tags : Concurrency, Golang
100% chances of things being wrong here.
Go concurrency tips
Detecting data races
- If two goroutines try to modify a shared variable, we have a race condition.
- go has a built-in data race detector which can help us detect it. See Race Detector.
Runtime and Scheduler other parts
Go runtime creates OS threads. The Go scheduler schedules goroutines on top of these OS threads.
Go runtime
Go scheduler
- Watch: Dmitry Vyukov — Go scheduler
Initial attempts
- 1:1 threading: 1 goroutine. To expensive. syscalls, memory, no infinite stacks.
- Thread pools: faster goroutine creation. But more memory consumption, performance issues, no infinite stacks.
M:N threading
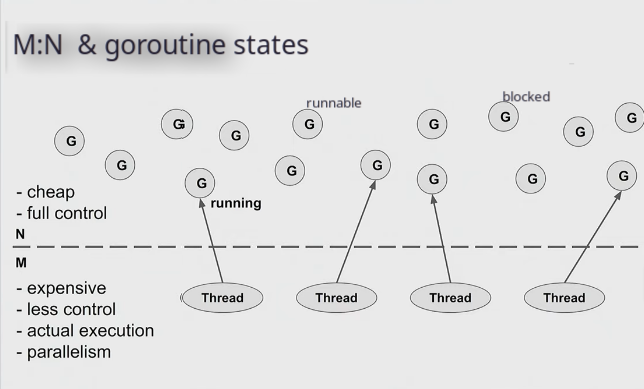
- We multiplex goroutines on the threads
- If we have 4 OS threads, they can run 4 goroutines at the same time
M:N Scheduler
-
Because OS doesn’t know anything about our goroutines, we need to come up w our own scheduler
-
We need to keep track of
- Run Queue: Runnable Goroutines
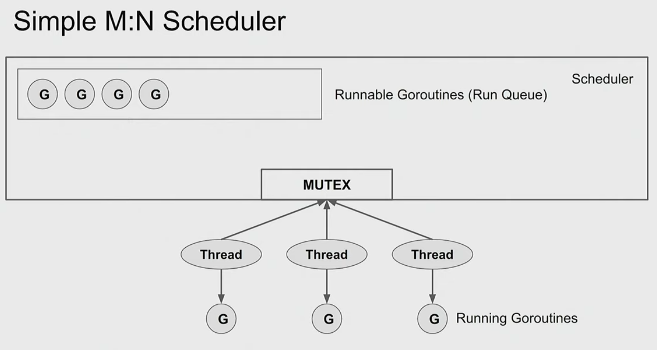
- Run Queue: Runnable Goroutines
-
We don’t need to keep track of Blocked goroutines as channels have their own wait queue. When we unblock a goroutine, it’s moved to the scheduler run queue.
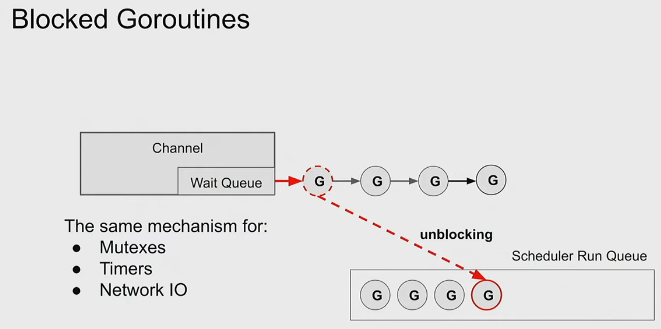
-
Syscalls
- When a goroutine does a syscall, and things go into the kernel we have lost control over the goroutine. We’ll only know if it returns back.
- If all threads are doing syscalls, then we can’t even schedule new stuff now. And if one of a runnable goroutine holds the lock, we have a artificial deadlock. This issue is common for any scheduler w fixed number of threads.
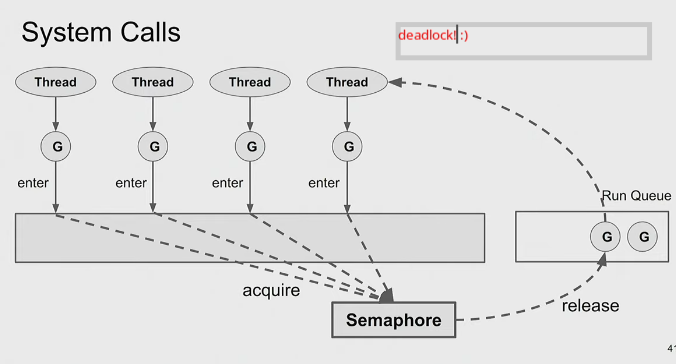
- Solution to this, in the last thread, it’ll start another os thread, which will start re-flow of the runqueue
- If we have 5 threads, we only want to run 4
Distributed M:N Scheduler
- M:N Scheduler doesn’t scale as multiple threads try to access just one mutex
- So we give each thread its own M:N scheduler
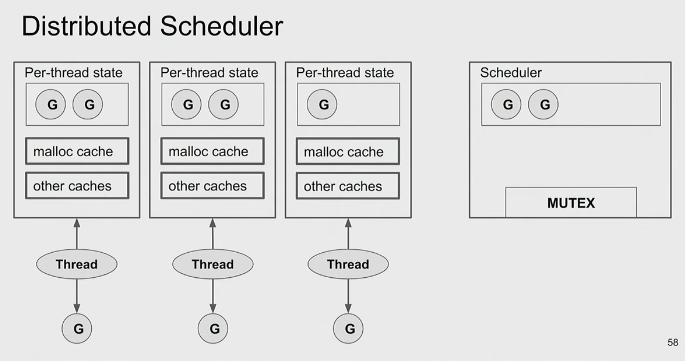
- Which distributed scheduler, we now have the problem of having an unified view of the Run Queue.
- Local run-queue ⇒ Global run-queue ⇒ Steal work of other schedulers
- So we also got some load balancing now
- This still not enough because checking for work stealing involves syscalls and now each thread needs to syscalls and will result in cpu being busy for nothing.
Go Processor M:P:N
- P:
GOMAXPROCSenv var go_processor: A artificial resource required to run Go code. No. ofgo_processorobjects == cores.- If goroutine is executing syscall, it does not need a
go_processor, it’s only needed for goroutines running go code.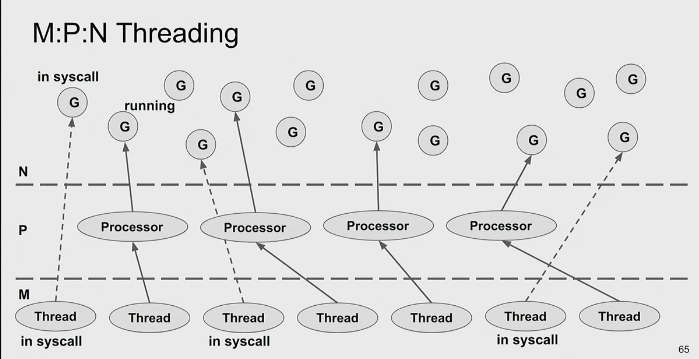
- With this, threads only need to check fixed number of
go_processor. So work stealing becomes scalable.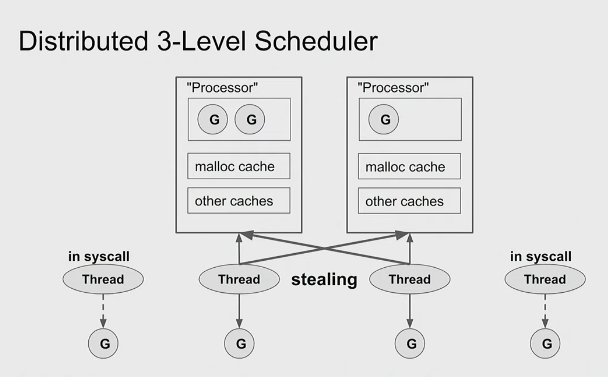
Go GC
Concurrency in go, what are my options/primitives?
- There are no Threads. But we have some sort of Coroutines + Green Threads combination. They’re called
goroutines. You probably will interact with os threads w cgo ig.
Communication
- Shared state: Atomics, Mutex and friends
- Message passing: channels
Synchronizations
- You can always use shared state for synchronization. Can also go lockfree maybe.
- Channels too can be used for synchronization, as reading from channel is a blocking call.
When to use what?
Some general guidelines
- Understand what data structure you’re working w. Eg. Go Maps are not goroutine-safe, you need to use a RWMutex if you use it to share data across goroutines.
- Try avoiding shared state, if cannot avoid, deal things at max w one mutex.
- If you take a lock in your function, and call something else that takes a lock, that’s two locks. If you need two locks might aswell switch to channels. (Not my words, I don’t even understand this deeply but sounds wise, have to think more why this is the way it is)
goroutines
gokeyword is the only api for goroutines- Users can’t specify stack size for goroutines.
- When a go-routine
- sleeps/blocked: underlying thread can be used by another go-routine.
- wakes up: It might be on a different thread.
- Go handles all this behind the scenes.
Benefits over kernel threads
- w M:N scheduling & channels, we get efficiency due low overhead in context switching.
- Lower memory allocation per go routine vs os threads
goroutine-safe/thread-safe data structure(X)?
- See Goroutine-safe vs Thread-safe
- See Threads
goroutine-safeis not well-established term. Whilethread-safeis, and it means safe for concurrent access.- You can freely substitute “thread-safe” with “goroutine-safe” in Go docs, unless documentation very explicitly refers to actual threads
- Here
Xcan be some data structure. - If
Xcan be accessed by multiple goroutines without causing any conflict, we can sayXis goroutine safe.Xitself manages the data and ensures the safety of concurrent access. - Eg. Go’s
channelare a goroutine-safe FIFO object.
Channel
- Channel is a queue(FIFO) with a lock. It’s goroutine safe.
- Multiple writers/readers can use a single channel without a mutex/lock safely.
- When we get a channel, we essentially get a
pointerto thechannel. - Good to pass a channel as a parameter. (You have control over the channel)
- Closing channels
- Closing channels is not necessary, only necessary if the receiver must know about it. Eg
rangeon the channel. - Always close channels from sending side.
- Closing channels is not necessary, only necessary if the receiver must know about it. Eg
Implementation
- Defined by the
hchanstruct, at runtime this is allocated on theheap. - Enqueue and Dequeue are “memory copy”. This gives us memory safety. Because, no shared memory except the
hchanandhchanis protected by its lock.
Buffered & Unbuffered
The difference between a buffered and unbuffered channel is only in how the channel is initialized, not in how it is declared in the struct.
Unbuffered (Synchronous)
ch := make(chan int)
ch := make(chan int, 0) // same as above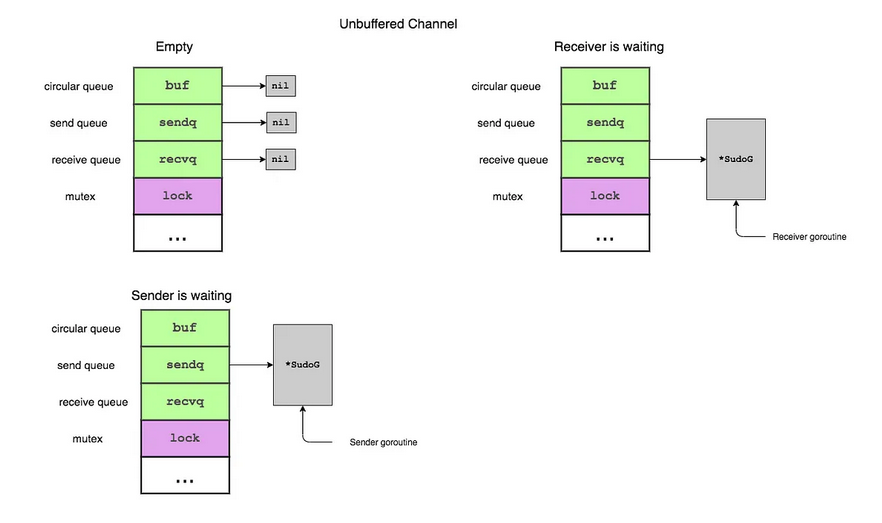
- Combines communication w synchronization
Buffered (Asynchronous)
ch := make(chan int, 3)
// ch := make(chan int, x>0)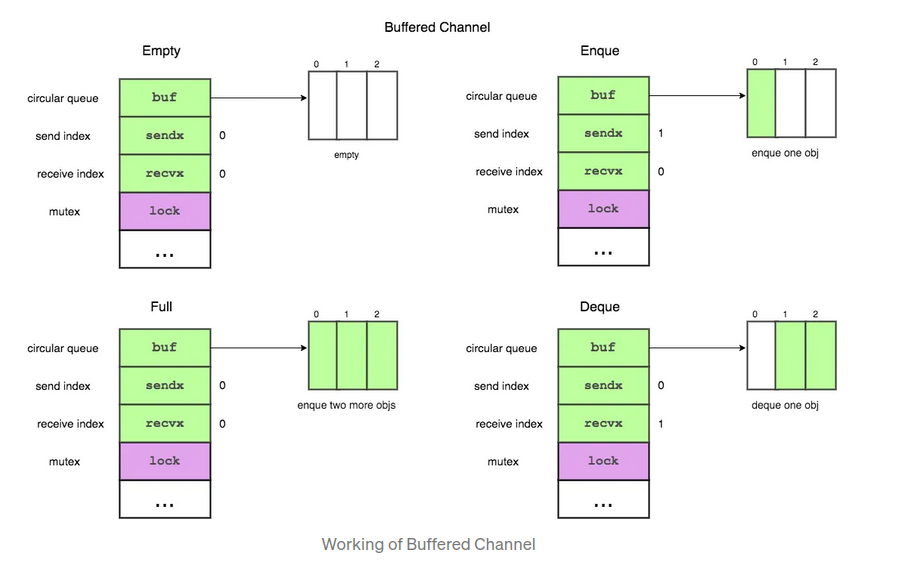
- Don’t use buffer channels unless you’re sure you need to
- Can be used as a semaphor, eg. limit throughput in a webserver
- if we want the producer to be able to make more than one piece of Work at a time, then we may consider buffered
Blocking in buffered and unbuffered
func main() {
ch := make(chan int, 1)
ch <- 32 // if unbuf, things will not move post this! deadlock.
// ch <- 88 // this will block an buf(1) ch! (channel full)
<-ch // if unbuf, this must be called from another goroutine
fmt.Println("Hello, 世界")
}- Buffered
- S: Until the receiver has received the value
- R: Blocks if nothing to receive
- Unbuffered
- S: Blocks when the buffer is full, something must receive now.
- R: Blocks if empty buffer
Send and receive channels
TransactionChan() <-chan message.TransactionThis declares a function that returns a receive-only channel of message.Transaction. You can only receive values FROM this channel, not send TO it.
select and ctx.Done() & Handling multiple channels
When in a for loop:
selectstatement just selects a case that can proceed (and runs it), and then it endsselectdoes NOT run and listen for the differentcasesin parallel.- when multiple ready channels
selectpicks one at random. There’s no oderding.- If a
caseis chosen andselectis under aforloop, the particularcasehas to finish, only then we get back toforloop and the selection happens again. For this reason, we want the time spent under eachcaseto be very minimal.
- i.e If we trying to empulate something like parallel execution, we probably need to use some managed goroutine thingy like errgroup etc.
select, this is similar to unixselect(2), hence the name.- It’s often used inside an infinite loop (say, in a consumer) to grab data from any available channel.
- chooses one at random if multiple are ready. If one “case” is chosen, others are not picked for that iteration.
- waiting on
ctx.Done()is same as any other channel, if we want to have some priority w it we might use this trick. This way done channel is always checked. There’s also: https://stackoverflow.com/questions/46200343/force-priority-of-go-select-statementfor { select { case <-ctx.Done(): return ctx.Err() default: // Now use a non-blocking select for other operations select { case <-ctx.Done(): return ctx.Err() case v := <-ch1: // Handle ch1 case v := <-ch2: // Handle ch2 default: // Optional: do some non-blocking work } } }
select vs select loop
selectcan be run without a loop but often can be seen inside a boundedforloop or unboundedfor {}loop- We’re talking about the select loop here, you are waiting on one of two things to happen:
- Await the closing of the channel returned by Done(): This happens only when there’s a timeout or the context is cancelled.
- select statement just selects a case that can proceed (and runs it), and then it ends, it doesn’t do anything else you are “trying again” with your for
Example of an issue (see explanation)
// NOTE: My assumptions here is wrong, see explanation
package main
import (
"context"
"fmt"
"time"
)
func worker(a, b chan struct{}, ctx context.Context) error {
for {
select {
case <-ctx.Done():
fmt.Println("cancelled")
return nil
case <-a:
fmt.Println("running A")
time.Sleep(4 * time.Second)
fmt.Println("sleep A finish")
case <-b:
fmt.Println("running B")
time.Sleep(2 * time.Second)
}
}
}
func main() {
a := make(chan struct{})
b := make(chan struct{})
ctx := context.Background()
// USECASE #1
// this ends immediately after printing running A
ctx, can := context.WithCancel(ctx)
go worker(a, b, ctx)
a <- struct{}{}
fmt.Println("cancelling") // this does NOT wait till A finishes and cancel is done immediately
can()
// USECASE #2
// following waits till A sleep and wakes up and then only triggers B
go worker(a, b, ctx)
a <- struct{}{}
fmt.Println("launching b") // this will keep waiting till A finishes
b <- struct{}{}
}-
Explanation
But it seems like select waits till the current case completes and then picks one at random etc etc. not quite, a select statement just selects a case that can proceed (and runs it), and then it ends, it doesn’t do anything else you are “trying again” with your for
So I wanted to understand why ctx.Done behaves differently under select it doesn’t, it’s just a channel, there is no special behaviour
when main returns the program exits, regardless of how many goroutines are still running that is the issue with your playground (edited) NEW [7:41 AM]zhayes: additionally, calling cancel doesn’t wait for anything, if you want to wait for the cancelled goroutine to exit, you need to do that yourself
Guarantees
- Channels should not be passed as pointers, they’re alreay internally impplemented as pointers(reference types like maps)
chatgpt
Go’s channel implementation ensures that each item sent on a channel is received by exactly one receiver. This is a fundamental property of Go channels, whether buffered or unbuffered.
How It Works:
When a goroutine tries to receive from a channel, it is blocked until data is available. Once data is sent on the channel, exactly one of the waiting goroutines will be unblocked to receive that data. The runtime handles the synchronization and ensures no duplication.
Resources
- The Behavior Of Channels
- Share memory by communicating · The Ethically-Trained Programmer
- Internals of Go Channels. Inner workings of Go channels
- https://dave.cheney.net/2013/04/30/curious-channels
- https://dave.cheney.net/2014/03/19/channel-axioms
- https://www.dolthub.com/blog/2024-06-21-channel-three-ways/
More resources
- Synchronization Constructs in the Go Standard Library | Lobsters 🌟
- Go Memory Management – Povilas Versockas
- Visualizing memory management in Golang | Technorage
- https://github.com/plagioriginal/concurrency-in-go
- Threads and Goroutines | Lobsters
- Notes on structured concurrency, or: Go statement considered harmful — njs blog