tags : Identity Management
OAuth (Open Authorization)
- OAuth 2.1 Spec : https://datatracker.ietf.org/doc/html/draft-ietf-oauth-v2-1-07
- Framework that provides clients a “secure delegated access” to server resources on behalf of a resource owner.
- It’s an Authorization only thing. i.e most times assumes parties communicating are trusted already.
- It does NOT deal with user registration, password recovery, changing a password or email address and so on.
- OIDC (OpenID Connect)’s parent: OIDC is an authentication layer built on top of OAuth 2.0.
Some usecases
- Allow third parties access to your data e.g. Facebook data (
OAuth2). - Allow third parties to authenticate you via your social acc e.g. Facebook account (
OpenID Connect). - Allow third parties to access your users data safely etc. (
OAuth2)
History
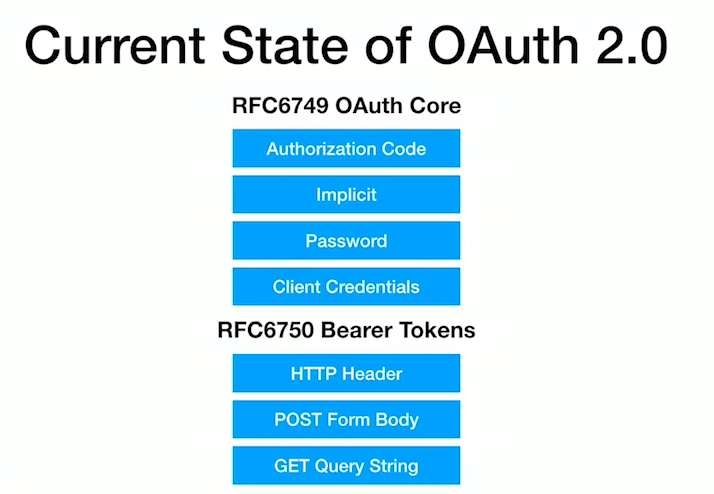
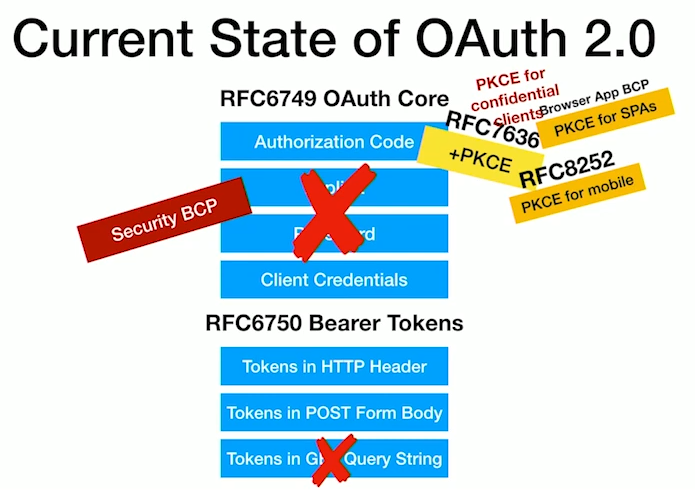

- OAuth 1.0 was published as RFC 5849 in 2010
- OAuth 2.0 was published as RFC 6749 in 2012
- OAuth 2.1 Authorization Framework is in draft stage, Consolidates OAuth 2.0 and adds best practices.
Flows
Implicit Flow (deprecated)
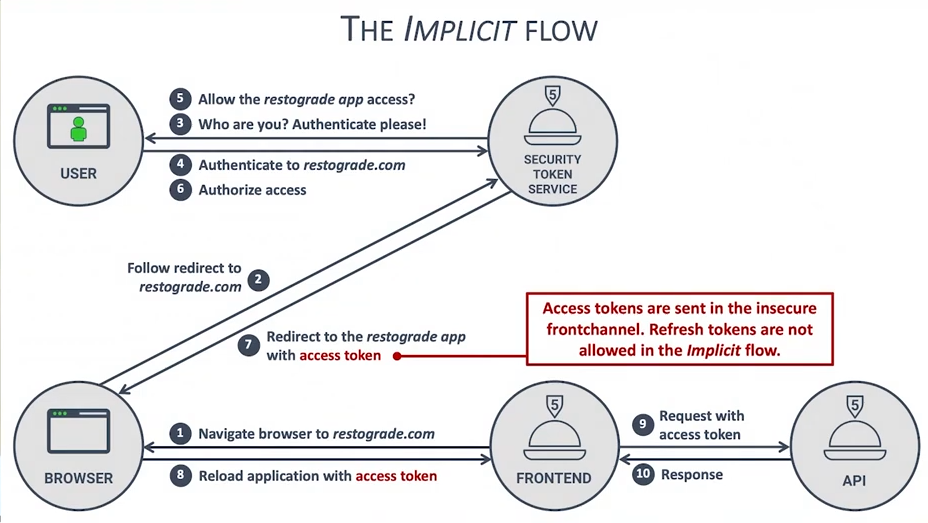
- Issues
- Access token is sent over in the url
- No Authorization Code
- Cannot have refresh token
PKCE
- Problem:
Authorization serverneeds to know that the correct application is requesting for anaccess token. Normally,client_secretsolves this. BUT! we cannot useclient_secretforSPAsandmobile apps. We can use the Implicit flow but PKCE is just better. - Solution: PKCE
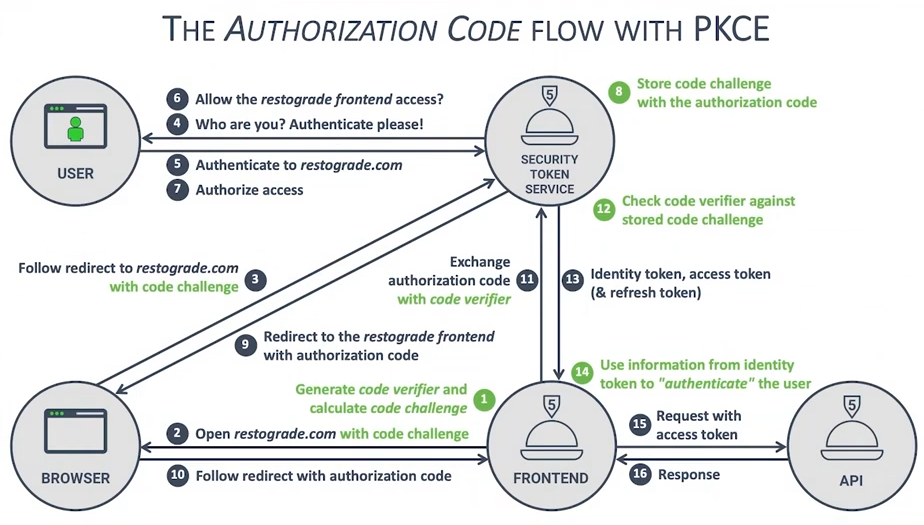
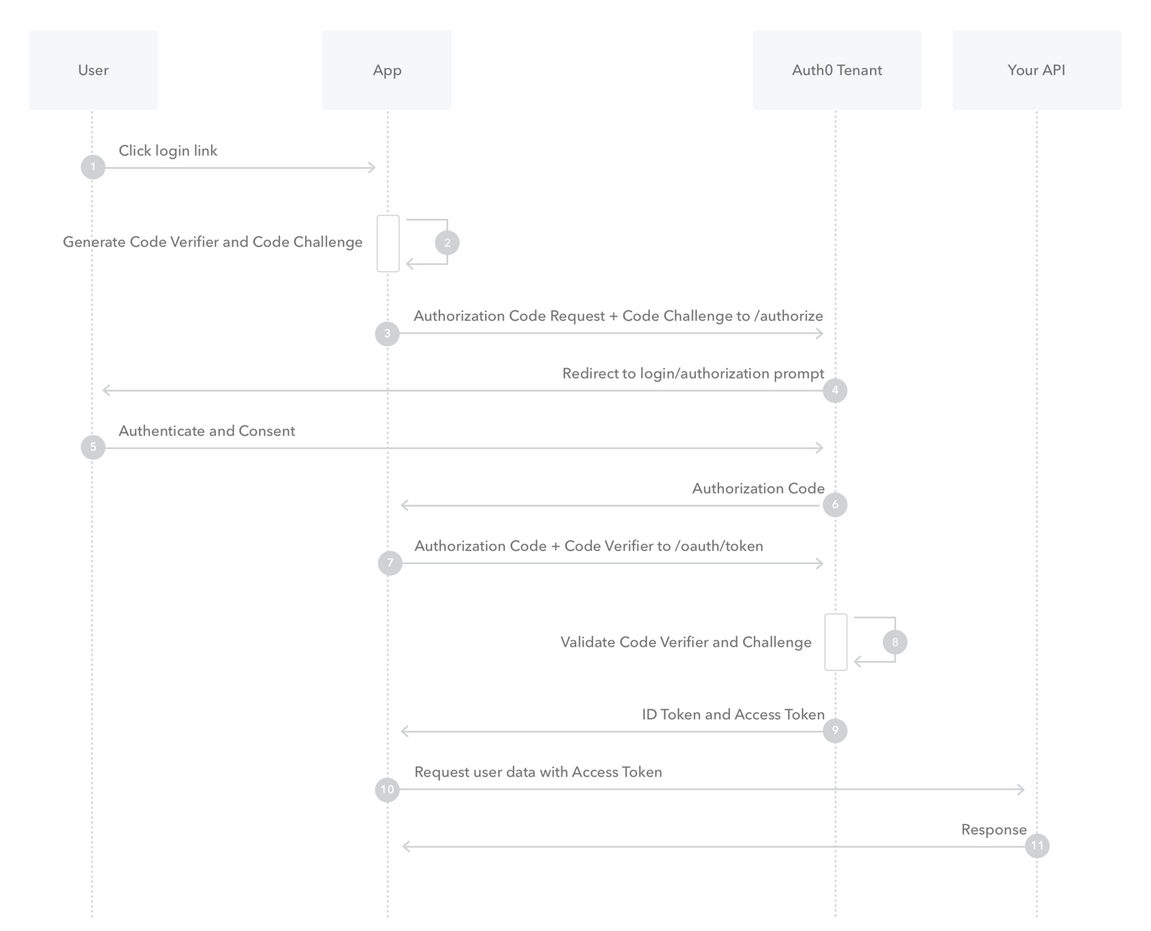
- The application generates code challenge and code verifier
- Uses code challenge to get one time auth code
- Uses auth code and code verifier to get access token and refresh token
Front channel & Back channel
Front channel
The indirect communication between the client and the authorization endpoint via the user agent and based on HTTP redirects
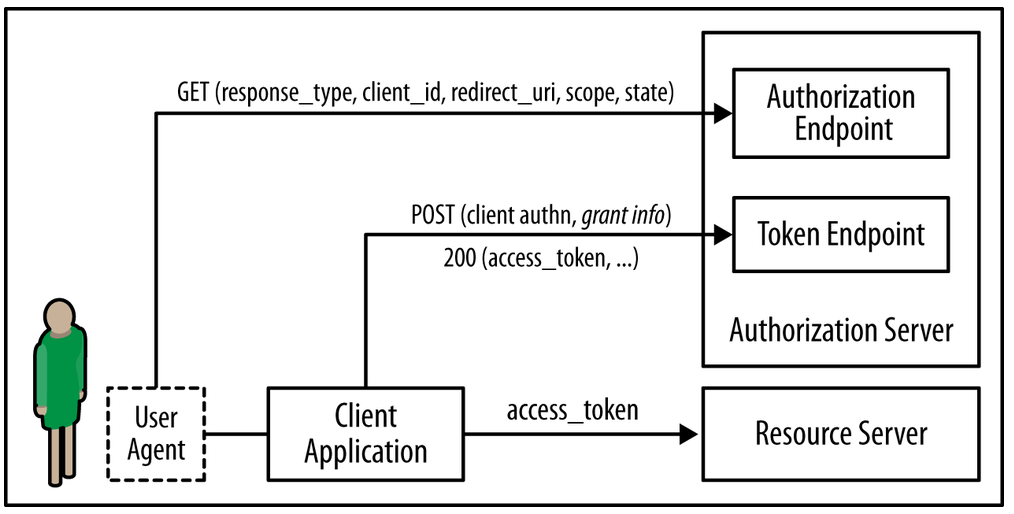
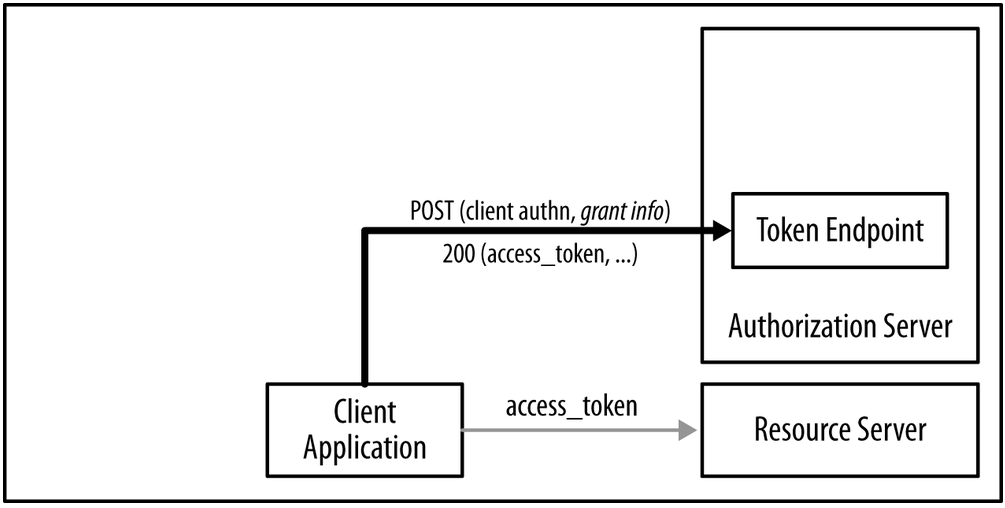
Back channel
The direct communication between the client and the token endpoint.
Authorization Types (for backend)
by Access Control
| Feature | RBAC (Role-Based) | ABAC (Attribute-Based) | ReBAC (Relationship-Based) |
|---|---|---|---|
| Basis for Decision | User’s assigned Role(s) | Attributes (User, Resource, Action, Env.) | Relationships between entities |
| Granularity | Low | Very High | Medium-High (limited by relationships) |
| Best Use Case | Simple, role-defined access needs | Complex, dynamic, context-aware rules | Hierarchies, groups, ownership structures |
| Strengths | Simple, Easy Management, Performance | Highly Granular, Flexible, Dynamic | Handles Hierarchies well, Reverse Queries |
| Weaknesses | Inflexible, Role Explosion risk | Complex (Implement/Manage), Resource-Intensive | Complex (Implement/Manage), Query Performance, Audit Difficulty |
| Hierarchy Handling | Poor | Cumbersome/Verbose | Excellent |
| Reverse Queries | No | Difficult | Yes (Naturally supported) |
| Implementation Complexity | Low | Medium-High | High |
RBAC (Role-Based Access Control)
The simplest model. Access is granted based purely on the role(s) assigned to a user (e.g., Admin, Editor, Viewer). It’s easy to manage for straightforward scenarios but struggles with granularity and can lead to “role explosion” in complex applications.
ABAC (Attribute-Based Access Control)
Offers highly granular control. Access decisions use attributes of the user (e.g., location, department), the resource (e.g., sensitivity, type), the action, and the environment (e.g., time of day). It’s very flexible and dynamic but significantly more complex to implement and manage, and can be resource-intensive.
ReBAC (Relationship-Based Access Control)
Grants access based on the relationship between entities (e.g., user owns document, user is member of team that can access folder). It excels at handling hierarchies and nested structures (like folders and files) and naturally supports reverse queries (who can access X?). It is powerful for these cases but can be complex to implement, potentially resource-intensive for queries, and harder to audit.
ACL-Filtering
Authorization is really about “defense in depth”. In a ZTA model, your access proxy, authentication system, API gateway, application middleware, and data layer all provide additional levels of protection. So essentially you should use both the proper AuthZ system + DB level security such as Row Level Security (RLS).
-
Basic Problem
- So in this case, we need the Authorization service to be able to modify the database query such that it only fetches the records that they’re allowed to access while maintaining security & performance.
- WORKS: When you have a authZ service validating our requests, and you have a single resource, and you ask a second API(authZ service) on whether the request is allowed or not.
- ERR: When you query a database for a list of items, to add access control I need to modify the database query. I can’t just filter after the fact, it’s too easy to cause performance issue(loading too many records only to filter a few!)
-
In other words
- Gating the operation :(whether it’s retrieving a single resource, or creating / updating / deleting a resource). In this scenario, the application does need to call the authorizer before performing the operation on the resource, but the relationship between the authorizer and the application is at “arms length”.
- Filtering a list of resources: In this scenario, the authorization system can help you by running what in OPA is known as a “partial evaluation”, which returns an abstract syntax tree. Your code would then walk that tree and insert the proper where clauses (if you’re talking to a SQL back-end). As you mentioned, by necessity, your application needs to work more closely with the authorizer.
-
Solution
can be done in two ways: “pre-filter” and “post-filter”. Sometimes you might even have to do both.
-
Pre-Filter
- Convert a policy into a generic AST that you can use in your data filtering logic on your data storage.
- Eg. This is done by Cerbos, The Query Plan API is used in a relatively advanced use case. The API returns an abstract syntax tree (AST) of the relevant policy. Cerbos partially evaluates the policy because the principal is known, but the resource(s) are not, then returns the AST in the result.
- It’s straightforward to translate this particular AST to SQL. Unless you’re using an ORM for which we have an adapter, you must write a translation layer yourself. It is common (for Cerbos users) to write a custom adapter for a particular application and database.
- Filtering data using authorization logic | Cerbos
-
Post-Filter
- Filtering once you’ve queried all possible results from your database can also be more performant than you’d think, because you can amortize performance by lazy loading and performing permission checks in parallel. We have some pretty large systems that are purely using this strategy.
- The code for filtering can also be made extremely elegant because it can be hidden behind the iterator interface in whatever programming language you’re using.
-
Not have a secondary API!
We can go with tools such as
casbinwhich don’t operate as a secondary API for AuthZ but directly embedded in your application.casbincan push to your DB (including multi-tenant-sharing if you scale) and a legit modern policy engine - A(R)BAC, ACL, etc. Definitely warts, but pretty close to what I’d hope architecturally, meaning a clear path to prettier UIs, plugging into automatic SMT solvers/verifiers, etc, and till then, pretty easy from whatever backend lang + SQL DB you use.
-
RLS
- Long-term, stuff like row-level security in your SQL / metadata store makes a lot of sense (people pointing that out in the thread below), but RLS is still awkward in practice for even basic enterprise RBAC/ACL policies.
- See Row Level Security (RLS)
-
by Implementation
Meta Questions(FAQ)
-
When do we need to go beyond simple db check pattern(“just have the role in a db table pattern”)?
- Growing Roles/Permissions: Managing more than a few basic roles (e.g., beyond just “admin” and “user”) becomes complex. (Eg. “editor,” “viewer,” “manager,” “auditor,” etc)
- Fine-Grained Control Needed: Access needs to be specific to actions on particular resources (e.g., edit
thisdocument, viewthatfolder). This points towards ABAC or ReBAC. - Context-Dependent Access: Decisions must factor in attributes like user location, time of day, resource sensitivity, etc. (suited for ABAC).
- Relationship-Based Access: Permissions depend on how users and resources relate (e.g., owner, manager, group member). ReBAC excels here.
- Auditability & Management: It becomes hard to track “who can access X?” or “what can user Y do?“. More structured systems (RBAC, ReBAC) offer better visibility.
- Dynamic/Complex Rules: Authorization logic changes often or involves intricate conditions, benefiting from Policy-as-Code or dedicated engines (ABAC/ReBAC).
- Code Complexity: Authorization logic starts cluttering the main application code instead of being centralized.
- Performance Bottlenecks: Evaluating complex permissions via database queries becomes too slow.
- Scalability Limits: The simple approach struggles to handle a large number of users, resources, and rules efficiently.
-
Difference between Graph vs Policy as Code Authz
Feature / Aspect Graph-Based Authorization (e.g., Zanzibar, SpiceDB) Policy-as-Code Authorization (e.g., OPA, Cedar) Primary Access Control Natural fit for Relationship-Based Access Control (ReBAC). Excels at managing complex policies (e.g., ABAC, RBAC). Relationship Handling Excellent for representing hierarchies and nested relationships. Flexible, can manage complex relationships but not inherently hierarchical. Data Volume Management Manages high volumes of data consistently. Can struggle with large data volumes without proper sharding. Reverse Indices Supports reverse queries (e.g., “who has access to X?”). Typically does not support reverse indices. Performance Generally lower performance compared to policy-as-code. Generally higher performance. Deployment Location Often centralized; practically infeasible to run at the edge due to size. Feasible and efficient for local or edge deployment. Latency Higher latency, often due to non-local/centralized nature. Lower latency, especially when deployed locally. Policy Complexity More limited, primarily focused on ReBAC. ABAC support can be limited (e.g., SpiceDB Caveats offer a restricted form). Highly flexible, adept at handling complex rules and logic. Ease of Policy Updates Can be less flexible for updates compared to code. Policies are code, allowing flexible and easy updates. Ecosystem Emerging ecosystem. Mature and robust ecosystem with various plugins and engines. Learning Curve Moderate complexity, focused on data modeling. Can have a higher learning curve due to specific policy languages (e.g., Rego for OPA). Consistency Strong consistency guarantees, even distributed (like Zanzibar). Consistency depends on deployment and data sourcing strategy. Primary Deciding Factor Better for simpler policies at very large scale (>1M users). Better for complex policies, often suitable for systems under 1M users unless scaled carefully.
Simple database check
- We can maintain a table linked to each user, where the access/role of the user is defined
- That way we can use the session token to do access control as needed
Graph based / Zanzibar based
- SpiceDB https://github.com/authzed/spicedb
- Ory Keto
- Used OPA initially, then shifted to Zanzibar model
- permify/permify
- OpenFGA
Policy-as-Code based
3 main players as I see it: cerbos, casbin and OPA
- cerbos, casbin and OPA can be used together as per need. But for simple cases cerbos should be enough.
- These usually don’t support
ReBACbut can partially support it- From OPA to our own engine - the Cerbos journey | Cerbos
- ShipTalk podcast: Why authorization should no longer be an afterthought | Cerbos
| Feature | Cerbos | OPA (Open Policy Agent) | Casbin |
|---|---|---|---|
| Primary Form | Specialized Authorization Service | General-Purpose Policy Engine | Flexible Access Control Library (primarily) |
| Key Advantage | Optimized DX & Perf for App AuthZ; Decoupled | Ultimate Flexibility; Unified Policy across stack | Multi-language; Embeddable; Model variety |
| Deployment | Standalone API Service | Service / Sidecar / Go Library | Embedded Library / Optional Server |
| Main Focus | Simplified, Decoupled Application Authorization | General-Purpose Policy (AuthZ, Infra, K8s+) | Implementing Various Access Control Models |
| Policy Language | YAML/JSON (Human-readable, structured) | Rego (Powerful, declarative, steeper curve) | PERM Metamodel (Model-driven text config) |
| Policy Scope | Application RBAC/ABAC focus | Very Broad (Any JSON/YAML data) | Std. Models (ACL, RBAC, ABAC, custom) |
| Engine Origin | Own custom engine (Initially used OPA) | Own Rego engine | Own core library engine |
| State Mgmt | Stateless Engine (Evaluates per API request) | Stateless Engine/can be stateful aswell | Stateful (Policy/roles via Adapters) |
| Data Handling | Needs Context/Principal data provided via API | Needs Data via `Input` JSON; Can use Bundles | Adapters for Policy/Role Storage & Retrieval |
| IAM Integration | Consumes provided attributes (e.g., from JWT) | Consumes provided attributes (e.g., from JWT) | Role Mgr can optionally fetch/sync from IAM |
| Decoupling | High (External Service by design) | High (if run as Service/Sidecar) | Lower (if Embedded as Library) |
| Performance | Highly Optimized specifically for App AuthZ | Generally Performant | High Performance (esp. as embedded Library) |
| Dev Experience | Focus on Simplicity (API, YAML/JSON) | Focus on Power/Flexibility (requires learning Rego) | Focus on Model Definition & Embedding |
| Admin UI | No | No | via Casdoor |
| Use Case Fit | Microservices, Centralized App AuthZ, Simplicity | Platform Policy, K8s, Complex/Diverse Rules | Multi-lang Apps, Need Embeddable AuthZ |