tags : Database, SQL, Database Indexing
A data model is a collection of concepts for describing the data in a database.
Normalization
Which one?
- This really depends on access pattern and usecase
- But generally go with normalized cuz less space and updates in one place, we can always de-normalize it if required
Normalized
- Why normalize? to reduce data redundancy and better
data integritythroughconstraints. - Less storage space, More lookups, Updates in one place
- We need to JOIN
De-normalized
- More storage, Less lookups, Updates in many places!
Keys/Constraints
Keys define constraints
Primary
- Primary key uniquely identifies a single tuple.
- Must be
UNIQUEandNOT NULL. Can be added via - Adding a primary key will automatically create a unique B-tree index on the column or group of columns
- In Distributed Systems, primary keys via
auto-incrementing idmay not be not ideal. Because now we need a global lock. uuid solves this.
Best practices
- Pick a globally unique natural primary key (e.g. a username) where possible.
- Whether to have composite primary key or have one primary key with the things concatenated is choice. If you have one single column primary key, SQL JOINs might look simpler.
Postgres Examples
CREATE TABLE products (
product_no integer UNIQUE NOT NULL,
name text,
price numeric
);
CREATE TABLE products (
product_no integer PRIMARY KEY,
name text,
price numeric
);
CREATE TABLE example (
a integer,
b integer,
c integer,
PRIMARY KEY (a, c)
);Foreign
- Often recommended as a must-have for enforcing referential integrity checks in your database.
- Optional constraint:
UNIQUE - Optional constraint:
NOT NULL - A foreign key must reference(parent) columns that either are a primary key or form a unique constraint.
- reference c(i.e column in
parent tablemust have an index)
- reference c(i.e column in
- A table can have multiple foreign keys with different tables
- See Database Indexing
Terms
FK: A column or a group of columns in a table that reference the primary key of another table.child table / referencing table: Table containing the FK- Good idea to add index the referencing column too because,
ON DELETEandON UPDATEwill need to scan this back.
- Good idea to add index the referencing column too because,
parent table / referenced table: Table being referred to by the FK- Always an indexed column(s) by design
CONSTRAINT: Command used to specify name for FK. (optional)FOREIGN KEY: Specify column(s) fromchild tableREFERENCES: Specify column(s) fromparent table
Postgres Examples
CREATE TABLE orders (
order_id integer PRIMARY KEY,
product_no integer REFERENCES products (product_no),
quantity integer
);
-- same as
-- NOTE: in absence of a column list the primary key of the parent table is used
-- as the referenced column
CREATE TABLE orders (
order_id integer PRIMARY KEY,
product_no integer REFERENCES products,
quantity integer
);
-- multiple column FK
-- child cols ~ parent col (number&type)
CREATE TABLE t1 (
a integer PRIMARY KEY,
b integer,
c integer,
FOREIGN KEY (b, c) REFERENCES other_table (c1, c2)
);
-- self referencing is allowed
CREATE TABLE tree (
node_id integer PRIMARY KEY,
parent_id integer REFERENCES tree,
name text,
...
);Deleting/Updating records with foreign keys?
- If we have FK constraints, it’ll prevent deletion if we try deleting from
parent table. We’ll need to update thereferencing/child rowbefore deleting ON DELETE,ON UPDATE: determine the behaviors when the primary key in the parent table is deleted and updated. (TODOTODO)- We have
ON DELETEandON UPDATE,ON UPDATEis not used much asREFERENCEScolumn is usually primary key and primary keys are not updated often. ON DELETE- NO ACTION (default behavior, raise error)
- RESTRICT (most common, does not defer the check)
- CASCADE (most common) : When a parent row is deleted, child row(s) should be automatically deleted as well.
- SET NULL: Set the cild row in the child column to NULL
- SET DEFAULT: Set the cild row in the child column to column’s default value
- NOTE:
ON DELETEwill not delete the child row. It’ll just deal with the FK. An application that actually wants to delete both objects would then have to be explicit about this and run two delete commands.
ON UPDATE- CASCADE: Updated value of the referenced column should be reflected in the child table.
More than one column foreign key? (Composite FK)
number&typeof columns inchild tableneed to match thenumber&typeof columns inparent tableFOREIGN KEY: Specify column(s) fromchild tableREFERENCES: Specify column(s) fromparent table
Junction tables
- Why exactly area many-to-many relationships bad database design?
- Should I store additional data in SQL join/junction table?
- Where should linking tables be stored?
- What benefit does a junction table provide
Others keys
- Surrogate key: Primary keys that are not columns
- Candidate keys
- All the keys that could have been the primary key
- Alternate keys
- Basically unique keys
- In PostgreSQL, there’s no notion of alternate keys. As an alternative, you can simply use
UNIQUEconstraint orUNIQUEindex. - Basically has the potential to be primary key but not. (
Alternate keys = Candidate Keys - Primary Key)
Other constraints
CHECK: For each column, you can put a check constraint at DB level. (Beware of operand beingNULL)price numeric CHECK (price > 0) -- same as price numeric CONSTRAINT positive_price CHECK (price > 0) -- multi column (eg. check that discounted price always less) price numeric CHECK (price > 0), -- column constraint discounted_price numeric CHECK (discounted_price > 0), -- column constraint CHECK (price > discounted_price) -- table constraint -- same as (matter of taste) CHECK (discounted_price > 0 AND price > discounted_price)NOT NULLis same asCHECK (column_name IS NOT NULL)
Relationships
See SQL X-to-Y – Damir Systems Inc.
| Possibility | Existence | Multiplicity of entity |
|---|---|---|
| is in | exactly-one | [1] |
| is in | at-most-one | [0,1] |
| is in | at-least-one | [1,*] |
| may be in | more-than-one | [0,*] |
Here, in this example we have two entities T (thing) and C (category), both can be in one of these 4 states.(4x4=16 cases). Some of these cases can be
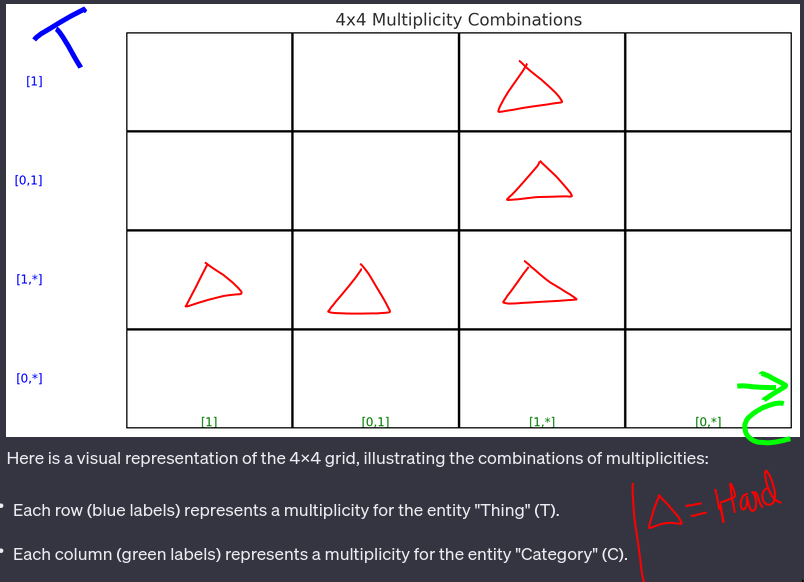
Possibilities
T[1] - C[1]
- exactly-one
thingineach category - exactly-one
categoryineach thing
T[0,1] - C[1]
- at-most-one
thingineach category - exactly-one
categoryineach thing
T[0,*] - C[1]
- more-than-one
thingmaybe ineach category - exactly-one
categoryineach thing
T[1] - C[0,1]
T[0,1] - C[0,1]
T[0,*] - C[0,1]
T[0,*] - C[1,*]
T[1] - C[0,*]
T[0,1] - C[0,*]
T[1,*] - C[0,*]
T[0,*] - C[0,*]
T[1] - C[1,*] / Hard
- exactly-one
thingineach category - at-least-one
categoryineach thing
T[1,*] - C[0,1] / Hard
- at-least-one
thingineach category - at-most-one
categoryineach thing
T[1,*] - C[1] / Hard
- at-least-one
thingineach category - exactly-one
categoryineach thing
T[1,*] - C[1,*] / Hard
T[0,1] - C[1,*] / Hard
TODO Why do some of these need triggers etc. need to dig
Schema
Interface vs Implementation
Logical schema/Interface
- Codd’s belief that queries should only be written to the interface, and never to the implementation.
- The logical schema is the set of tables and logical constraints (foreign keys, CHECK constraints, etc) on those tables.
Physical schema/Implementation
- Physical schema is the set of indexes provided for those tables.
Different schema types
General suggestions
Anchor
- Represents a core entity in the data model.
Attributes
- Descriptive name-value pairs for anchors.
- Referred to as “questions”.
- Do not contain IDs (no foreign keys inside attributes).
Links
- Represent relationships: Anchor × Anchor.
- Include cardinality:
- 1:N
- M:N
- N:1
- 1:1
Identity vs Identifying Attributes
Identity (internal DB)
- What the database uses as the internal reference.
- One per entity per data source.
Identifying (external Identifier)
- Any attribute that can be used to refer to the entity externally.
- For an external system, the identifying attribute there is treated as its identity attribute.
Other best practices
- Maybe don’t name tables with keywords like
usersetc. - When adding dates, if timestamp not needed. use time(0), will save timezone woes.