tags : Python, Concurrency, Multiprocessing
FAQ
Can different approaches be used together
- Yes ofc.
- Eg. https://skipperkongen.dk/2016/09/09/easy-parallel-http-requests-with-python-and-asyncio/
- This uses asyncio and Threadpool executor together
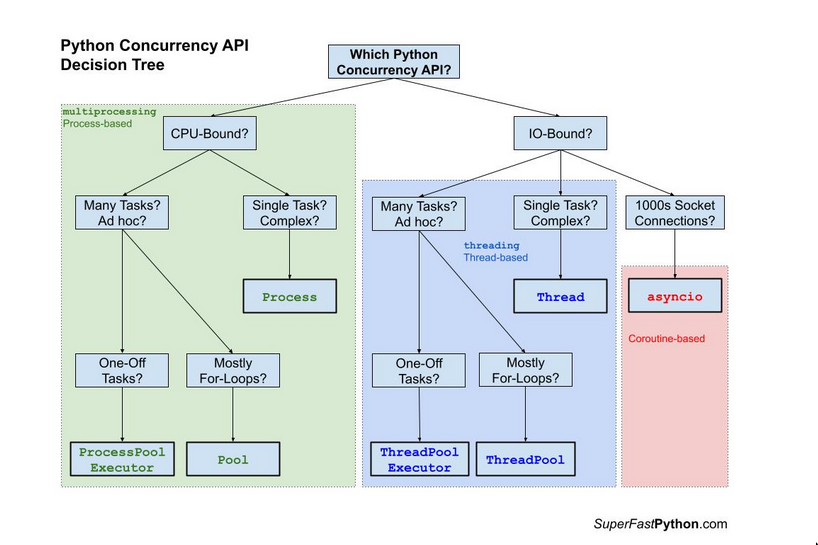
How to run python code on multiple processors?
multiprocessingmodule- This article is all about using
multiprocessingmodule to use all cpu cores. It’s true. - Since this is essentially multiple processes they can just run on multiple cores as per need etc.
- This article is all about using
threadingmodule- There’s some confusion around
threadingmodule only using one CPU - This is not entirely true
- It has to do with the GIL
- When we write Python code, we have no control over the GIL.
- But a built-in function or an extension(c/other lang) interfacing the Python/C API can “release the GIL”. In which case the operation that doesn’t need to use the python interpreter can fully use whatever OS allows it to.
- There’s some confusion around
asynciomodule- Things similar to
threading - Similar to threading module, if the operation itself(eg. I/O) operation doesn’t need the python interpreter that may go ahead and use what the OS allows it to
- Eg. if the app that pulls data from about 200 web api’s simultaneously using asyncio. While the python code is single threaded, the OS schedules the network driver code across all of the CPUs.
- Things similar to
When using threading, do I need to use a worker pool/threading pool?
- The pool is an object that will start, hold and manage x threads transparently for you.
WTF GIL?
The GIL is a lock held by the python interpreter process whenever bytecode is being executed unless it is explicitly released. I.e. the design of the cpython interpreter is to assume that whatever that occurs in the cpython process between bytecodes is dangerous and not thread-safe unless told otherwise by the programmer. This means that the lock is enabled by default and that it is periodically released as opposed to the paradigm often seen in many multi-threaded programs where locks are generally not held except when specifically required in so-called “critical sections” (parts of code which are not thread-safe).
- It can be considered as a mutex on the running python interpreter. It controls access to the python interpreter.
- It’s a thing about
CPython, if you use a different python interpreter(eg.Jython/IronPython). It also exists withPyPYinterpreter.- Multi-threading in cpython “time shares” the interpreter
Pros and Cons
-
Pros
- Provides useful safety guarantees for internal object and interpreter state.
- Allows only a
single OS threadto run the centralPython bytecode interpreter loop- In cases(other languages) where there’s no GIL, programmer would need to implement fine grained locks to prevent one thread from stomping on the state set by another thread
- When there’s the GIL in place, this extra work from the programmer is not needed
- If
T1is using the interpreter T2cannot access the interpreter and hence cannot access/mutate any shared state
- If
- Helps avoid deadlocks and other complications
-
Cons
- Restricts
parallel processing (CPU bound)of only pure python code. - GIL is a blocker for you if you want to do CPU bound work with the python interpreter. i.e Till the python code that does the CPU bound task is finished the thread will keep holding the lock(unless there’s a timeout etc.)
- see this thread for more info
- Restricts
GIL FAQ
- How does the GIL float around?
-
What does “releasing the GIL” mean? OR Why is the
threadingmodule even useful?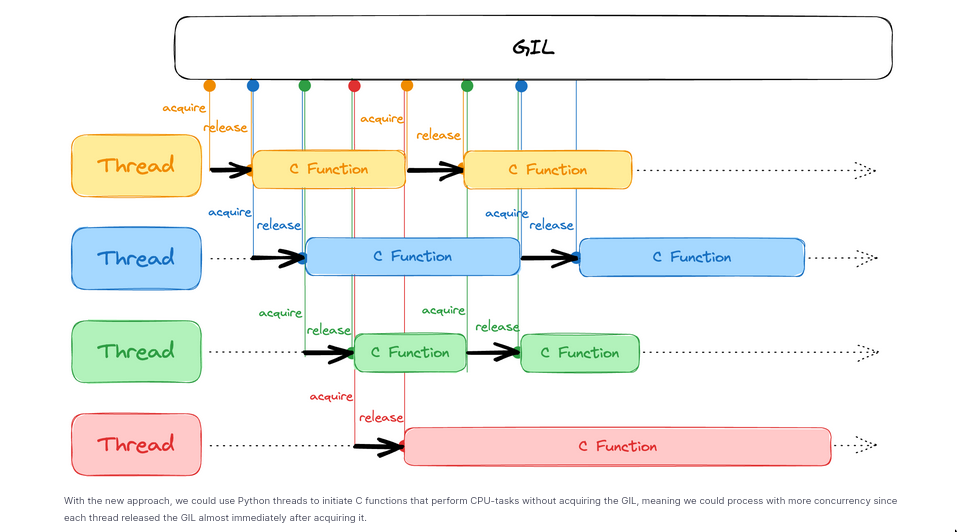
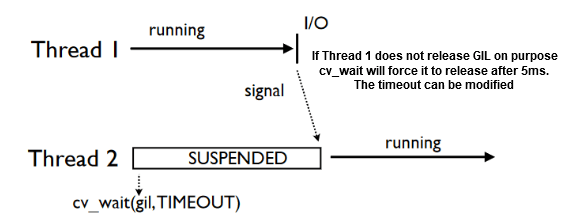
- “Release and Acquire the GIL” has to do with
some operationthat no longer needs the python interpreter its operation(eg. syscall) may release the GIL so that anything else which needs the python interpreter may use it.- Now the operation itself can use as may cores or whatever the OS allows it to do
- But the python interpreter is still running there on a single core, one OS thread thing. Which keeps on going like that. But its not as bad as it sounds, because we can do a lot of things by the “release & acquire GIL” thing
- Things that “release the GIL”
- Every Python standard library function that makes a syscall releases the GIL.
- This includes all functions that perform disk I/O, network I/O, and time.sleep().
- Eg. You can spin a thread that does network I/O. It’ll automatically release the GIL and main thread can go on do its thing.
- CPU-intensive functions in the NumPy/SciPy libraries
- compressing/decompressing functions from the zlib and bz2 modules, also release the GIL
- Eg. you could freely write a multithreaded prime number search program in Rust, and use it from Python
- Check
Py_BEGIN_ALLOW_THREADS
- Check
- “Release and Acquire the GIL” has to do with
Approaches
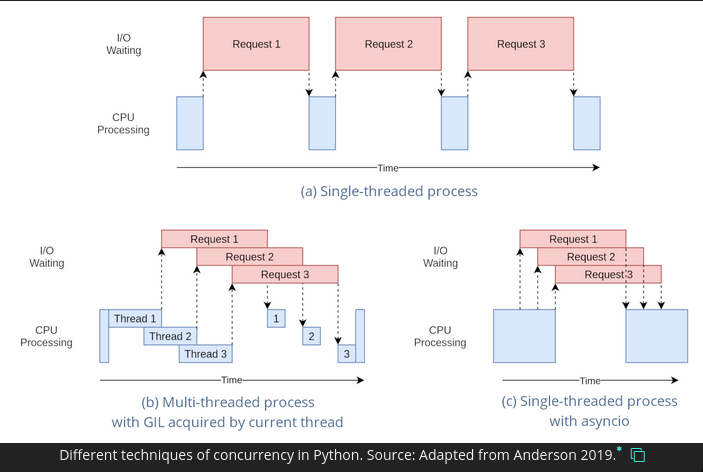
See this thread
| Name | GIL | Remark | Type |
|---|---|---|---|
| asyncio | doesn’t matter | More efficient than threads for certain kind of I/O ops | coroutine-based |
| threading | full matters | Useful most times when not doing python-only CPU bound tasks | thread-based |
| multiprocessing | doesn’t matter | Useful if doing python-only CPU bound tasks | process-based |
| subprocess | doesn’t matter | similar to multiprocessing but diffelant | |
| concurrent.futures | mixed | wrapper around threading and processing | mixed |
| vectorization | - | specialized |
Asyncio
- There’s a lot of criticism around asyncio. Must use with caution.
- The criticism is specifically around asyncio module not asynchronous programming using coroutines in general
- Some people suggest alternative libraries like gevent offer a better api etc. Again, need to do my own research.
How it runs
- asyncio runs in a single thread(the event queue runs in only a single thread). It only uses the main thread.
- Concurrency is achieved through cooperative multitasking by using Python generators
- See Coroutines (See the blocking and non-blocking section)
AsyncIO and CPU bound tasks
- asyncio is useful when you’re doing practically zero processing on your data.
- Designed for when there is some external process triggering events - like a user interactive with a UI, or incoming web requests.
- AsyncIO helps with I/O bound things, for CPU bound things we still would need to resort to multiprocessing or similar things.
- If what’s being run by
asynciois pure-python cpu-bound, and if we don’t pause it manually, other stuff to be run by the loop will be waiting. Eg. If the web-request takes 2 second cpu-time, then even if its usingasyncioit’ll be waiting and ultimately the server will be slow as entire event loop runs in a single thread. This is not a problem when the operations are not CPU bound.
Comparisons

-
AsyncIO vs Threads
- It eliminating the downside of thread overload and allowing for considerably more connections to run at the same time. (Even though a lot of threads is not really a problem (in most cases))
- When you use
threads, you would have 50 threads spawned, each waiting on read() for a socket- But with
asyncioyou can then have an arbitrarily huge number of sockets open while not having to build up an OS-level thread for each - This saves us a lot of resources that threads may consume, such as memory, spawn time, context-switching, (GIL release, acquire time) etc.
- But with
- The race between threads and asyncio then becomes who can context-switch more efficiently.
- The efficiency in being able to context switch between different IO-bound tasks, which are not impacted by the GIL in any case.
-
AsyncIO vs concurrent.futures
concurrent.futurespre-datesasyncio- What
concurrent.futuresis to threads and processes is whatasyncio.futureis to asyncio - You can run asyncio tasks in a
concurrent.futures.Executor
Asyncio alternatives
- We have the python provided event loop, that’s asyncio
- crio
- trio
- gevent
- gevent transforms all the blocking calls in your application into non-blocking calls that yield control back to the event loop
- What the heck is gevent? (Part 1 of 4) | by Roy Williams | Lyft Engineering
- Asyncio, twisted, tornado, gevent walk into a bar | Hacker News
Usage
without asyncio
import time
def sleepy_function():
print("Before sleeping.")
time.sleep(1)
print("After sleeping.")
def main():
for _ in range(3):
sleepy_function()
main()with asyncio
import asyncio
async def sleepy_function():
print("Before sleeping.")
await asyncio.sleep(1)
print("After sleeping.")
async def main():
await asyncio.gather(*[sleepy_function() for _ in range(3)])
asyncio.run(main())- As can be seen in the above example, to use asyncio we had to transform/color almost the entirety of the program
- When you use
asynciomodule every function thatawaitfor something should be defined as async - Any synchronous call within your async functions will block the event loop
- Code that runs in the asyncio event loop must not block - all blocking calls must be replaced with non-blocking versions that yield control to the event loop. So you have to find alternative libraries in cases if the library at use is blocking.
- i.e libraries like psycopg2, requests will not work directly
- You can however use
BaseEventLoop.run_in_executorto run blocking libraries with asyncio. There’s alsoto_thread
- See Coroutines for more info on this
- When you use
-
Main ideas
- Coroutine is defined using the keyword
async - Just calling the coroutine will not work
- We need to use asyncio to run it:
asyncio.run asyncio.runis the event loop.
- We need to use asyncio to run it:
awaitkeyword signals asyncio that we want to wait for some event, and that it can execute other stuff- We can use
awaitfor anAwaitable. coroutines~(functions with ~asynckeyword),taskandfuturesare examples ofAwaitable
- We can use
taskare created withasyncio.create_task- We can think of
taskas a coroutine that executes in the background. Helps make things faster. - Instead of using
create_task+awaitcombo, we can simply useTaskGroupfor more ez API.TaskGroupalso helps with error handling.
- We can think of
- Coroutine is defined using the keyword
-
Plain coroutines vs coroutine+create_task
# takes 3s async def say_after(delay, what): await asyncio.sleep(delay) print(what) async def main(): print(f"started at {time.strftime('%X')}") await say_after(1, 'hello') await say_after(2, 'world') print(f"finished at {time.strftime('%X')}") asyncio.run(main())vs
# takes 1s async def main(): task1 = asyncio.create_task( say_after(1, 'hello')) task2 = asyncio.create_task( say_after(2, 'world')) print(f"started at {time.strftime('%X')}") # Wait until both tasks are completed (should take # around 2 seconds.) await task1 await task2 print(f"finished at {time.strftime('%X')}")- The second example here is 1s faster because the
tasksare executed in background, while in the first example weawaittill the completion of the coroutine.
- The second example here is 1s faster because the
Example
- “Writes to sqlite are then sent to that thread via a queue, using an open source library called Janus which provides a queue that can bridge the gap between the asyncio and threaded Python worlds.”
- https://github.com/aio-libs/janus
Threads
See Threads
Daemon and non-daemon threads
# non-daemon, no join.
# prints yoyo, prints server start, waits
# main thread finished, thread runnig
t = threading.Thread(target=serve, args=[port])
t.start()
print("yoyo")
# non-daemon, join.
# prints server start, waits.
# main thread waiting, thread running
t = threading.Thread(target=serve, args=[port])
t.start()
t.join()
print("yoyo")
# daemon, no join.
# prints server start, prints yoyo, quits.
# thread runs, main runs and finished, both exit
t = threading.Thread(target=serve, args=[port])
t.daemon = True
t.start()
print("yoyo")- Non-daemon threads
- Expected to complete their execution before the main program exits.
- This is usually achieved by waiting for the thread using
joinin the main thread - Using
joinis not mandatory,joinis only needed for synchronization. Eg. the correctness of the program depends on the thread completing its execution and then we go on with the main thread. Withoutjoin, we’ll spin the thread and it’ll keep running and then we’ll continue running the main thread aswell.
- Daemon threads
- Abruptly terminated when the main program exits, regardless of whether they have completed their tasks or not.
- It’s just a flag on a normal thread
- You can actually call
.joinon daemon threads, but it’s generally considered to be not good practice.
Processes
- This is using the multiprocessing library which is literally just using multiple processes.
- Effectively side-stepping the Global Interpreter Lock by using subprocesses instead of threads.
- Now each process gets its own GIL
- Take care of
if __name__ == "__main__"when usingmultiprocessing - State sharing etc becomes harder because its different processes
concurrent.futures
- This is more like wrappers around threads and multiprocess support in python.
- The ergonomics seems to be better than using threads and multiprocessing directly
components
Executor- submit
- shutdown
mapmapis not super flexible with error handling- If usecase requires error handling, better use
submitwithas_completed(See official example)
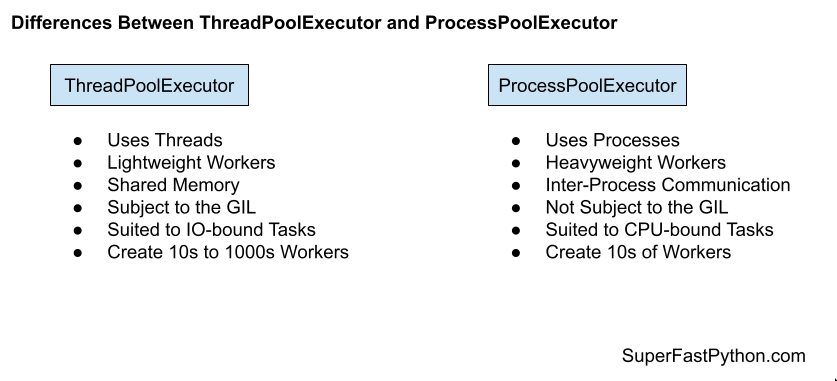
ThreadPoolExecutor(Subclass of Executor)- Based on
threads
- Based on
ProcessPoolExecutor(Subclass of Executor)- Based on
multiprocessing
- Based on
ThreadPoolExecutor
-
Waiting
- as_completed vs
wait- Use
as_completed()to get results for tasks as they complete.as_completed()function does NOT let you process tasks in the order that they were submitted to the thread pool. For that usemap
- Use
wait()to wait for one or all tasks to complete.
- Use
- as_completed vs
-
Error handling
# TODO: Issue is this is only ever being run after all of the fetches which # is sequential, we need a thread safe variable to indicate failure to the # main thread now # NOTE: We want to fail the entire fetch pipeline if we get any exception, # this is done because of the nature of the data, half of the data is # not useful to us # TODO: In the ideal case, len(done) will be 1, but if in any case, wait # itself is called after the fist exception len(done) will not be 1 done, _ = futures.wait(worker_updates, return_when=futures.FIRST_EXCEPTION) # if len(done) == 1: # maybe_exception = done.pop() # if maybe_exception.exception(): # # shutdown pool and can all futures # # NOTE: We don't need to separately use cancel() here # executor.shutdown(wait=True, cancel_futures=True) # # NOTE: Cancelling non-running jobs is enough for our usecase, # # running workers will run till completion or not. we don't # # have to use threading.Event to write custom logic to stop # # already running jobs when this exception occurs based on how # # our jobs tables are structured. # # NOTE: We could however do it just so that we don't un-nessarily # # push to s3 but it'll need our code to handle a threadsafe # # event variable now and do not want to do that atm # # re-raise exception so that whatever's executing the process is # # notified of it. For some reason calling result() was not raisnig # # the error as expected # raise maybe_exception.exception() # NOTE: we can do the len(done) == 1 thing, but by the we might have other exception in the list by the time that returns. So we could have something like the following as-well. for task in done: if task.exception(): executor.shutdown(wait=True, cancel_futures=True) L.error("ocr", ad_id=worker_updates[task]) raise task.exception()
-
Resources
- 6 Usage Patterns for the ThreadPoolExecutor in Python - Super Fast Python
- 4 ThreadPoolExecutor Common Errors in Python - Super Fast Python
- How to Handle Exceptions With the ThreadPoolExecutor in Python - Super Fast Python
- How to Stop All Tasks if One Task Fails in the ThreadPoolExecutor in Python - Super Fast Python
- How to Shutdown the ThreadPoolExecutor in Python - Super Fast Python
- How to Cancel Tasks with the ThreadPoolExecutor in Python - Super Fast Python
queue
Vectorization
- See The limits of Python vectorization as a performance technique
- SIMD in Pure Python | Blog
- In order for vectorization to work, you need low-level machine code both driving the loop over your data, and running the actual operation. Switching back to Python loops and functionality loses that speed.
Reading links
Signal Handling, and Threads in Python
Meta info
- The handling of signals is different for os to os
- A Python signal handler does not get executed inside the low-level (C) signal handler.
- Python signal handlers are
always executed in the main Python threadof the main interpreter, even if the signal was received in another thread.- This means that signals can’t be used as a means of inter-thread communication. You can use the synchronization primitives from the threading module instead.
- Only the main thread of the main interpreter is allowed to set a new signal handler.
- Things are never super safe: Most notably, a KeyboardInterrupt may appear at any point during execution. Most Python code, including the standard library, cannot be made robust against this, and so a KeyboardInterrupt (or any other exception resulting from a signal handler) may on rare occasions put the program in an unexpected state.
writing Signal handlers
sys.exit vs os._exit
sys.exitvsos._exit:sys.exitonly throws an exception and aborts the current thread rather than the whole process.os._exitis usually bad, no finally blocks, bufferi/o ops may not be complete etc.
Default signal handlers (see SIG_DFL)
-
SIGINT
SIGINTis translated into aKeyboardInterruptexception if the parent process has not changed it.- from: https://blog.miguelgrinberg.com/post/how-to-kill-a-python-thread
- Instead of using a signal handler, in many cases we could also catch and do something with the
KeyboardInterruptexception but it depends on the scenario.- Also
except Exception:doesn’t catchKeyboardInterrupt
- Also
-
SIGTERM
- python does not register a handler for the SIGTERM signal.
- That means that the system will take the default action. On linux, the default action (according to the signal man page) for a SIGTERM is to terminate the process.
- SIGKILL
Python Threads and Signals
Handling Ctrl+C
“In the above run, I pressed Ctrl-C when the application reached the 7th iteration. At this point the main thread of the application raised the KeyboardInterrupt exception and wanted to exit, but the background thread did not comply and kept running. At the 13th iteration I pressed Ctrl-C a second time, and this time the application did exit”
My current preference is like the following if using ThreadPoolExecutor:
# in the main thread
def exit_thread(executor):
L.info("shutting down. waiting for in-flight threads to complete")
# NOTE: wait=False returns immediately but running thread runs till completion
# NOTE: there's some undefined(bug?) with ThreadPoolExecutor.submit
# when submitting 21M items. Signal handler using
# executor.shutdown goes into some kind of a lock. But its
# works as-expected once items are submitted. And
# SIGTERM/SIGKILL etc will always work as expected.
executor.shutdown(wait=False, cancel_futures=True)
# reset the handler so that normal handling continues so that we don't get the log everytime we hit ctrl+c
signal.signal(signal.SIGINT, signal.getsignal(signal.SIGINT))
sys.exit(0) # exiting main thread, if worker thread raises, it'll not be caught
signal.signal(signal.SIGINT, lambda s, f: exit_thread(executor))How to kill a running python thread?
- You can’t.
- In case of
features, if we usecancel, “If the call is currently being executed or finished running and cannot be cancelled then the method will returnFalse” (see this) - References
Case of ThreadPoolExecutor
ThreadPoolExecutoris super nice but it’s not suitable for long running tasks.- All threads enqueued to ThreadPoolExecutor will be joined before the interpreter can exit.
- So in-essence, these are more akin to
non-daemonthreads.
What are the workarounds if I can’t kill a thread?
-
Thread where main thing is a core loop
- Use
Eventto signal further processing andreturn
- Use
-
Thread where main thing is a NOT core loop (Eg. long running I/O operation)
- Two Ctrl+C: “The wait mechanism that Python uses during exit has a provision to abort when a second interrupt signal is received. This is why a second Ctrl-C ends the process immediately.” (could not find a proper source)
- Handle SIGINT and
os._exit - set
daemon=True, this will kill the thread if main thread gets an interrup but no cleanup will be done!