continuous Aggregates
Views v/s CTE v/s Materialized view
- CTE are sometimes called
inline view
| X | View | CTE | Materialized View |
|---|---|---|---|
| Lifetime | Q is object in DB | Exists only for duration of Q | Caches data and Q |
| USP | Can be used in multiple Q | Good w tree hierarchy i.e. recursive | |
| Index | Index can be created | No statistics, No indexes | |
| Performance | Does nothing | Does nothing | Improves Performance |
Procedures
Nested Queries / Sub Queries / Inner Queries



- Embed one query inside another
- Inner query can reference outer query table
- Difficult to optimize, the optimizer will try to optimize it into a JOIN or do something else etc.

Common Table Expression (CTE)



- Mostly about
WITHWITHare the “private methods” of SQLWITHis a prefix to SELECTWITHqueries are only visible in the SELECT they precede
- Separated by
,and returns to main query if no,(comma) - Better alternative to nested queries and views
- Statement scoped views
- Provides a way to write auxiliary statements for use in a larger query.
- Think of it like a temp table just for one query.
- Has a
RECURSIVEversion. Makes SQL Turing Complete (See Automata Theory) because it allows Recursion
WITH RECURSIVE source ( counter ) AS (( SELECT 1) UNION ( SELECT counter + 1 FROM source WHERE counter < 10)) SELECT * FROM source;
JOINs
See SQL JOINs
NULL in SQL
NULLis never equal or not equal to “anything” in SQL. Not even to itself.=and!=operators don’t work withNULL
What NULL means depends on the data
- It can mean missing data
- It can mean the data has the
NULLvalue, whatever the application then interprets - Where they come from (some examples)
- Table/Data can have it in itself
- Functions (eg.
LAG) can returnNULL - Result of some OUTER JOIN
- Any operations such as
+,*,CONCATwithNULLwill result inNULL
Handling NULL
- Handle them in application
- Filter them
- If you have
IS NULLsprinkled across every query, that tells me that you have a lot of nullable columns in your schema that really ought to be not-nullable. You should be enforcing non-nullableness on your database table, not yourSELECT. COALESCECOALESCEreturns the first item that is notNULL- items in the list should be of same type
- items can be literal or other columns too
CASE- This is how you’d write
ifstatements in SQL
- This is how you’d write
NULL and Unique indexes
NULL in not equal to NULL, so if you try to add a unique constraint or unique index on a column, it’s allowed to have multiple NULL values. unless something like NULLS NOT DISTINCT is used. (PG)
Aggregations

- Both
GROUP BYandOVERmay follow any aggregation
Aggregation Functions
COUNT(col): Return # of values for col.SUM(col): Return sum of values in col.AVG(col): Return the average col value.MIN(col): Return minimum col value.MAX(col): Return maximum col value.
GROUP BY
- Functions that return a single value from a bag of
tuples - Aggregate functions can (almost) only be used in the
SELECToutput list. - Support/Rules
COUNT, SUM, AVGsupportDISTINCT- Multiple aggregates in a
SELECTquery is allowed - Output of other columns when doing aggregates is undefined. (instead use
GROUP BY) - Non-aggregated values in
SELECTclause must appear inGROUP BYclause. - Filtering on the aggregated value is done using
HAVING, syntax looks like we’re computingAVGtwice, but the database is smart enough not to do that. We useHAVINGbecauseWHEREis not aware of the computed value.
- IMPORTANT:
HAVINGfilters after theGROUP BY,WHEREfilters beforeGROUP BY
Window Functions
Data Modeling
See DB Data Modeling
Random topics
- Rivers and Axis | ProGramin’g thoughts
- “say you have a dataset in a SQL table, and you find there are duplicates in it that shouldn’t be there. walk me through how you’d resolve this issue”
- I’ve also encountered the same thing, but with constraints added every time you come up with a solution.
- Whay if the table has a billion rows, would that affect your solution?
- What if you need to ensure it completes before every full hour?
- What if new data arrives continuously?