tags : Computer Memory, Virtual Memory
dL1,iL1(data,instruction) cache of 32KB each(
$ lscpu), supportswrite-back($ lshw)
λ getconf -a | grep CACHE
LEVEL1_ICACHE_SIZE 32768
LEVEL1_ICACHE_ASSOC 8
LEVEL1_ICACHE_LINESIZE 64
LEVEL1_DCACHE_SIZE 32768
LEVEL1_DCACHE_ASSOC 8
LEVEL1_DCACHE_LINESIZE 64
LEVEL2_CACHE_SIZE 262144
LEVEL2_CACHE_ASSOC 4
LEVEL2_CACHE_LINESIZE 64
LEVEL3_CACHE_SIZE 6291456
LEVEL3_CACHE_ASSOC 12
LEVEL3_CACHE_LINESIZE 64Basics
- caches don’t operate on arbitrary-sized variables, only 64-byte cache lines.
Types of miss
- Cold (compulsory) miss: at the start when cache is empty.
- Capacity miss: when
working setis larger than the cache. - Conflict miss: this is common in direct mapping, happens less in e-way associatve caches. Block i at level k+1 must be placed in block (i mod 4) at level k
Organization
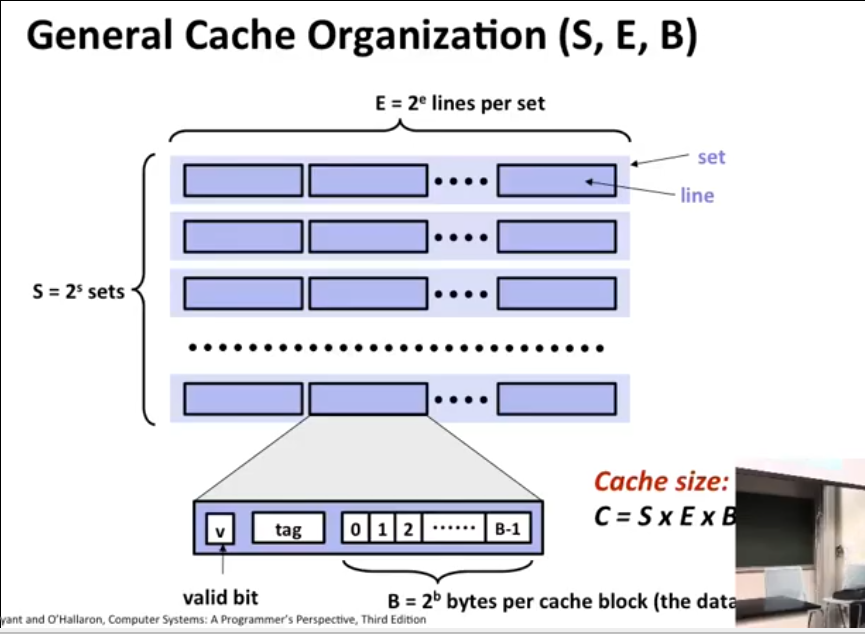
(S,E,B)- S = 2^s
sets - E = 2^e
linesper set. OREblocks perset- Each
lineconsist of ablockand few more things.
- Each
- B = 2^b
bytesper cacheblock. (this is what we mean when we say cache block size) - Cache
blocksare interesting, the purpose of blocks is to exploit spatial locality. If you make theblockstoo small, you might not fetch enough neighbor bits so that spatial locality is at use.
Designing a cache
- The block size comes first
- Then you determine how big you want your cache to be
- Then you decide on the associativity
- Once you determine the associativity, that determines the number of sets.
Associativity == S (no of sets, 2^s)
Cache placement policies
These can be categorized based on associativity. When replacing a block/line in a cache, cache replacement policies such as LRU are used., the lines have additional blocks to store timestamps etc.
- Even though fully associative cache give the best miss rate, It’s not worth having this much of complex search logic in the hardware of cache to support low associativity to support full associativity.
- We do see full associativity in virtual memory, because the penalty in
DRAM to Diskis way more than penalty fromcache to DRAM.
Fully associative cache takes a lot of power and area, and direct-mapped caches take the least.
Eg. Skylake CPU
- L1 cache: 8 slots (or “ways”). “8-way set associative cache” because it has 8 ways.
- L2 cache: on a Skylake is 16-way set associative
- L3 cache: is 11-way set associative.
Eviction:
- The set size of a cache influences how long a cache line is likely to stay in the cache
- The more associativity the cache has (the more ways there are), the longer it will take for a cache line to be evicted.
- i.e direct > E-way > Full (i.e direct gets evicted as soon as some access is mapped to the same set)
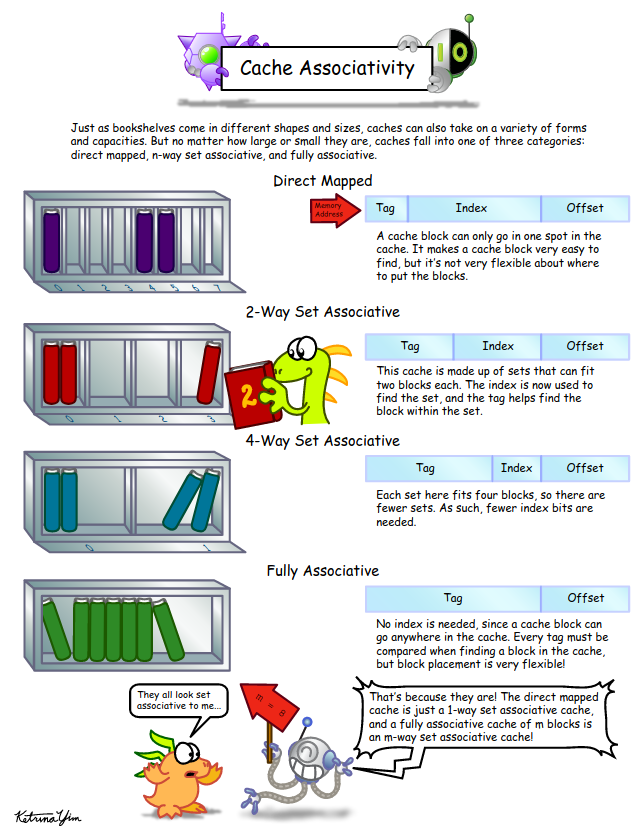
Direct Mapped cache (aka 1-way)
E = 1, multiple S. The cache can be framed as a (S*1) column matrix. good best-case time, but unpredictable in worst case.
Fully associative cache
E is multiple but S =1. The cache organization can be framed as (1*E) row matrix.
E-way associative cache/ Set-associative cache
When E is more than 1. A set-associative cache can be imagined as a (E*S) matrix. Eight-way set associative cache is common.
Writing

Metrics
- Miss Rate (%)
- Hit Time (cpu cycles); eg. 4clock cycle for L1
- Miss Penalty (cpu cycles) ; Total time for a
miss=hit time=+=miss penalty
Improving locality
Lots of doubts in Cache miss analysis
Spatial Locality
- Rearranging loops. Basically going from right-to-left, we want the leftmost item to be changing the fastest eg.
A[k][i][j], herejshould be changing the most if the nested loops involved are fori,=j=andk; so rearranging nested loops in the order ofk-i-jwill give the best spatial locality. - It implies that the elements physically located nearby have a good chance of being located close to each other. This principle is used in a process called “prefetch” that loads file contents ahead of time
See Memory Hierarchy See Matrix