tags : Algorithms, Bit Shifting
 image found on twitter^ (gkcs_)
image found on twitter^ (gkcs_)
Abstract data types
- When we start questioning “is this a datastructure or an algorithm?”
- These are defined by what you can do with it; what operations it supports.
- Well, it uses a Data Structure and uses an Algorithm on top of the data structure.
Maps
Hashmap/Hashtable
See Hashing
Requirement
- Stability: Given the same key, your hash function must return the same answer.
- Distribution: Given two near identical keys, the result should be wildly different.
- Load factor: Once the number of entries across each bucket passes some percentage of their total size(load factor)
- The map will grow by doubling the number of buckets
- Redistributing the entries across them.
Implementation
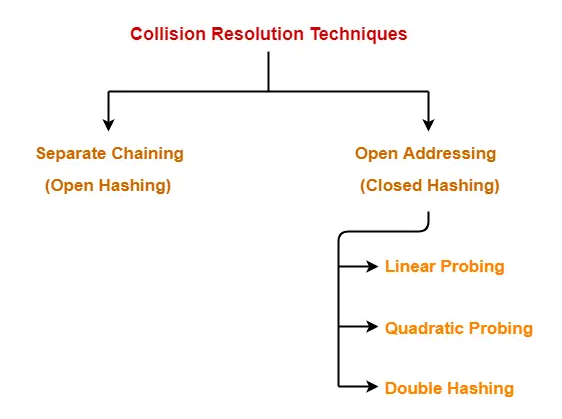
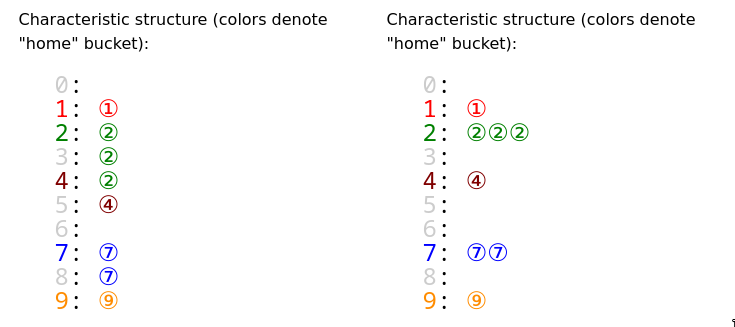
- Out of these two, online references to hash tables probably usually refer to “chain based”/“closed addressing” hash tables, where the address of the value is determined by the hash value.
- There’s nothing called “Closed Addressing” really. If it were, it’d mean
chainingbased only. i.eOpen Hashing
-
Difference
- The “hash table” is just the array+auxiliary store. Open and Closed Hashing determine whether there exists in auxiliary store.
Open Hashing / Separate Chaining: Collision elements are stored outside the main hash table array in secondary data structures (like linked lists or trees). The hash table only contains pointers/references to these external structures.Open Addressing / Closed Hashing: All elements are stored directly within the hash table array itself. When a collision occurs, the algorithm looks for another position within the same array using a probing sequence.
Name Confusion
- This gets very confusing: I’ll only remember as,
Separate Chaining&Open Addressing. These two terms make better sense to me.- Data is separately chained
- Addresses are open right there in the main data structure. (no aux)
- So I am toatlly skipping the alternative names which have
"*Hashing"in it.
Name Other names Description Open AddressingClosed HashingLocation (“address”) of the element is not determined by its hash value. instead index may vary depending on what’s already in the hash table. Closed AddressingOpen Hashing, simplyChaining,Separate ChainingEach bucket is independent, and has some sort of ADT (list, binary search trees, etc) of entries with the same index.
-
TODO Properties
Properties Open Hashing/Chaining/Separate ChainingOpen Addressing/Closed HashingAddress - actual address in a “bucket”(some ADT) attached to the hash table array - address/index of the element is not determined by its hash value - data is stored in a seperatestructure, we call itseperate chaining- index may vary depending on what’s already in the hash table - So we’re openabout where how it gets “addressed”, the hash value doesn’t become a defining factorPhysical Location - none of the objects are actually stored in the hash table’s array - we never leave the hash table; every object is stored directly at an index in the hash table’s internal array. - all data is "open"/freedfrom the internalhash table array- all data is closedin thehash table array(No buckets, only collisions)Collision - each cell in the array points to a ADT contain the "collisions"/"bucket"- We store the collisions in the same array. Then we jump from collision to collision until we find the key. Keys - Arbitrary number of keys per bucket/collision - At most one key per bucket/collision Operation Hash(Key) = Hashed_Key => mask(h_k) => bottom_bits(m_h_k) => bucket offset => key searchHash(key) => initial position, if collision, use probing sequence to find the next available slotExample Java’s HashMap (pre-Java 8), Ruby’s Hash Linear/Quad Probing, Double hashing,Cuckoo hashing, Golang’s Map etc
-
Load Factor
Feature Separate Chaining Open Addressing α Calculation α = n / mα = n / mMeaning of α Average elements per slot (avg chain len) Proportion of occupied slots Range of α 0 ≤ α (can be > 1) 0 ≤ α < 1 Performance vs α Degrades linearly, O(1 + α) Degrades sharply, O(1 / (1 - α)) Recommended Max α Often ~1.0 (flexible) Often ≤ 0.5 or ≤ 0.7 (strict) α > 1 Possible? Yes No (FULL!) Space Overhead Extra space for pointers/nodes No extra pointer space (uses table slots) Clustering Issues No (collisions handled in lists) Yes (Primary/Secondary, mitigated by probe) Deletion Simple (standard list deletion) Complex (Requires tombstones/reorganization) Cache Performance Potentially worse (pointer chasing) Potentially better (data locality) Rehashing Trigger Higher α (e.g., > 1.0) Lower α (e.g., > 0.5 or > 0.7) Key:
- n: Number of elements in the hash table
- m: Number of slots (buckets) in the hash table array
- α: Load Factor
Worst case
- WC can be caused by bad distribution/collision. Eg. All key resolutions point to the same bucket, now for the specific bucket it’ll be linear search so if everything gets dumped into the same bucket, you essentially have a linked list, i.e running time for lookup.
Resources
Merklizing the key/value store (merkle tree)
See Trees
Bloom filters
A fast index to tell if a value is probably in a table or certainly isn’t.
Maps ADTs 👀
LRU
- Usually used for caching. It’s not exactly a FIFO because we update the position of things based on when they are accessed.
- We need fast lookup: Hashmap
- Once a value is fetched from the cache, we need to move the
fetched valueto thefrontof the list. So the end of the list will have thelruvalue. - It’s like a combination of hashmap + linked list. The
valuepoints to actual nodes directly. Therefore we get for- lookup/get :
moving from position to frontand returnvalue - update
insertion-at-front(if new key)moving from position to front(if updating existing key)- Even though update technically doesn’t mean they fetched the value, but they touched it. Our logic says, if its touched it’s
used.
- expand_cache:
deletion-at-end(remove lru)
- lookup/get :
-
Implementation

- Eviction
- When over capacity, we need to evict things.
- Since eviction happens without user input. We need a way to know what
keywe have for ourvalue. For this we need areverseLookupmap, then we can also delete the originalkeyfrom thelookupmap.
- Eviction
Lists
Array
- Pedantic definition here
capacitymust defined & allocated before using, otherwise cannot form array- Cannot expand
- Good for random access
Linked list
Technically, every linked list is a tree, which means every linked list is a graph.
- Node based data structure
- Singly linked, Doubly linked
- Better control over memory than array, you could create a object pool etc.
- You can’t do a binary search on a linked list, you must traverse. (I mean you can do but it’ll not be efficient for obvious reasons). So usually bad choice if you need random access.
Linked List BAD for modern CPUs!
From a reddit post:
When linked lists were first discussed in algorithms books in the 1970’s, processor speeds were roughly comparable to the speed of accessing main memory. So there wasn’t a substantial difference in cost between accessing the next element of an array vs the cost of following a pointer to the next element in a linked list.
But on modern computers the difference is staggering: the cpu can execute hundreds or even thousands of instructions in the time it takes to access a random address in memory. (And accessing the disk is thousands of times slower than that.)
To make up for this difference, for decades processors have been using caches: the L1 cache is built into the processor and is extremely fast but relatively small, the L2 cache is larger and slightly slower to access, the L3 cache is even larger and even slower.
The caches do a lot to mitigate the cost of accessing memory, but they work best when you’re accessing contiguous blocks of memory.
And that’s why linked lists don’t do as well in practice as they seem to when you just count the number of instructions they execute.
With a linked list, every time you traverse to the next item in the list, you’re jumping to a totally random location in memory, and there’s a decent chance that address isn’t in cache.
With an array, getting the next element in the array is in adjacent memory, so after the first access the rest of the array is probably cached.
So, what most people find is that in practice, a dynamic array is much faster in practice for many common list sizes.
Also, keep in mind that linked lists are not necessarily that efficient in terms of memory: if each item is 8 bytes or smaller, then every item in the list needs an additional 8 bytes of overhead (for the pointer). So a linked list might have 2x overhead, while a dynamically growing array might perform quite well with only 25% overhead.
Of course, it totally depends on the exact usage. There are absolutely cases where linked lists perform better than alternatives, and they should still be used in those cases.
- c++ - Bjarne Stroustrup says we must avoid linked lists - Stack Overflow
- In defense of linked lists | Hacker News
Dynamic Array/Array List
- Rapper names: grow-able array, array list
- Implementations: Go Slices, Java ArrayList, Python’s list, Javascript []
- You get: Random access. Well suited for stack likes (LIFO)
insert/removeat the end/tail is , good stuffinsert/removeat the start/head is , pretty bad- Optimal
stackimplementation is possible, Optimalqueueimplementation is not possible.- i.e Implementing a
queuein Javascript with.pushand.shiftis probably not the best idea. But there have been improvements in.shiftrecently.
- i.e Implementing a
- Whenever there is no room for appending a new element
- It creates a larger array
- Copies the contents of the current array to it
- Deletes the current array
- Sets the newly created array as current
- Finally, appends the element normally.
Array Buffer / Ring Buffer / Circular buffer
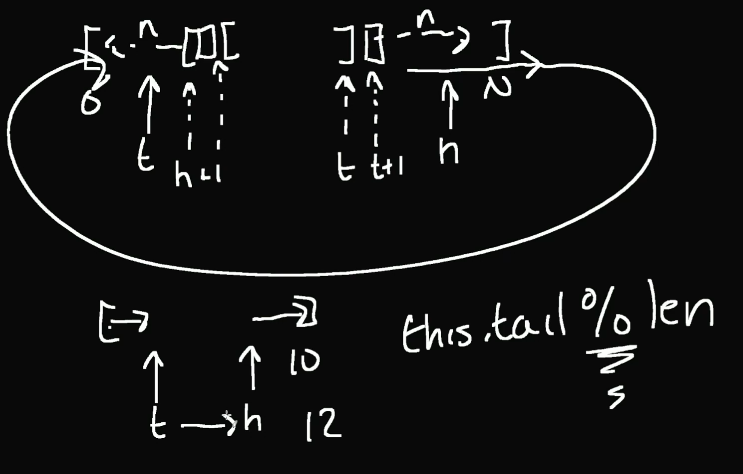
- No fixed head or tail. This also grows like Dynamic arrays but at the same time maintains order.
- No shifting of other elements in the buffer needed at insertion/removal unlike dynamic array/arraylist. So, Well suited for queue like interfaces (FIFO)
- You can implement things like queue/double ended queue(deque)/circular queue etc. w it.
- Circular Buffer Performance Trick - Cybernetist
List ADTs 👀
Queue
- Can be implemented on top of a Linked List data structure.
- It constrains what you can do with a linked list.
- We don’t even need a doubly linked list to implement a basic queue.
- FIFO
- The algorithm a queue implements is FIFO.
- FIFO is bad for temporal locality
- Interface
insert-at-end: (akaenqueue)remove-at-front: (akadequeue)
Stack
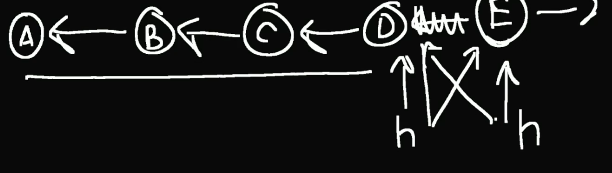
- LIFO
- LIFO is good for temporal locality
- Good to think of arrows pointing backwards from the head. So usually just
prevon a Node works. - Interface
insert-at-end: (akapush)remove-at-end: (akapop)
Deque (double ended queue)
- Not to be confused w the
dequeueoperation. (Spelling is different!ue) - This is an abstract data type, Java has an implementation of this interface. It can be implemented via Linked list/or some custom implementation like Java does with
ArrayDeque. insert-at-end: (akaenqueue/push)remove-at-end: (akapop)remove-at-front: (akadequeue)insert-at-front:
In Java,
ArrayDequedoesn’t have
- The overhead of node allocations that LinkedList does
- The overhead of shifting the array contents left on remove that ArrayList has.
- So eg. in Java, if you had to implement a
Queue, you’d go withArrayDequeas the underlying data structure rather thanLinkedListorArrayList.- Summary: It’s pretty good.
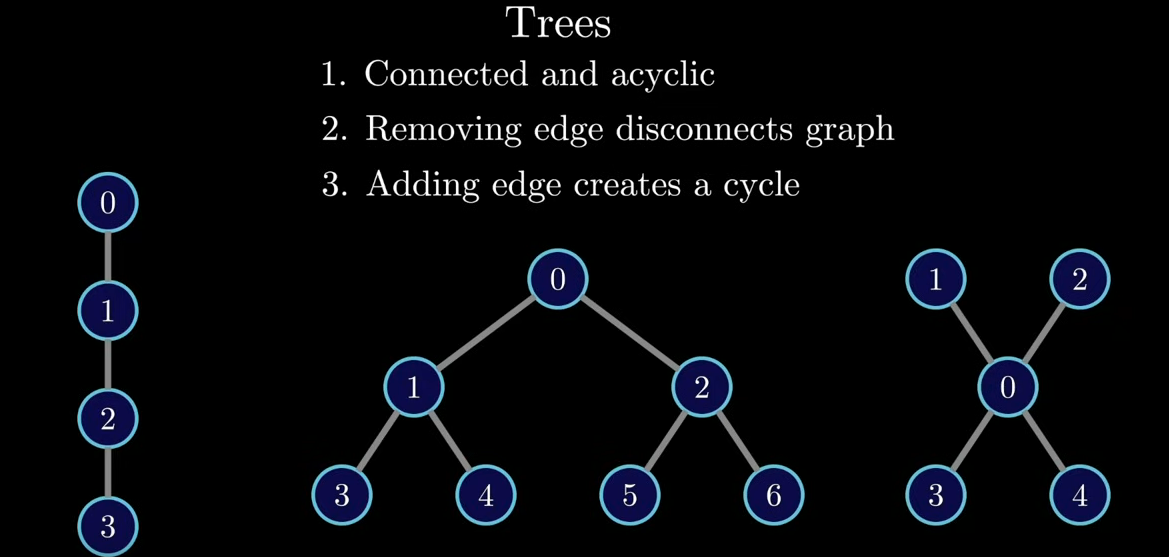
Trees
- Technically, trees are just linked-lists with multiple paths.
- Trees are also graphs
- i.e
link list = tree = graph
 See Trees
See Trees
Tree ADTs 👀
- Priority Queue (Implemented using Heap)
Graphs
- See Graphs