tags : Local First Software (LoFi), Distributed Systems, Data Replication
Data Replication can also be considered as part of Synchronization, but in this page we’re trying to keep things more specific to sync engines related to Local First Software (LoFi).
What?
- Robust database-grade syncing technology to ensure that data is consistent and up-to-date.
- To fully replace client-server APIs, sync engines need:
- Robust support for fine-grained
access control - Complex
write validation
- Robust support for fine-grained
Problems and how sync engines helps 🌟
No Offline Reading
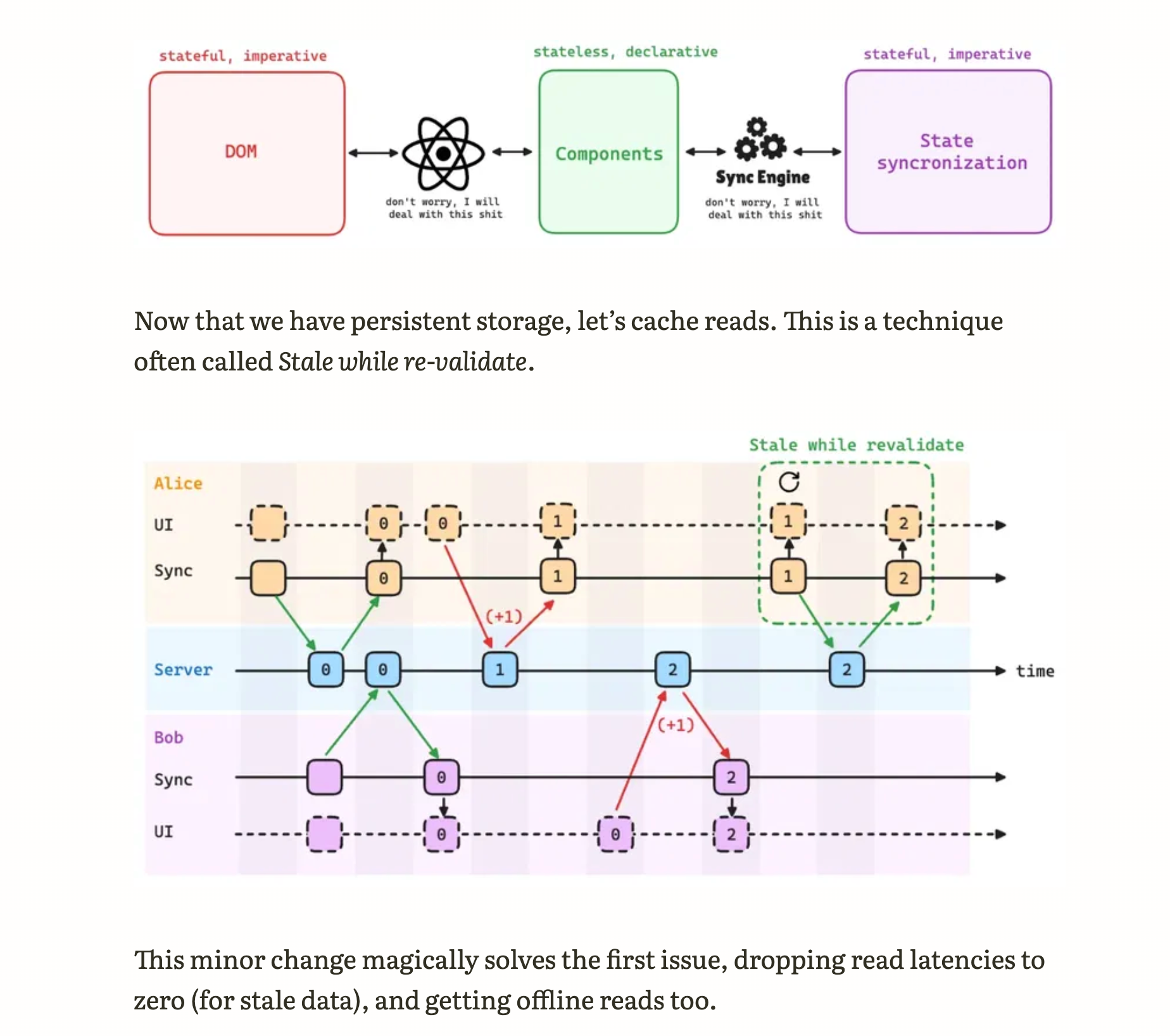
Problem: Reads always occur over the network, meaning offline reading isn’t possible, and you’ll face the latencies. Solution:
Stale-While-Revalidate Caching
- Caches read operations for fast access
- Serves stale (cached) data immediately while fetching fresh data in background
- Solves by:
- Reducing read latencies to near-zero for cached data
- Enabling offline reads from cache
Laggy writes/interactions
Problem: Writes, making all interactions feel laggy and without offline support. Solution:
Optimistic Updates
- Allows immediate local state mutations before server validation
- Changes appear instantly in the UI while syncing in background
- Solves by:
- Making writes feel instantaneous
- Enabling offline write operations
Optimistic Update needs a server synchronization strategy. Primarily 2 types:
Serializable- Server only accepts operations matching its current state
- Rejects operations based on stale data
- Simpler model, common in many databases
Commutative- Operations designed so order doesn’t matter
- Uses operations like “increment counter” instead of “set counter to X”
- Examples: crdt and OT (Operational Transformation) fall under
commutative
Stale data, No real-time
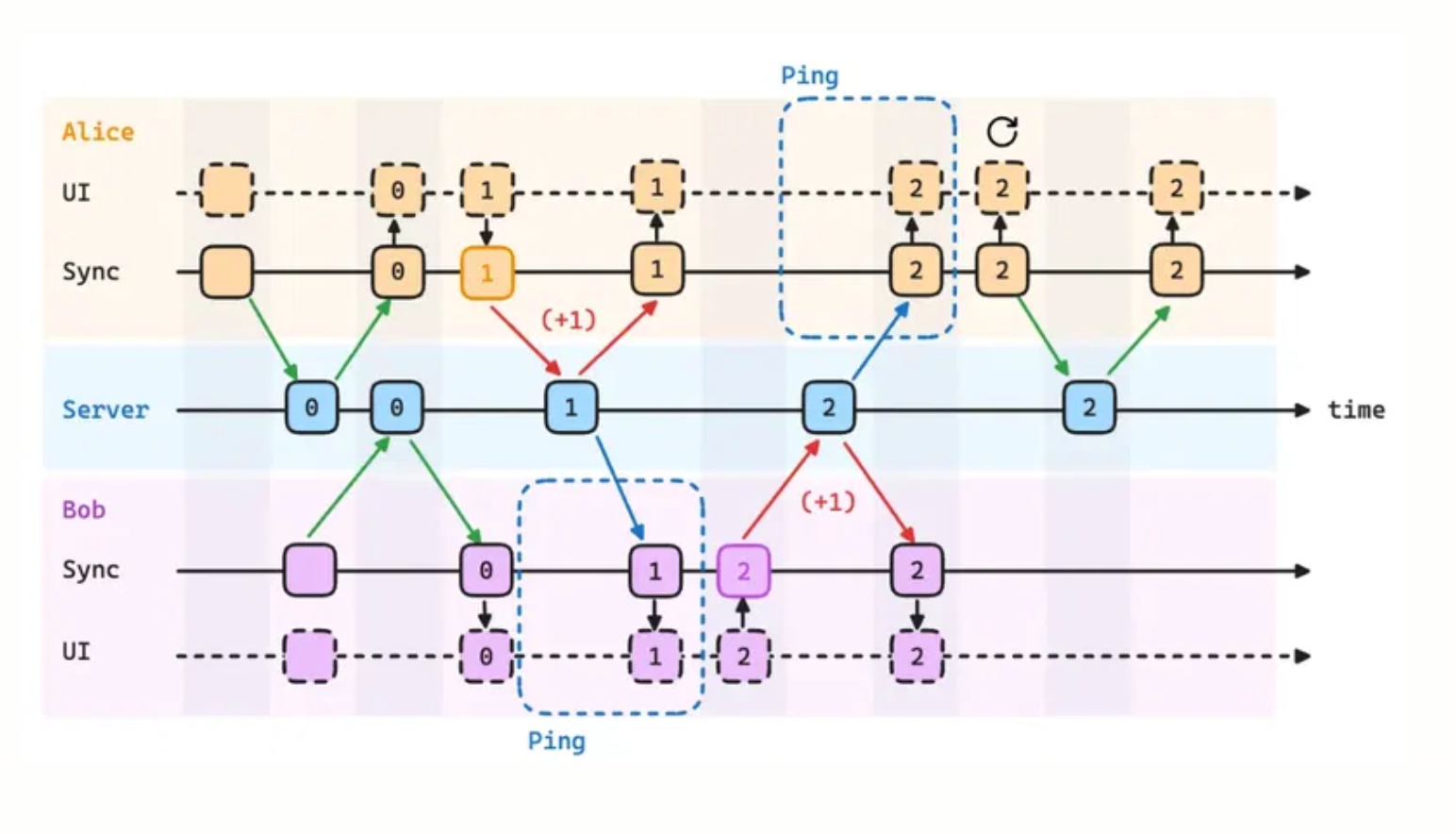
Problem: The stateless model can’t offer real-time collaboration, since the server doesn’t proactively push updates to the client. Solution:
server-to-clientcommunication.
- Server “pings” changes to clients (eg. SSE, WebSockets, HTTP streaming etc)
- Otherwise the simplest way to replicate data is for client to poll for updates every second or so.
- Enables multiple users to work together simultaneously
- Ensures all clients eventually converge to the same state
Usecases of sync engines
source: https://simonwillison.net/2025/Apr/8/stop-syncing-everything/
Offline-first apps: Note-taking, task management, or CRUD apps that operate partially offline. Graft takes care of syncing, allowing the application to forget the network even exists. When combined with a conflict handler, Graft can also enable multiplayer on top of arbitrary data. See Local First Software (LoFi)Cross-platform data: Eliminate vendor lock-in and allow your users to seamlessly access their data across mobile platforms, devices, and the web. Graft is architected to be embedded anywhere.Stateless read replicas: Due to Graft’s unique approach to replication, a database replica can be spun up with no local state, retrieve the latest snapshot metadata, and immediately start running queries. No need to download all the data and replay the log.Replicate anything: Graft is just focused on consistent page replication. It doesn’t care about what’s inside those pages. So go crazy! Use Graft to sync AI models, Parquet or Lance files, Geospatial tilesets, or just photos of your cats. The sky’s the limit with Graft.
Overlapping ideas/topics
Some of these ideas complement each other, can exist alone etc etc.
- Centralized Infrastructure
- Realtime, WebRTC, WebSockets
- Collaborative applications
- crdt
- peer-to-peer
TODO Other notes
- Clients tend to have unrestricted write access and updates are immediately synced to other clients. While this is generally fine for text collaboration or multiplayer drawing, this wouldn’t work for a typical ecommerce or SaaS application.
- Sync engines can drive consistency within a system but real-world systems also need an authoritative server which can enforce consistency within external constraints and systems.
Current tech
Also see the “Approaches section” in Local First Software (LoFi)
TODO Building sync engine
When you’re building a sync engine, you’re essentially building a database with replication
Comments
Guy who’s been working full-time on sync since 2011 here. This is valid as far as it goes, but it’s all written with the assumption that you have exactly two (2) data stores to keep in sync, and that only one is mutable while the other is a passive replica. That is Easy Mode. It’s training wheels, it’s the tutorial level, ya?
What makes sync difficult is when you have more than two databases, and more than one is being mutated. It’s not just the possibility of conflicts, it’s that the metadata and algorithms to identify changed data become more complex than just “set a flag when you change a record.”
CouchDB (and Couchbase Mobile, my $DAYJOB) use a combination of sequence numbers and revision trees.
The sequence number is a record field that’s local to each replica. It’s a counter that acts as a logical timestamp. By remembering the highest sequence number you’ve seen, you can then cheaply query for all records modified since that time. Revision trees are global. Every document/record stores multiple revisions in a causal history. Each revision has an ID based on a digest of the data, making it fairly cheap to tell if both sides of the connection have the same revision. Normally these form a linear history, but conflicts introduce branches, which are later merged by application logic.
Another good approach is to use Prolly Trees, of which several good articles have been posted here in the past year.
Resources
Case studies
How does PartyKit do it?
“With a model like PartyKit, building a system that can synchronise state is straightforward: Hold that state in memory, let websockets (or http requests!) connect to the same process. When clients “send” changes to said state, broadcast those changes to all connected clients. Depending on the usecase, you can use fancier data structures to model the state (like CRDTs or OTs), setup state machines to model workflows, or use a pubsub model to broadcast events.”
- This draws the boundaries nicely about the network aspect, and the managing the state Aspect.